Legacy Software Modernization
Legacy Modernization Engineering
End-to-end modernization, not a code review
We take a legacy system that nobody wants to touch and bring it back to a state your engineers want to work in. That covers the database, the backend, the integrations and the deployment path. The output is a typed, tested, observable stack that fits the way your team actually ships — not a thick deck of recommendations to file away.
Database rebuild before any rewrite
Most legacy pain is data-shaped: tables that grew sideways for years, missing indexes, denormalized blobs, queries that scan everything. We map access patterns first, design the target schema, then migrate with a dual-write window so the old system stays live until the new one is faster and correct.
Backend rewrite in slices
A full backend rewrite happens module by module, not in a single cutover. We carve the old monolith along domain seams, stand up the new service in TypeScript or Node with strict types and contract tests, then route traffic with a feature flag. Each slice ships behind a kill switch — if the new path misbehaves, we flip back in seconds.
API and integration layer redo
Legacy systems hide their interfaces in stored procedures, CSV exports and weekly batch jobs. We replace them with a documented REST or GraphQL surface, typed client SDKs, and event hooks for the downstream systems that the old platform fed manually. Partner integrations stop being a quarterly project.
Infrastructure as code and clean CI/CD
We codify the target environment in Terraform, move deployments behind a single CI/CD pipeline, and add observability that actually fires — logs, traces, error budgets, and uptime dashboards. The new system runs on AWS, Hetzner or on-premises depending on data residency. No more snowflake servers that one engineer remembers how to restart.
Surgical refactor when a rewrite is overkill
Not every legacy system needs a full rebuild. When the architecture is sound but tech debt has accumulated, we do a scoped refactor: extract the worst modules, add the missing tests, upgrade frameworks two majors at a time, and pay down the debt that is actually costing you velocity. Six to twelve focused weeks instead of a year-long program.
Knowledge transfer and run mode
The modernized system is handed over with architecture docs, runbooks, on-call playbooks and a working test suite. Your team picks it up; we stay on a light support engagement for the first quarter to keep regressions out and answer the questions nobody thought to ask during delivery.
How we modernize legacy systems
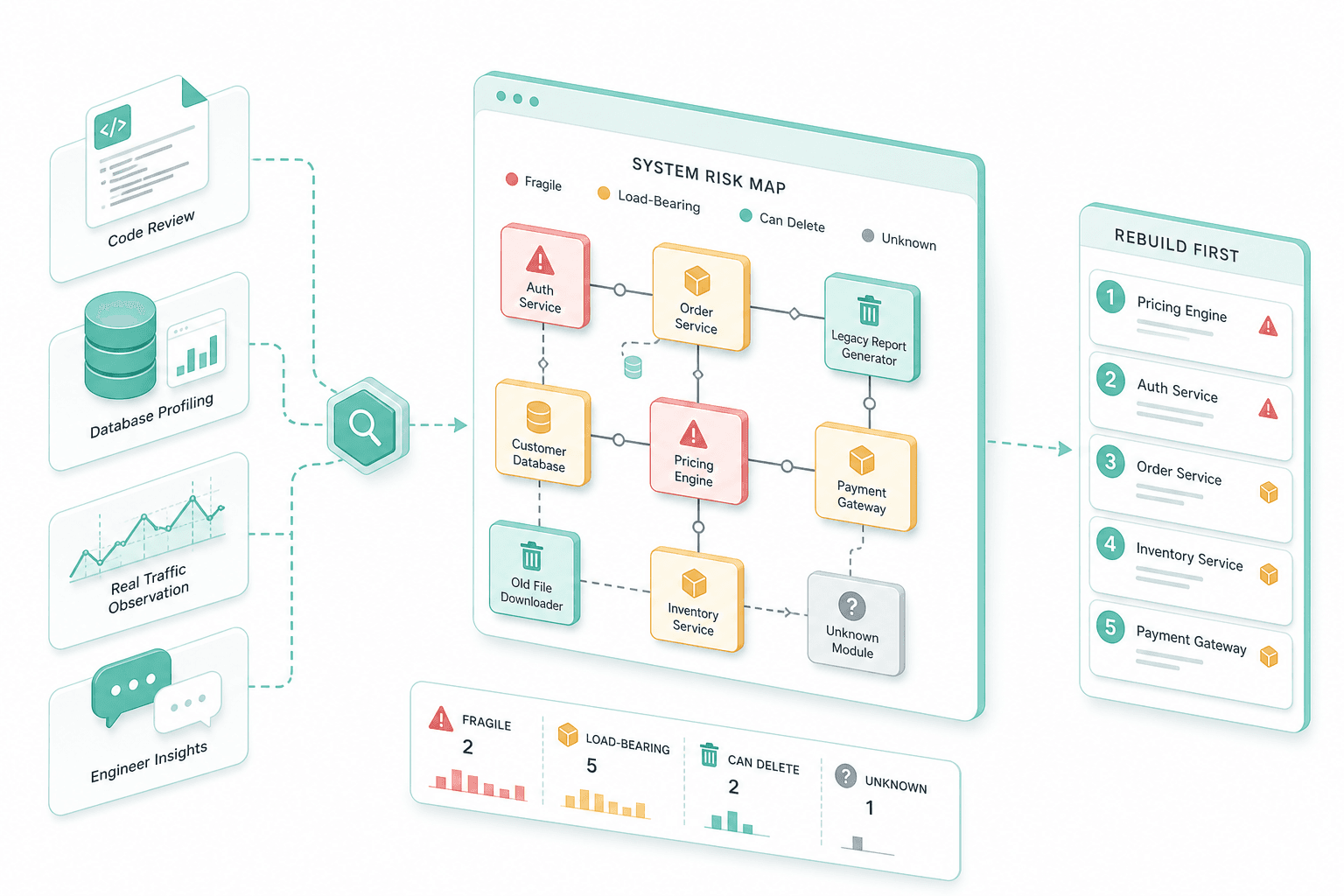
System audit and risk map
We read the code, profile the database, watch real traffic and talk to the engineers who carry the pager. Output: a risk map naming what is fragile, what is load-bearing, what can be deleted, and which slice rebuilds first.
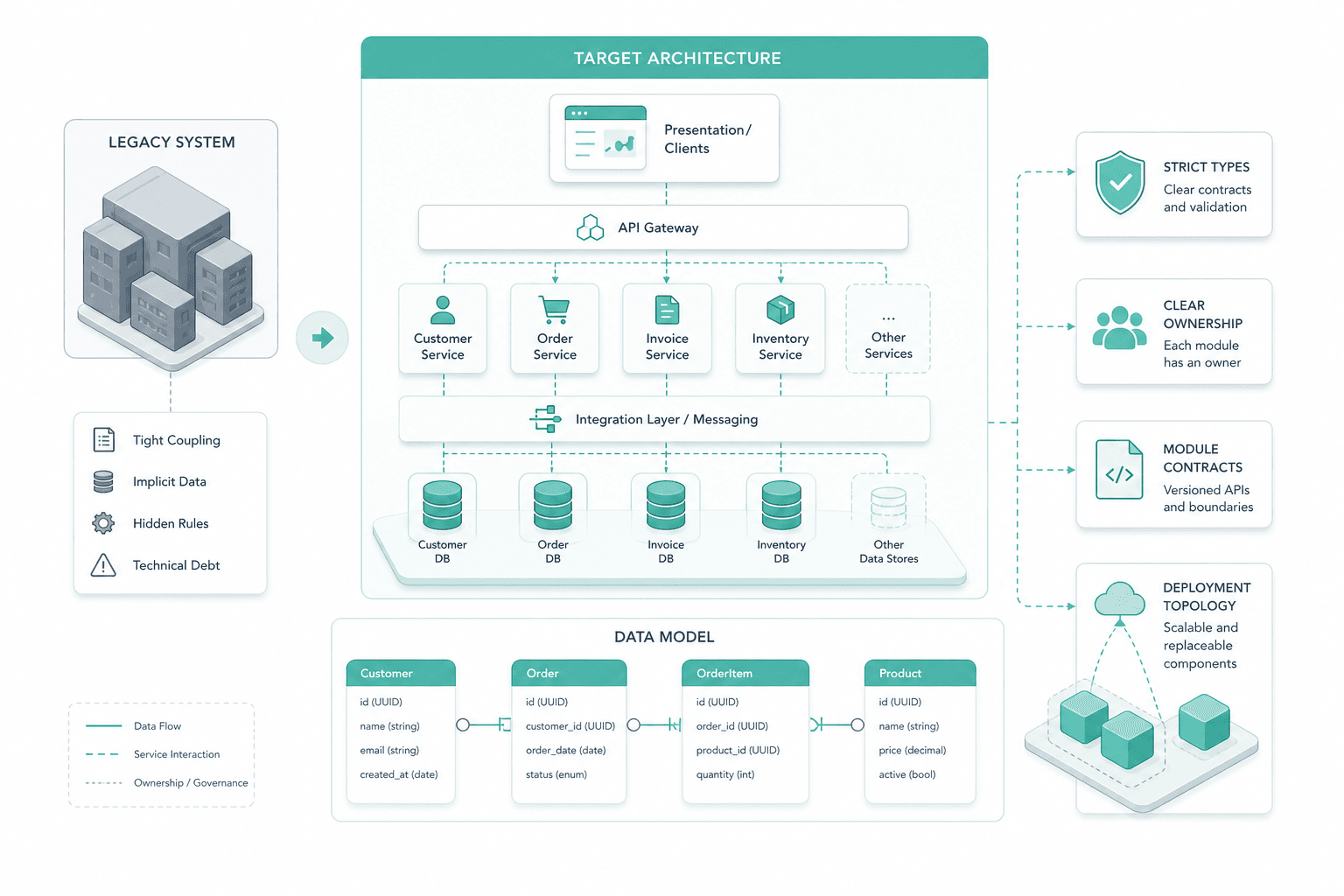
Target architecture and data model
Before any rewriting, we lock the target shape: the data model, service seams, module contracts and deployment topology. Strict types and clear ownership replace rules the old system enforced by accident.
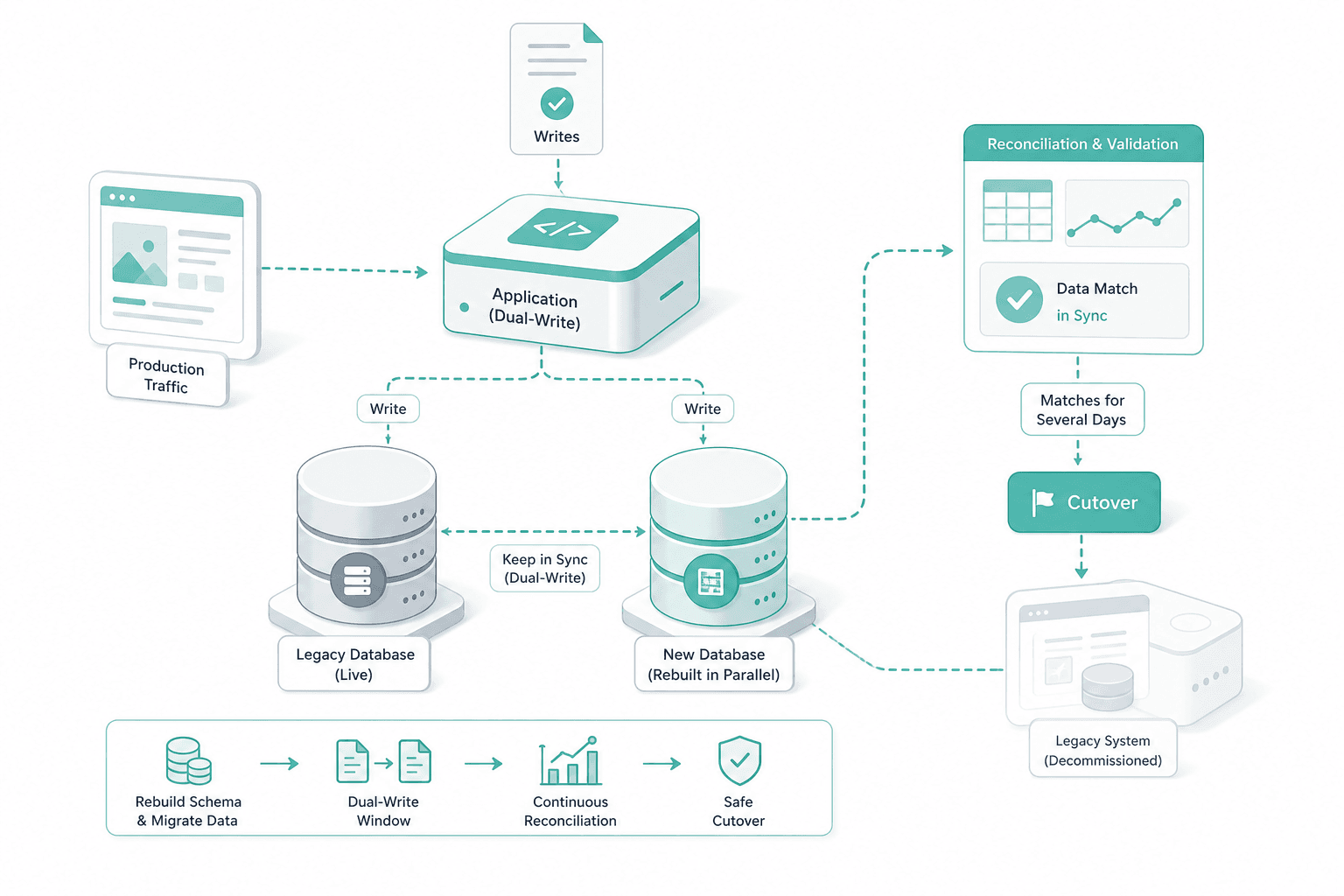
Database migration with dual-write
The database is rebuilt in parallel and kept in sync through a dual-write window. The old system serves production while the new schema proves itself on real load. Cutover only when reconciliation matches for several days.
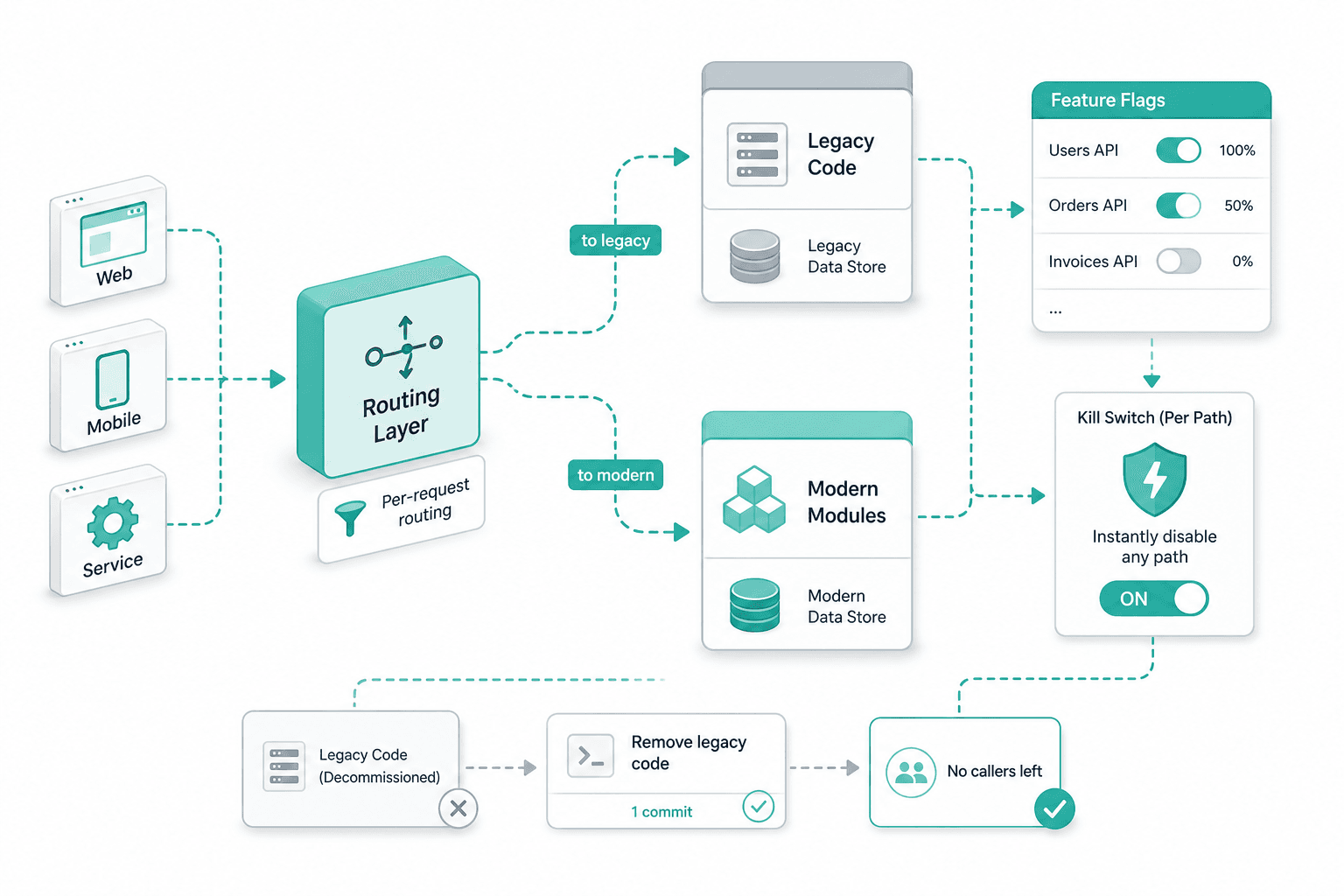
Strangler-fig backend rewrite
New modules ship behind a routing layer that picks legacy or modernized code per request. Traffic moves slice by slice behind feature flags, with a kill switch on every path. Legacy code is removed in one commit when no caller is left.
Test harness and observability
Before any module is retired, it gains contract tests, integration tests and structured logs. Errors get budgets, latencies get SLOs, dashboards make regressions visible the same day. Observable by construction, not after the first outage.
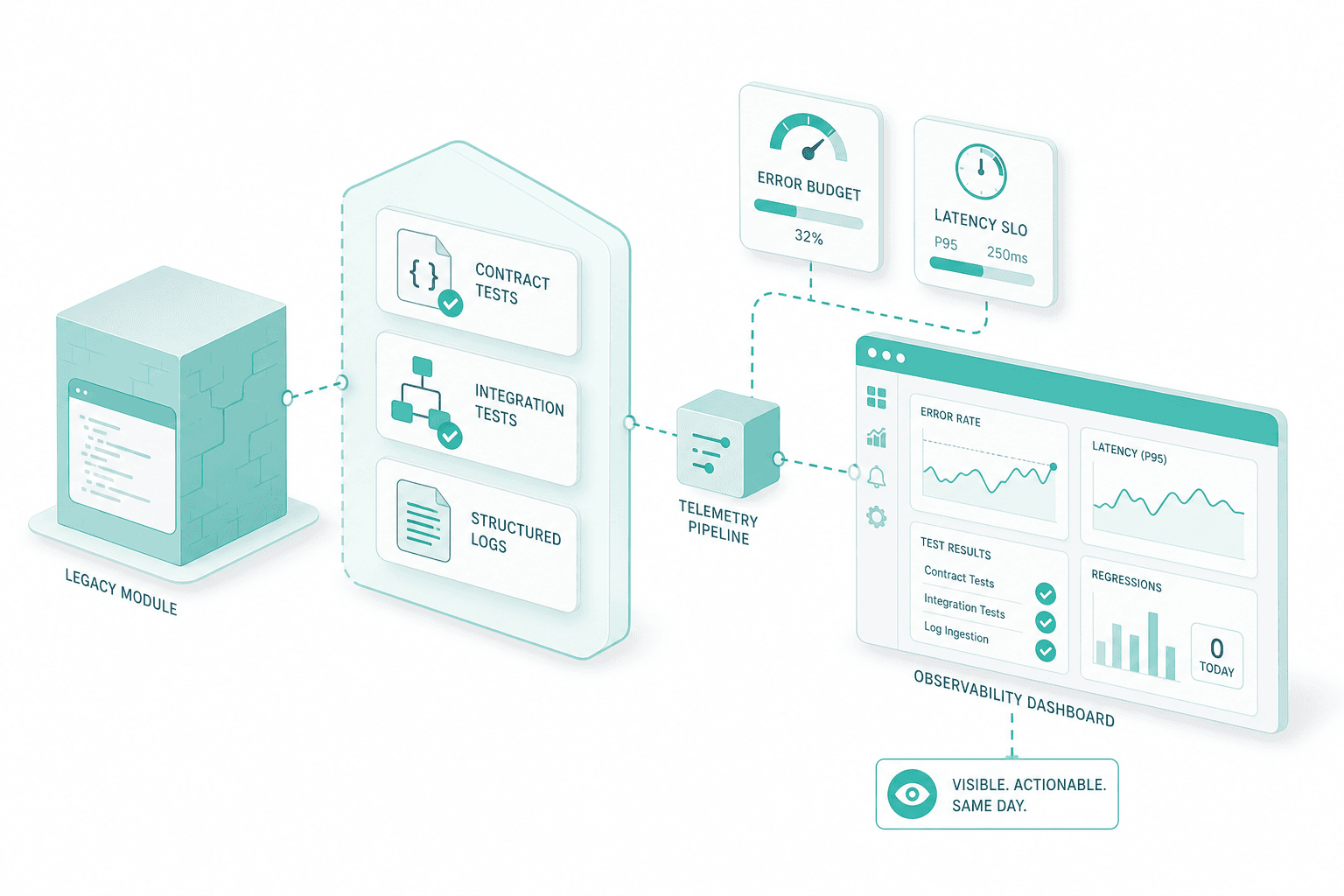
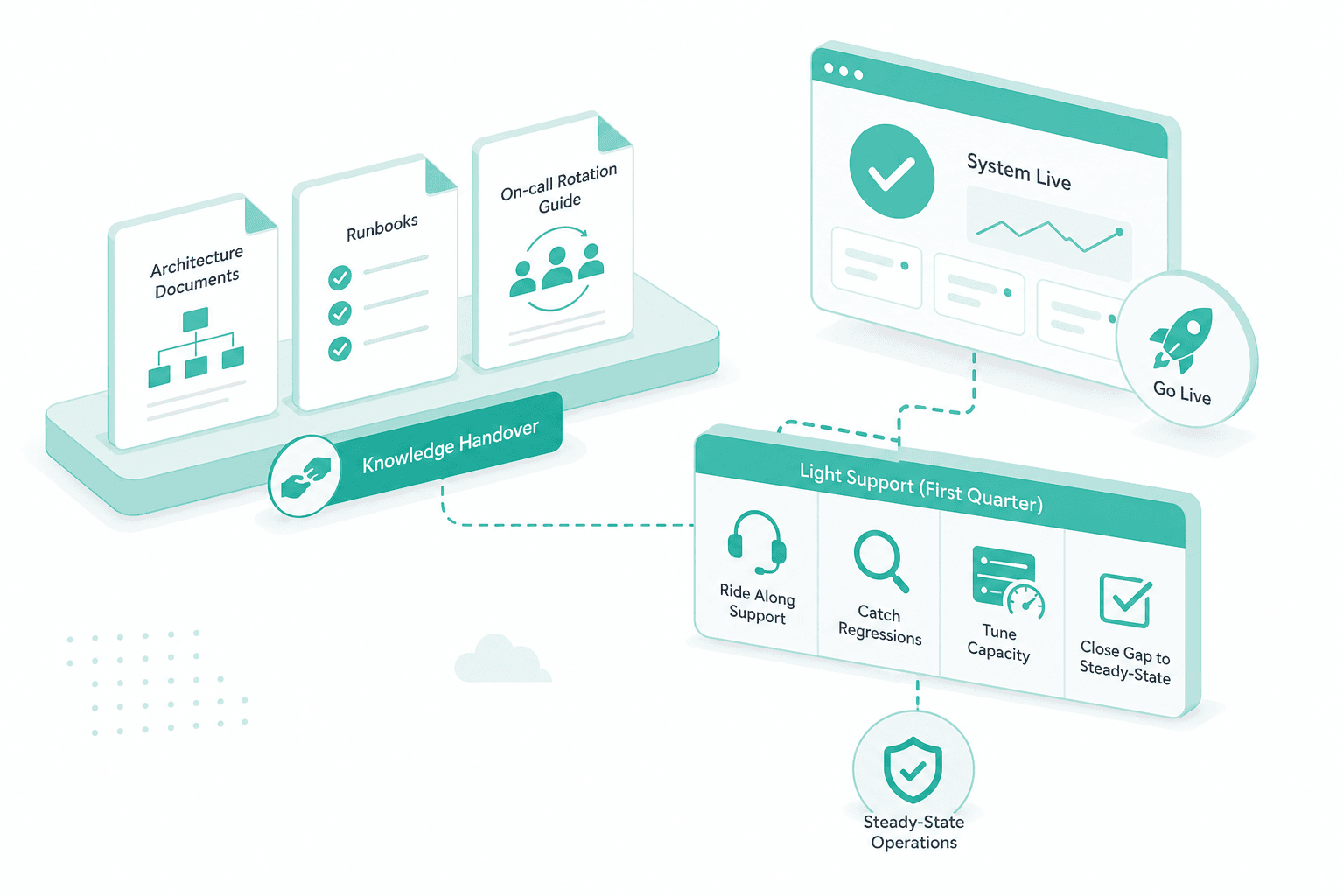
Handover and post-launch support
We hand over architecture docs, runbooks and an on-call rotation guide. For the first quarter we ride along on a light support contract to catch regressions, tune capacity and close the gap to steady-state operations.
We read the code, profile the database, watch real traffic and talk to the engineers who carry the pager. Output: a risk map naming what is fragile, what is load-bearing, what can be deleted, and which slice rebuilds first.
Before any rewriting, we lock the target shape: the data model, service seams, module contracts and deployment topology. Strict types and clear ownership replace rules the old system enforced by accident.
The database is rebuilt in parallel and kept in sync through a dual-write window. The old system serves production while the new schema proves itself on real load. Cutover only when reconciliation matches for several days.
New modules ship behind a routing layer that picks legacy or modernized code per request. Traffic moves slice by slice behind feature flags, with a kill switch on every path. Legacy code is removed in one commit when no caller is left.
Before any module is retired, it gains contract tests, integration tests and structured logs. Errors get budgets, latencies get SLOs, dashboards make regressions visible the same day. Observable by construction, not after the first outage.
We hand over architecture docs, runbooks and an on-call rotation guide. For the first quarter we ride along on a light support contract to catch regressions, tune capacity and close the gap to steady-state operations.
Selected engagements
WEITA AG
Weita Supplier Onboarding Workflow: Wholesale Digital Transformation

How SAPIENTROQ built a Laravel and Next.js workflow that turns PDFs, emails, images and spreadsheets into compliant PIM products for Weita AG, with Mistral OCR, OpenAI JSON-mode extraction and a database-backed prompt registry.
View Case
CREABETON AG
New business field for service offers
Seamless digital networking of products, activities, customers and planning tools creates a professional full-service offering.
Design Thinking
Business Innovation
+ 3
View Case
Why our modernization engine, not a generic rewrite
We rebuild what the business depends on, in slices
Modernization fails when teams try a big-bang rewrite while the old system still earns revenue. We carve the platform into modules, rebuild one slice at a time behind a strangler-fig routing layer, and only retire old code once the new path has carried real traffic for weeks.
Data architecture first, framework choice second
Most legacy systems are slow because the data model rotted, not the framework. We start with the database — access patterns, indexes, denormalized blobs — and design a target schema that answers the queries the business actually runs. The framework choice gets easier once the data shape is right.
Strict types and contract tests, not hope
Strict types in the new backend, contract tests at every service boundary, integration tests on paths that move money or data. The legacy system survived on tribal knowledge; the modernized one survives on tests. A new engineer can change code on day three without breaking downstream systems.
Observability before retirement
Before any legacy module is retired, the replacement is wired with structured logs, traces, error budgets and uptime SLOs. Regressions surface in hours, not weeks after a customer complaint. Modernization that ships dark is just new debt with a different name.
Honest scope, honest timeline
Some platforms need a full rewrite. Many need a focused refactor: extract the two worst modules, add missing tests, upgrade two framework majors, stop. We say so up front and estimate in weeks and slices, not vague phases. The cheapest modernization is the one you do not have to do twice.
Frequently Asked Questions
Modernization rebuilds a system that still earns revenue but blocks new work — slow pages, fragile deploys, framework two majors behind. You need it when adding a feature takes weeks. Expect 8–26 weeks for a full rewrite, 4–12 weeks for a surgical refactor.
If the data model is sound and only a few modules are rotten: refactor — extract the worst slices, add tests, upgrade the framework. If the database is denormalized and tests do not exist: rewrite. We deliver a written audit in 2–3 weeks before any rebuild starts.
Strangler-fig: a routing layer in front of the old platform sends a slice of traffic to the new module while everything else stays on legacy. Each slice ships behind a feature flag with a kill switch — under a minute to flip back if the new code misbehaves.
Both, database first. We design the target schema, migrate with a dual-write window so old and new stay in sync, and cut over only when reconciliation matches for several days. Query latency typically drops from 10+ seconds to under one once indexes and access patterns are right.
Default target: TypeScript on Node with Nest, PostgreSQL or the existing relational engine, GraphQL or REST, Redis for queues and caches, Terraform-managed AWS or on-premises. The stack is picked to match your team's hiring pool, not a buzzword list.
Full backend rewrite of a mid-size platform: 8–26 weeks depending on slice count and integration surface. Surgical refactor of the two or three worst modules: 4–12 weeks. Audit-and-recommendation alone: 2–3 weeks with a written report and a slice-by-slice plan.
It keeps running. Strangler-fig routing carries traffic between legacy and modernized paths during the rebuild. Once every caller is on the new code, the old module is removed in one commit. The legacy database is retained one quarter as a cold read replica for audit and rollback.
No. Delivery includes architecture docs, runbooks, on-call playbooks and a working test suite. Your team owns the stack; we stay on light support for the first 12 weeks, then step back. About half of our customers continue with us on feature work, half take it fully in-house.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ