Apertus POC for Swiss CTOs
What the engagement actually delivers
Scoped task set definition
We start by locking down which workloads enter the POC — extraction, document Q&A, summarization in DE/FR/IT, classification, light agentic flows. The task set is signed off before any model runs, so the engagement does not drift into a generic Apertus demo. The bar for each task is agreed in writing.
Custom eval set design
The eval set is built against your real records, not a public benchmark. We sample from your supplier sheets, contracts, master data or ticket history under NDA, label a graded subset with your domain reviewers, and freeze it as the contract for the apertus evaluation poc. The set stays yours after the engagement.
Side-by-side vs your incumbent
Apertus 8B or 70B runs against the same eval set as your current GPT-4o, Claude or Gemini deployment, in one harness. Quality, latency and cost per task type land in a single comparison table, so the apertus benchmark output is one document the steering committee can actually read in a meeting.
Running prototype, not a slide deck
At the end of the engagement Apertus is serving inference on a real endpoint — vLLM or TGI on a sandbox cluster, exposed through the same Laravel and Next.js spine we use in production. Your team can hit it, point your existing client at it, and feel the latency on Swiss-resident infrastructure.
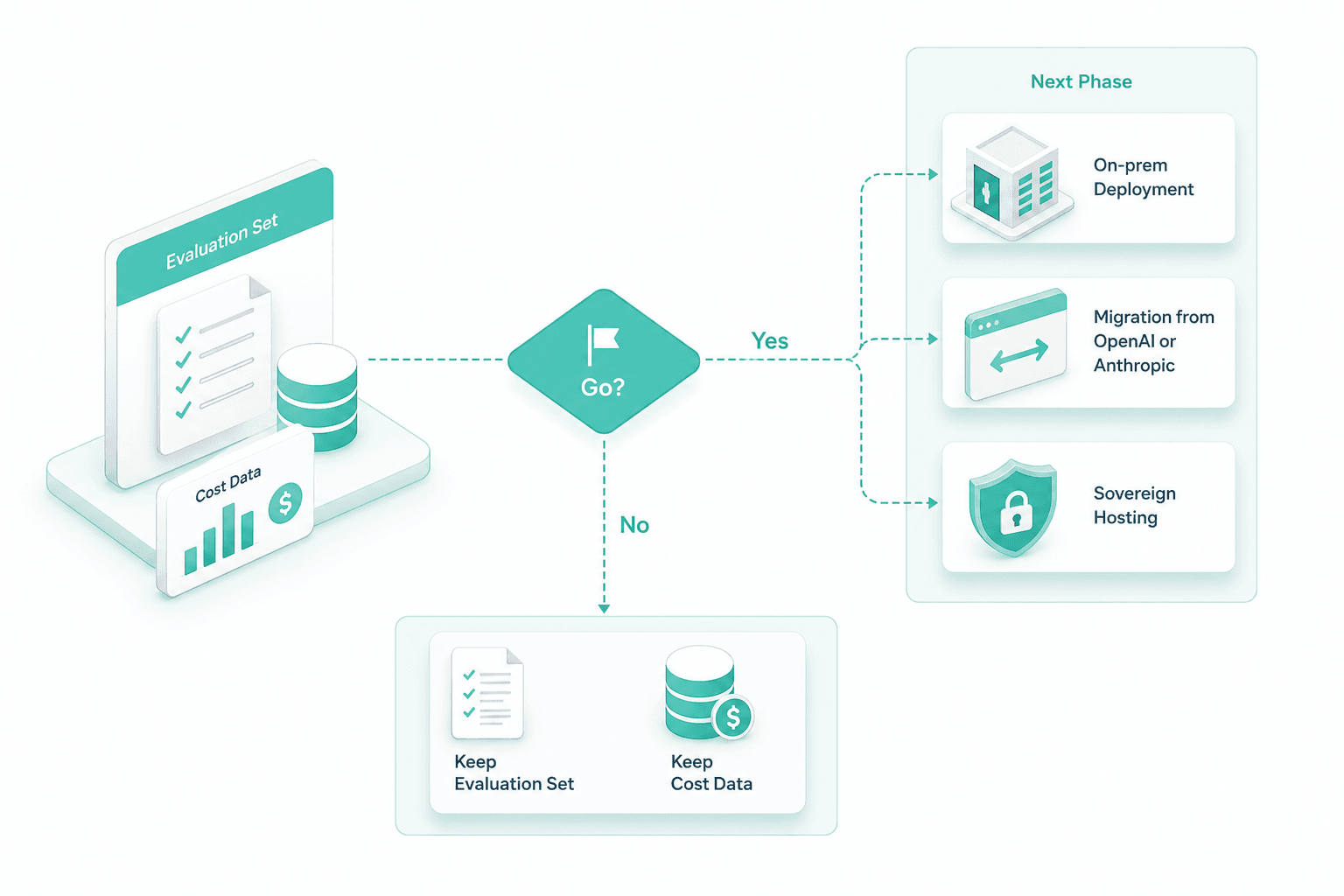
Go/no-go recommendation document
The closing artefact is a recommendation: go to production on Apertus, stay on the incumbent, or split the workload by task type. The document carries the eval table, the cost model, the risk notes and the deployment shape we would build next. It is written so a non-engineering board can act on it.
Eval set handover to production
If the call is go, the eval set carries straight into the production phase — the same numbered tests gate every release of the on-prem deployment or the migration. Nothing is rebuilt from scratch; the apertus poc deliverables become the acceptance contract for what gets shipped next.
How we run an Apertus POC
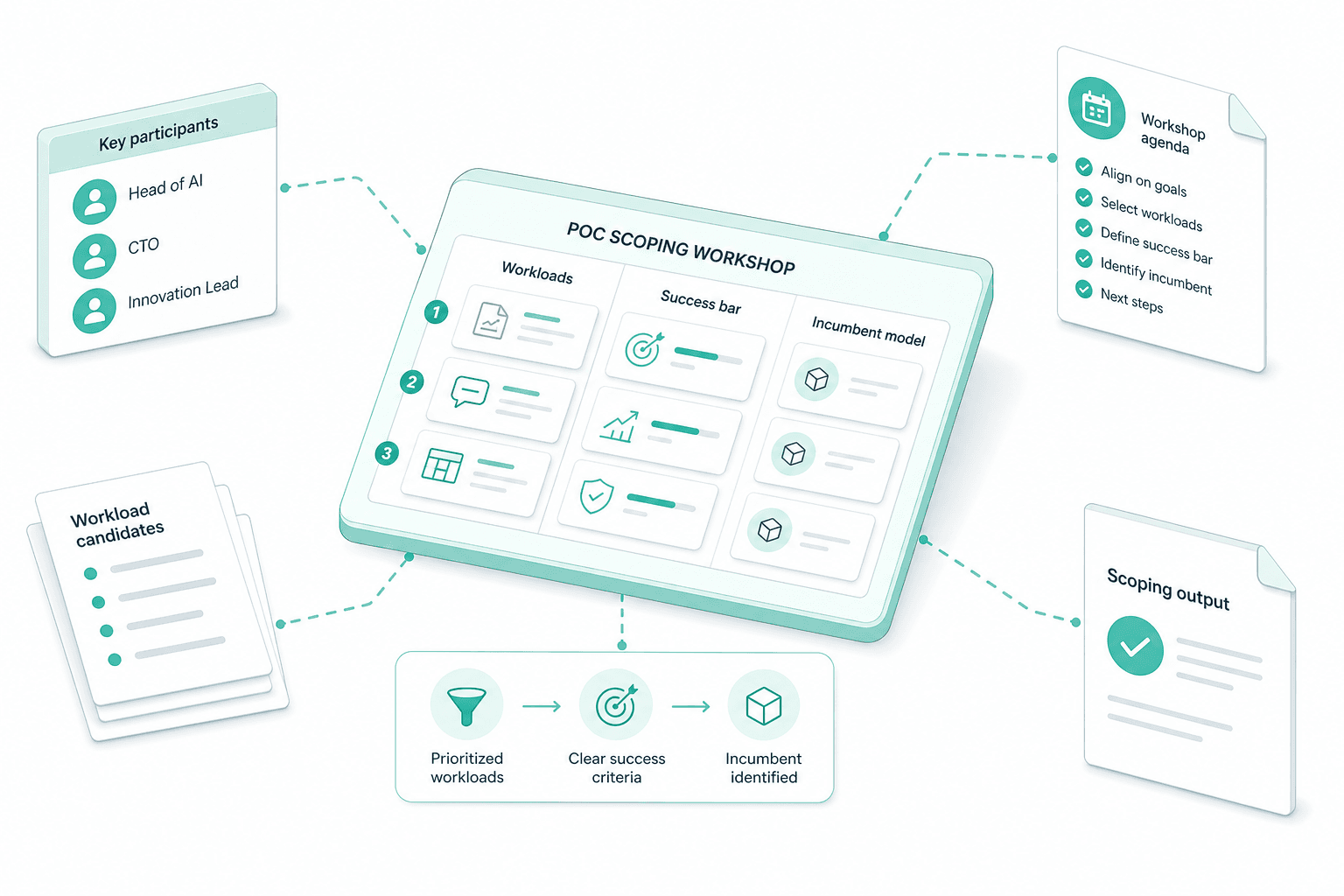
Scoping workshop
We run a structured workshop with your Head of AI, CTO or innovation lead to decide which workloads enter the POC, what the success bar is for each, and which incumbent model is being challenged.
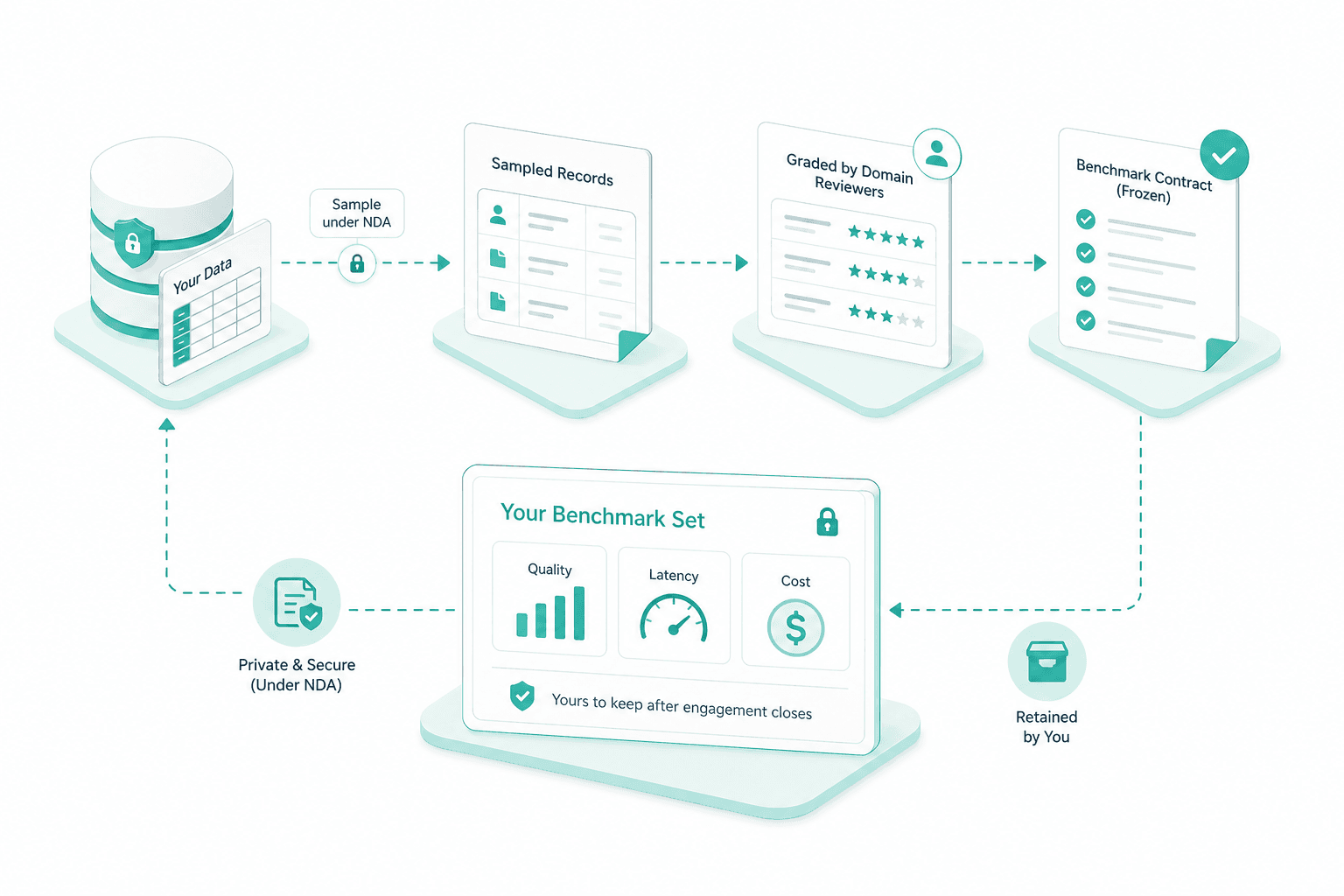
Eval set design
We sample your real records under NDA, label a graded subset with your domain reviewers, and freeze it as the benchmark contract. The set covers quality, latency and cost, and stays yours to keep after the engagement closes.
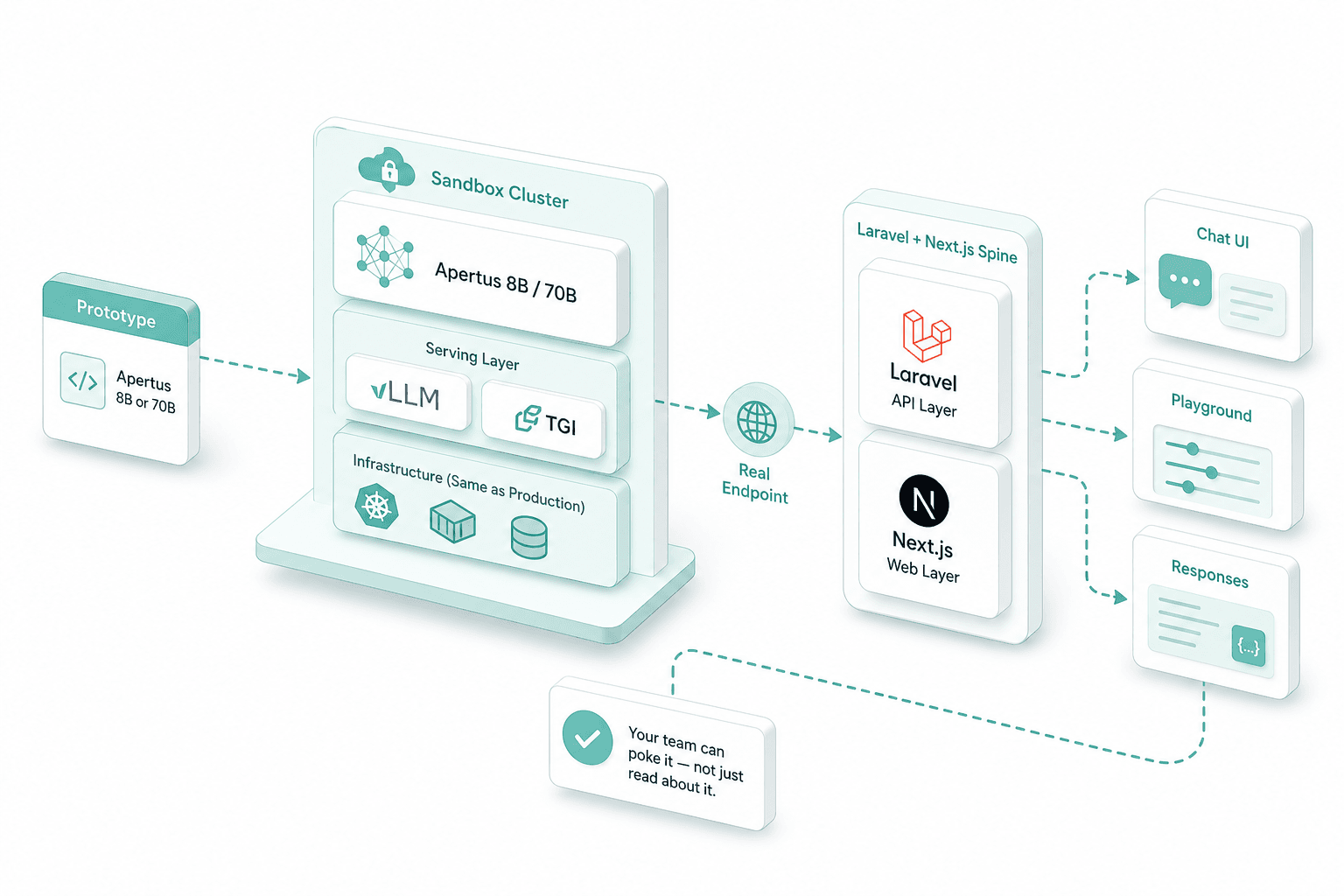
Prototype build
Apertus 8B or 70B is served on a sandbox cluster — vLLM or TGI, the same stack we run in production. The prototype hits a real endpoint through the Laravel and Next.js spine, so your team can poke it and not just read about it.
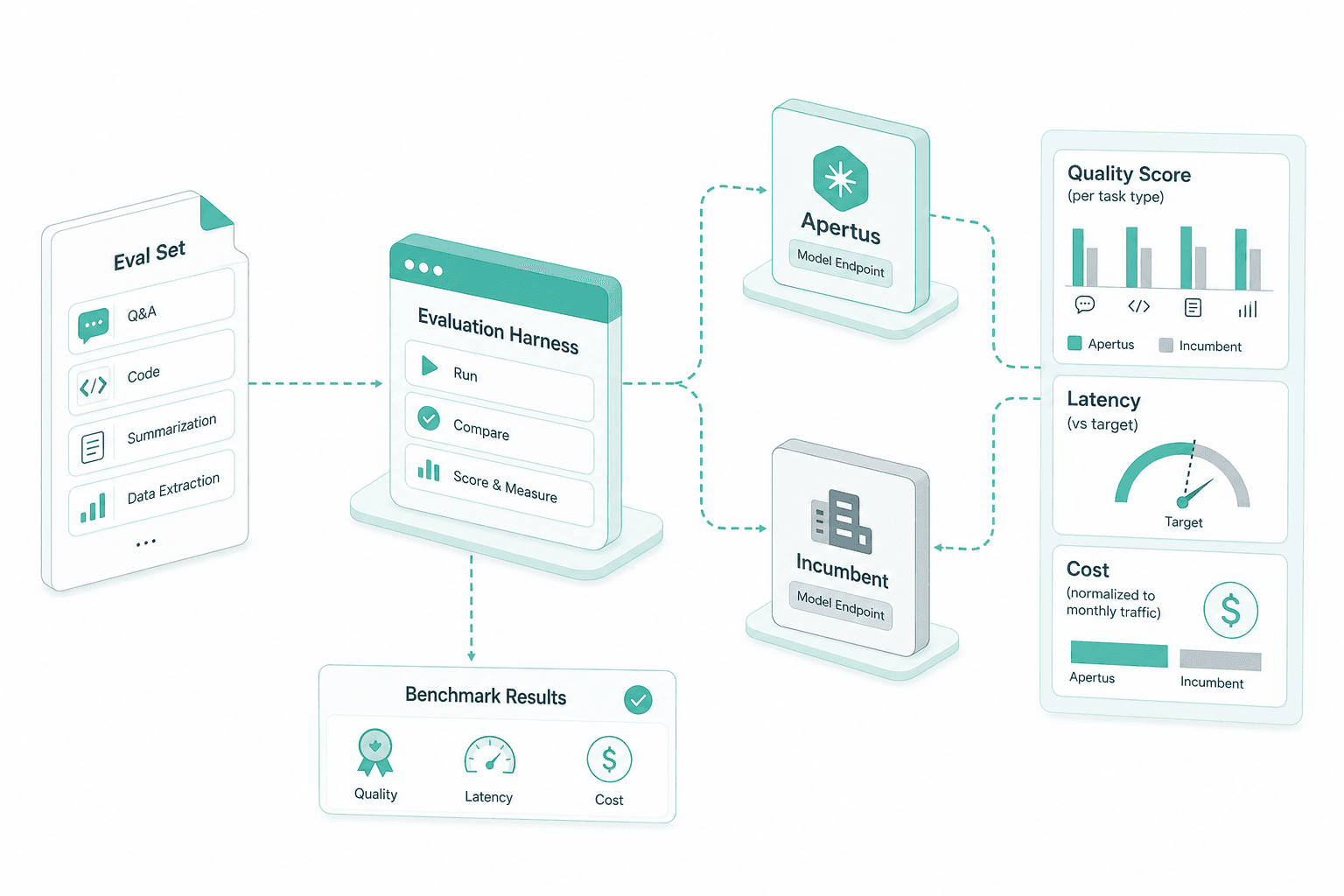
Benchmark runs
The eval set runs against Apertus and your incumbent in the same harness. Quality is scored per task type, latency is measured against your serving target, cost is normalized to monthly traffic.
Recommendation report
We write the go/no-go document: deploy on Apertus, stay on the incumbent, or split the workload by task type. The report carries the eval table, the cost model, the risk notes and the deployment shape we would build next.

Handover to production
If the call is go, the eval set feeds into the next phase — on-prem deployment, migration from OpenAI or Anthropic, or sovereign hosting. If no, you keep the eval set and the cost data anyway.
We run a structured workshop with your Head of AI, CTO or innovation lead to decide which workloads enter the POC, what the success bar is for each, and which incumbent model is being challenged.
We sample your real records under NDA, label a graded subset with your domain reviewers, and freeze it as the benchmark contract. The set covers quality, latency and cost, and stays yours to keep after the engagement closes.
Apertus 8B or 70B is served on a sandbox cluster — vLLM or TGI, the same stack we run in production. The prototype hits a real endpoint through the Laravel and Next.js spine, so your team can poke it and not just read about it.
The eval set runs against Apertus and your incumbent in the same harness. Quality is scored per task type, latency is measured against your serving target, cost is normalized to monthly traffic.
We write the go/no-go document: deploy on Apertus, stay on the incumbent, or split the workload by task type. The report carries the eval table, the cost model, the risk notes and the deployment shape we would build next.
If the call is go, the eval set feeds into the next phase — on-prem deployment, migration from OpenAI or Anthropic, or sovereign hosting. If no, you keep the eval set and the cost data anyway.
Selected engagements
SWISS INSURANCE POC
Insurance Document Automation POC for a Swiss Back Office

How SAPIENTROQ built a schema-driven insurance document automation POC for a Swiss back office: Mistral OCR plus OpenAI JSON-mode extraction, schemas generated live from admin-defined categories, with provider-swappable AI behind a single interface.
View Case
Why a paid POC beats a workshop
A POC that ends with a numbered eval table, not a workshop
A POC that doesn't end with a numbered eval table is a workshop. Ours ends with the same eval set the production system will be measured against — so the go/no-go call is a number, not a feeling.
The eval set is the contract
The same labelled set you sign off in week one is the set Apertus and your incumbent model both run against in week three. It does not get rewritten to flatter the result, and it does not disappear after the report — it carries through into the production phase as the acceptance gate for every release.
Paid, two to four weeks, scoped per project
This is a paid engagement, not a free pilot. The duration sits at two to four weeks; the price is quoted per project after the discovery call, once the task set, data access and success bar are agreed. Paying for the POC is what keeps the recommendation honest — including the recommendation to stay on the incumbent.
Where the POC goes next
If the apertus poc recommendation is go, we move into the production on-prem deployment, the migration from OpenAI or Anthropic, or Swiss sovereign hosting. The engagement sits inside the Apertus Swiss LLM service line and starts from the AI consulting discovery front door.
Frequently Asked Questions
All three, but the deliverable that matters is the recommendation. You receive a running Apertus prototype on your real tasks, a benchmark report against your incumbent model on quality, latency and cost, and a go/no-go document. The eval set is yours to keep.
The standard engagement is two to four weeks, depending on how many task types are in scope and how clean the source data is. It is a paid engagement, scoped per project — we quote after a discovery call once the task set, data access and success bar are agreed in writing.
The set is your set — extraction from supplier sheets, document Q&A, German or French summarization, classification against ETIM, light agentic flows. We pick the workloads that matter for your roadmap, not a generic public leaderboard, so the numbers map onto your real backlog.
We build one eval set that runs against Apertus and your current GPT-4o, Claude or Gemini deployment in the same harness. Quality is scored per task type, latency is measured against your serving target, cost is normalized to your traffic. The output is a side-by-side table.
Yes, and that is the point of paying for the evaluation. If Apertus does not meet the bar on a given task — accuracy, latency or operating cost — the report says so, and we recommend keeping the incumbent or splitting the workload. A no is a finished POC, not a failed one.
The same eval set becomes the contract for the next phase. If the call is go, we move into the production on-prem build or migration from OpenAI or Anthropic, measured against the same numbers.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ