Apertus Domain Fine-tuning
What an Apertus fine-tune delivers
LoRA adapters on the 8B class
LoRA fits the 8B Apertus variant when you want fast iteration loops and small adapter files instead of full weight sets. Adapters are versioned per use case — one for the back-office advisor, another for contract review — and swapped at serving time on the same base, keeping the apertus fine-tuning cost curve flat as more tuned tasks ship.
QLoRA on the 70B variant
QLoRA quantizes the base in memory, so a 70B Apertus fine-tune fits on a smaller GPU footprint than a full-precision run would demand. For Swiss enterprises sizing their first H100 or A100 cluster, it is the practical default — the 70B class becomes trainable inside the budget you already hold, with no second site rented to do it.
Full fine-tunes for differentiation
When LoRA is not enough — when the domain language drifts far from the base, or you want a model that is permanently yours — we run a full fine-tune of the 70B class. Weights become the client asset, hosted on the same on-prem stack as the base, trading a longer training cycle for a durably distinct model.
Swiss-language terminology
Apertus covers Swiss-German, French, Italian and Romansh in its base training. Fine-tuning extends that with your house style: banking phrasing, insurance product wording, treuhand audit terminology, cantonal administrative language. Pairs are curated per locale and Swiss-German dialect stays distinct from standard German throughout.
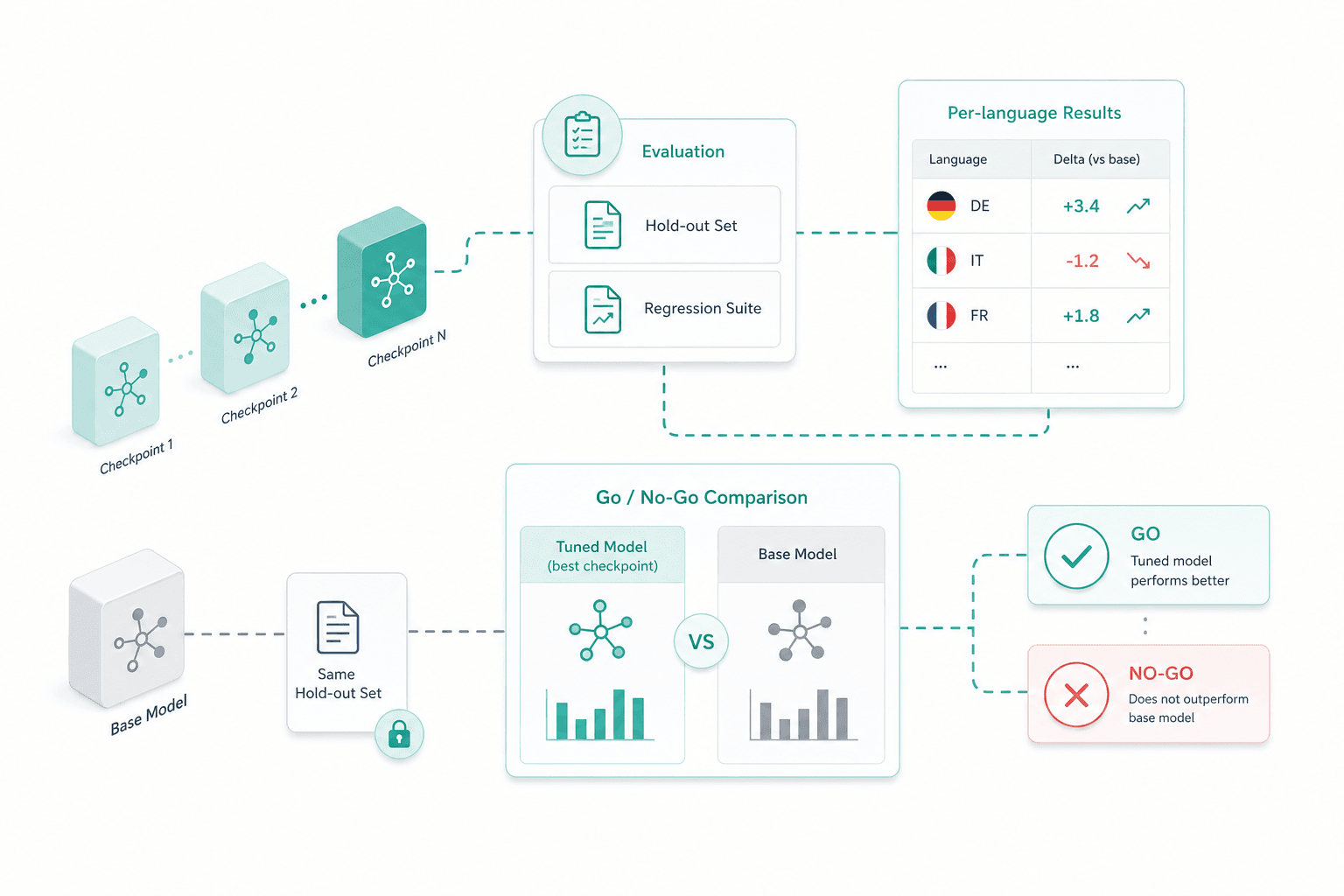
Evaluation set and regression suite
The evaluation set is built before training, not after. Domain owners agree the hold-out drawn from real tasks, a regression suite re-runs on every checkpoint, and quality is tracked over the run rather than read off the final loss curve. Go/no-go is the tuned model versus the same hold-out on the base — auditable by anyone in the room.
Hosting handoff to on-prem
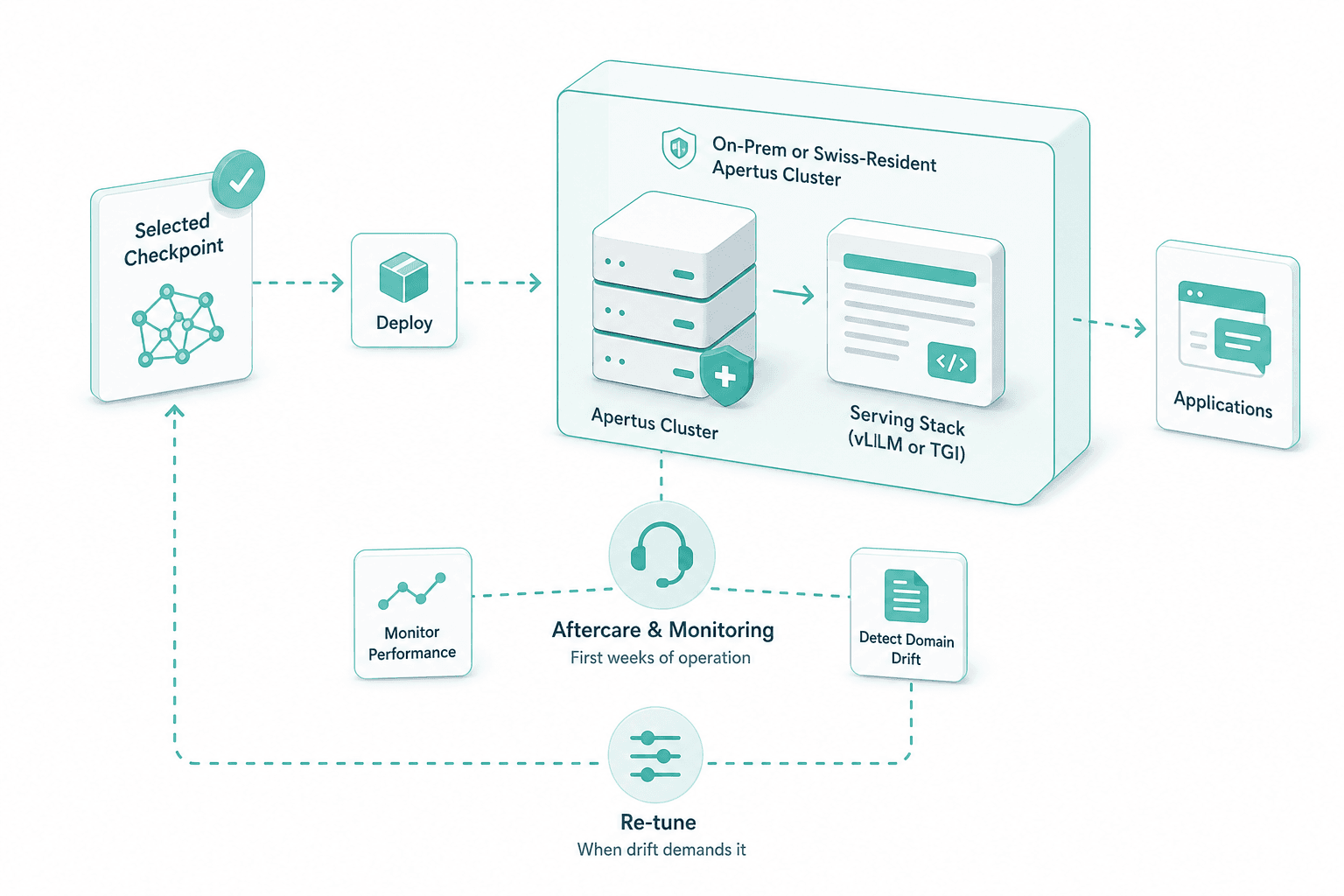
Tuned weights ship to the same Swiss-resident or on-prem cluster already chosen for the parent Apertus rollout. The fine-tune inherits the existing serving stack — vLLM or TGI, Hugging Face transformers — and the audit trail you already accept. No second tenant, no extra residency review, no new procurement path.
How we run a fine-tune
Scoping with owners
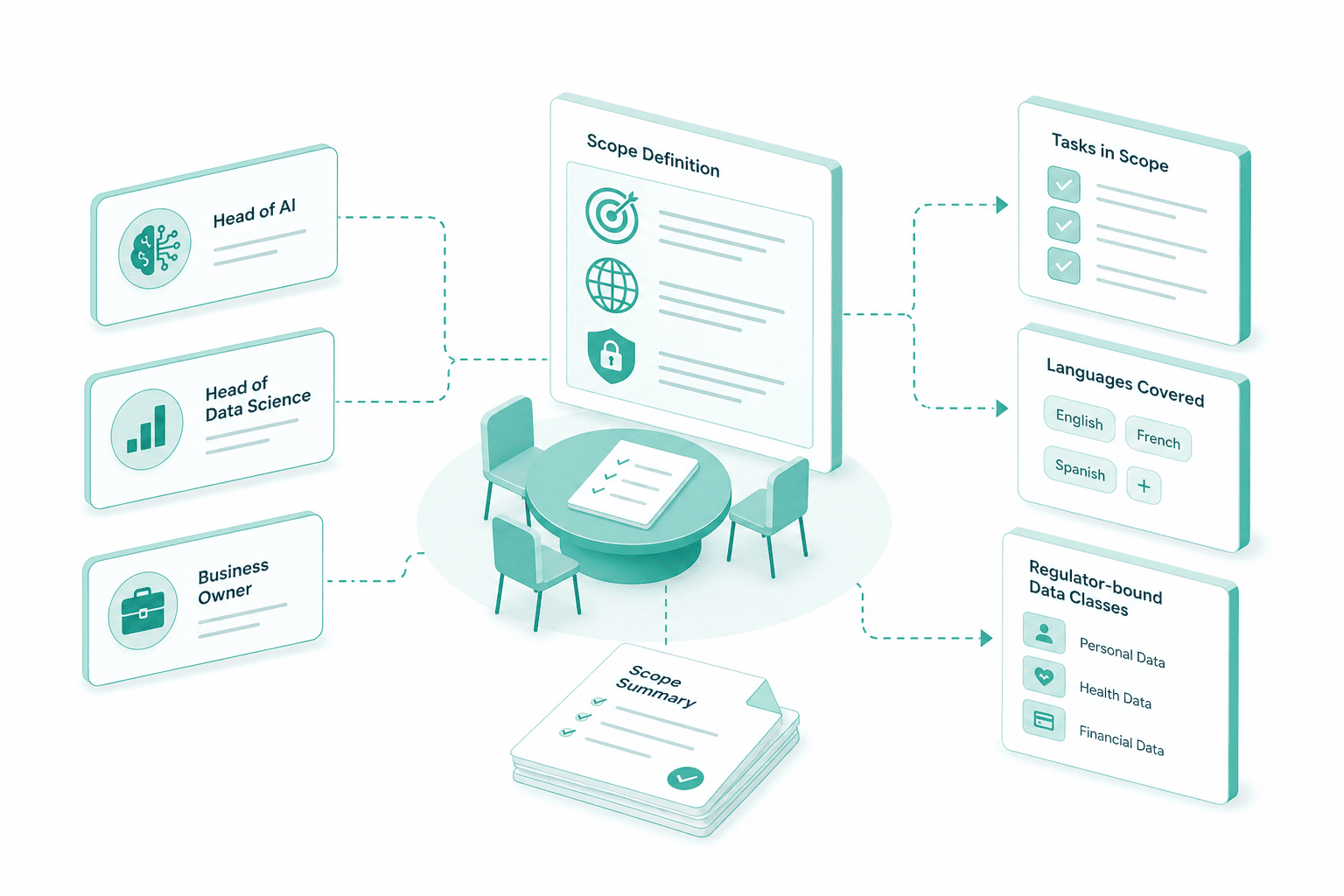
We sit with heads of AI, data science and the business owners who will use the model. The scope locks the tasks the fine-tune handles, the languages it covers, and the regulator-bound data classes it touches.
Evaluation set design
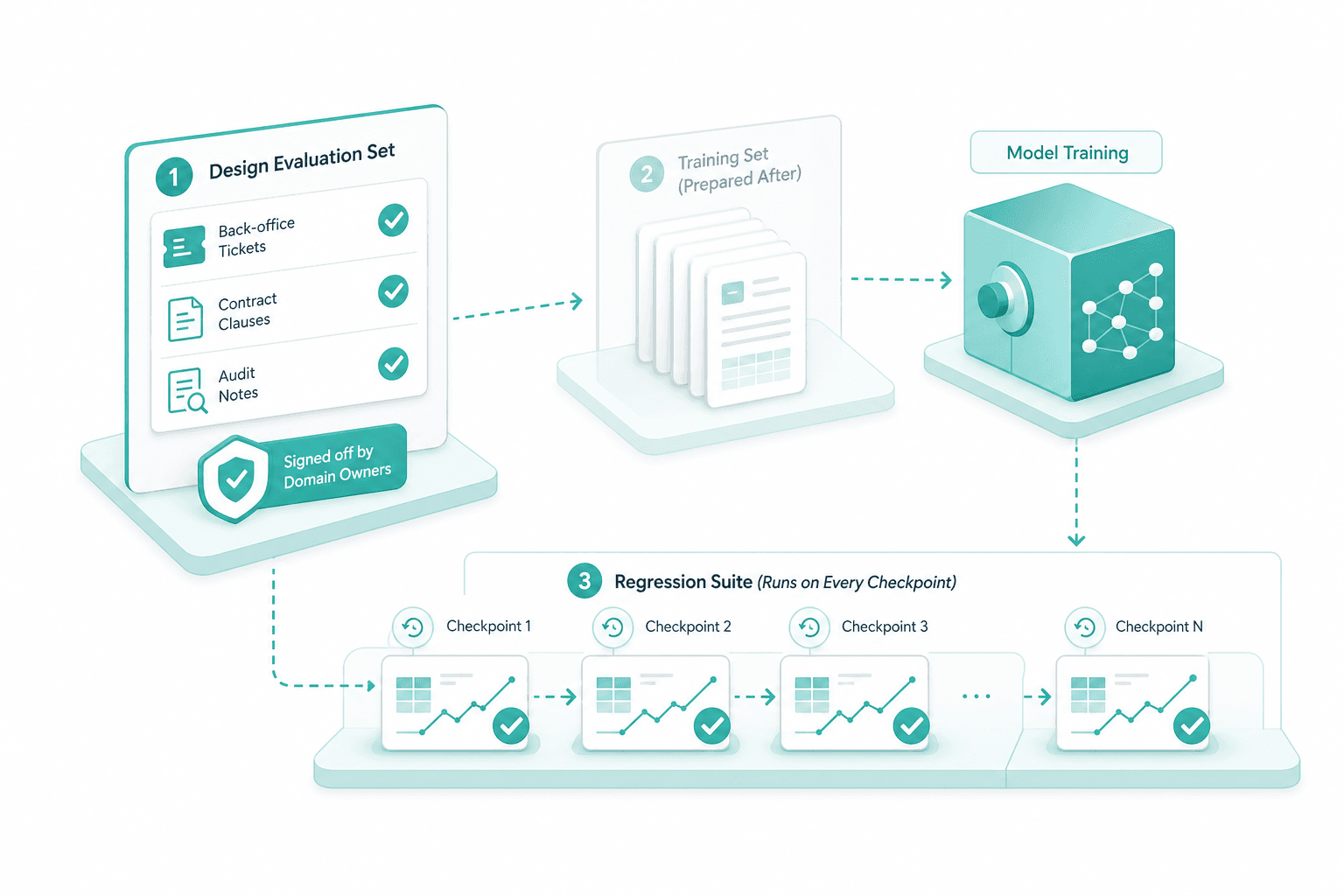
The eval set is designed before the training set. Hold-out tasks come from real workflows — back-office tickets, contract clauses, audit notes — and are signed off by domain owners. The regression suite runs on every checkpoint.
Data collection
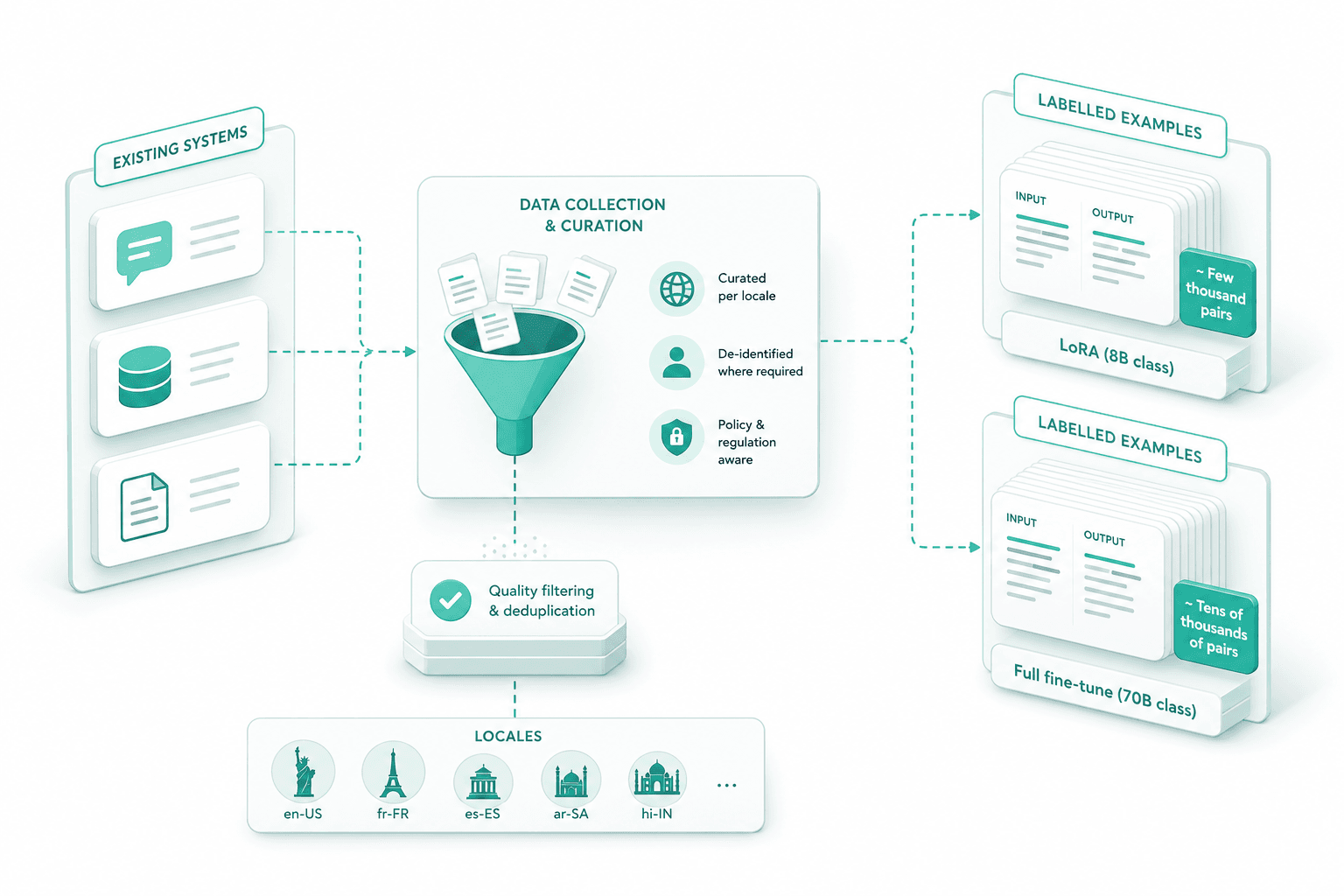
Labelled examples are pulled from existing systems, curated per locale, and de-identified where regulation requires. LoRA on the 8B class wants a few thousand high-quality pairs; a full 70B run wants tens of thousands.
Training on Swiss GPUs
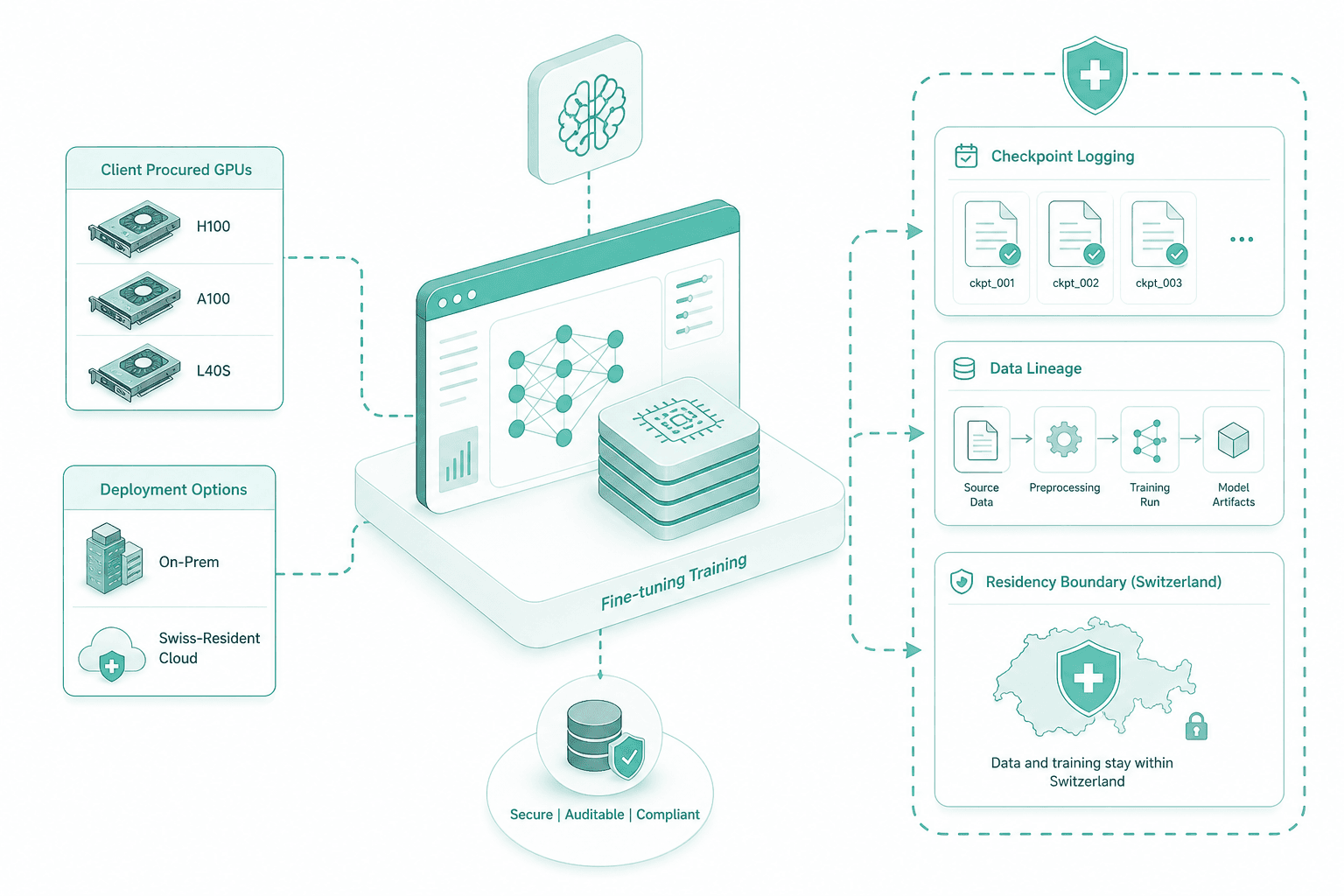
Training runs on the GPU footprint the client already procured — H100, A100 or L40S, on-prem or Swiss-resident cloud. We log every checkpoint, capture data lineage, and stay within the parent rollout residency boundary.
Evaluation and go/no-go
Each checkpoint is scored against the hold-out and regression suite. Per-language deltas are reported separately so a DE gain never hides an IT regression. Go/no-go compares the tuned model against the same hold-out on the base.
Handoff and aftercare
The chosen checkpoint deploys to the existing on-prem or Swiss-resident Apertus cluster, behind the same vLLM or TGI serving stack. We stay engaged through the first weeks of operation and re-tune when domain drift demands it.
We sit with heads of AI, data science and the business owners who will use the model. The scope locks the tasks the fine-tune handles, the languages it covers, and the regulator-bound data classes it touches.
The eval set is designed before the training set. Hold-out tasks come from real workflows — back-office tickets, contract clauses, audit notes — and are signed off by domain owners. The regression suite runs on every checkpoint.
Labelled examples are pulled from existing systems, curated per locale, and de-identified where regulation requires. LoRA on the 8B class wants a few thousand high-quality pairs; a full 70B run wants tens of thousands.
Training runs on the GPU footprint the client already procured — H100, A100 or L40S, on-prem or Swiss-resident cloud. We log every checkpoint, capture data lineage, and stay within the parent rollout residency boundary.
Each checkpoint is scored against the hold-out and regression suite. Per-language deltas are reported separately so a DE gain never hides an IT regression. Go/no-go compares the tuned model against the same hold-out on the base.
The chosen checkpoint deploys to the existing on-prem or Swiss-resident Apertus cluster, behind the same vLLM or TGI serving stack. We stay engaged through the first weeks of operation and re-tune when domain drift demands it.
Selected engagements
BICOSY / BICO.CH
AI Shopping Assistant for bico.ch on WooCommerce

How SAPIENTROQ built BICOSY, an AI shopping assistant for the Swiss mattress retailer bico.ch — a NestJS backend with pgvector RAG, declared typed tools and a WordPress plugin that streams live WooCommerce events into the conversation.
View Case
Why fine-tune Apertus with us
Fine-tune vs. just RAG
RAG fits when knowledge changes weekly and the model only needs to read it. Fine-tuning fits when terminology, tone and judgment patterns are part of the answer — Swiss banking phrasing, insurance product language, treuhand audit wording. Most engagements end up doing both, with retrieval layered on a tuned base. We walk through the trade-off on the parent Apertus Swiss LLM page, and route clients with a no-train preference to Apertus RAG integration instead.
Swiss-language terminology coverage
Apertus is the only frontier-class open model trained against full Swiss-language coverage — DE, FR, IT and Romansh, with Swiss-German kept distinct from standard German. Fine-tuning extends that with your house style: cantonal administrative language, insurance product wording, audit phrasing. Training pairs are curated per locale and the evaluation set checks each language separately.
Audit trail and regression suite
Fine-tuning the right way is a quiet investment: a hold-out evaluation set, a regression suite that gets re-run on every checkpoint, and a model that actually speaks the language of your back-office, not the language of a public benchmark. The audit trail covers data lineage, prompt versions and per-locale deltas — what a FINMA, MDR or cantonal-bound owner needs to defend the apertus fine-tuning decision to a regulator.
From POC to production on one stack
Most fine-tunes start after the paid Apertus evaluation POC shows the base model is close enough to be worth training. Tuned weights then ship to the existing on-prem Apertus deployment, inheriting the serving stack the parent rollout chose. Clients still scoping the question land via AI consulting first.
Frequently Asked Questions
RAG fits when knowledge changes weekly and the model only needs to read it. Fine-tuning fits when terminology, tone or judgment patterns are part of the answer — Swiss banking phrasing, insurance language, treuhand wording. Most engagements do both, RAG on a tuned base.
LoRA suits the 8B class when you want fast iteration and small adapter files. QLoRA shrinks GPU memory further and is the practical default for the 70B variant on a single node. Full fine-tunes are reserved for clients who want a permanently differentiated weights set.
As a rule of thumb a LoRA adapter on the 8B class starts to move the needle with a few thousand high-quality labelled examples; a full fine-tune of the 70B class typically wants tens of thousands. The exact number depends on task variety and is scoped during discovery.
Apertus already covers the four Swiss languages, so fine-tuning extends coverage rather than bolting it on. Training pairs are curated per locale, Swiss-German is kept distinct from standard German, and the eval set checks each language separately to keep regressions visible.
Before training starts we agree the evaluation set with the domain owners — a hold-out drawn from real tasks, not a public benchmark. A regression suite is re-run on every checkpoint, and go/no-go is the tuned model versus the same hold-out on the base.
The same cluster as the base. Most engagements deploy weights to the on-prem or Swiss-resident node already chosen during the parent Apertus rollout, so the fine-tune inherits the existing serving stack — vLLM or TGI, transformers, the audit trail you already accept.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ