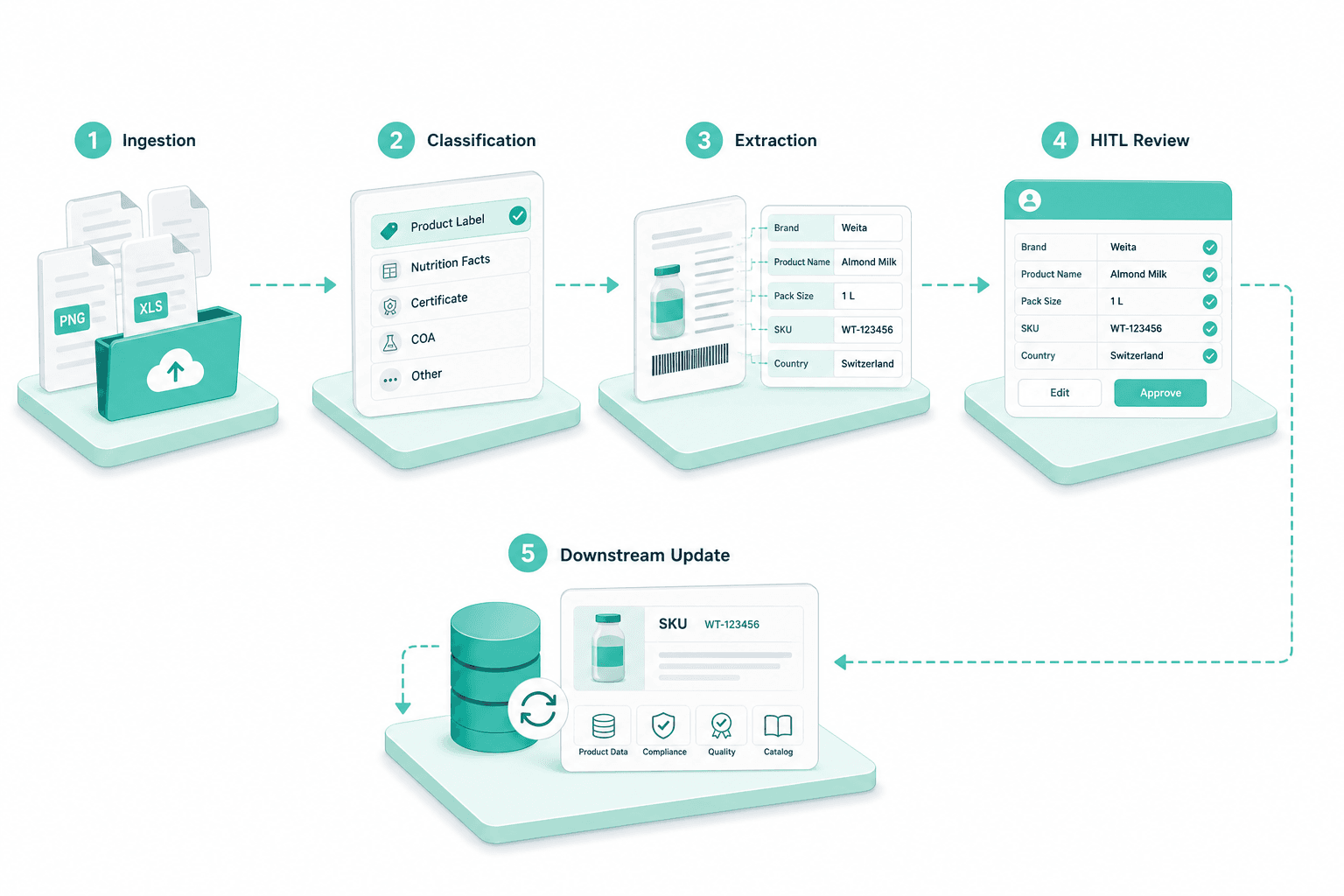
Classify & Extract Documents
Intelligent Document Processing Suite
Production IDP, not a model demo
We have built an end-to-end Intelligent Document Processing (IDP) pipeline that fits into your technology stack. Classify any document, extract information from it and surface it in a review environment for your approvers. The output of our IDP pipeline is high quality data that your ERP, PIM etc. already trust.
Multi-format document ingestion
Inbound documents come in all shapes and sizes. PDFs, scanned images, .xlsx and .doc files, supplier datasheets and email bodies all go down the pipeline. For documents with images — scanned invoices, handwritten Belege — Mistral OCR runs a two-pass process: raw text first, then structured. Multi-column German invoices parse cleanly.
AI classification by your taxonomy
Rather than rule sets per format, classification is driven by an admin-defined Category model. For each Category the admin defines Document Types, Field Blocks, and the Downstream Roles tasked with review. Adding another family — Leistungsabrechnung, Lieferschein — is one admin change. Document classification AI follows the schema.
Structured extraction in JSON mode
After classification, a document is routed to the extraction schema for its category. The schema defines field blocks, types, and required vs optional flags. The model is forced into OpenAI JSON mode, so document data extraction outputs a typed JSON payload — ready for downstream systems without additional parsing.
Role-gated human-in-the-loop review
Anything the pipeline cannot extract cleanly — partial tables, misclassified documents, low-confidence fields — routes to a HITL review queue for the right role. Approved data flows downstream; rejections feed the prompt registry as training signal. AI document extraction is verified, not assumed.
Swiss-multilingual: EN, DE, FR, IT
All categories, field blocks and review surfaces carry EN and DE locales out of the box. French and Italian extend via the prompt registry without code changes. A Romandie supplier sheet, a Zurich Versicherung claim and a Ticino contract all run through one end-to-end intelligent document processing pipeline.
Swiss data residency on request
For FINMA, MDR or IVDR-sensitive content, deploy on Swiss-resident hosting or on customer premises. Apertus offers a sovereign LLM track — document content never leaves Swiss or EU jurisdiction. All classification and extraction decisions are logged at audit-grade level, surfaced transparently to the customer.
How we deliver it
Discovery and schema lock
We start with your documents — sample sets per family, the downstream system that will consume the data, and the roles tasked with review. AI document automation begins with concrete schemas, not abstractions.
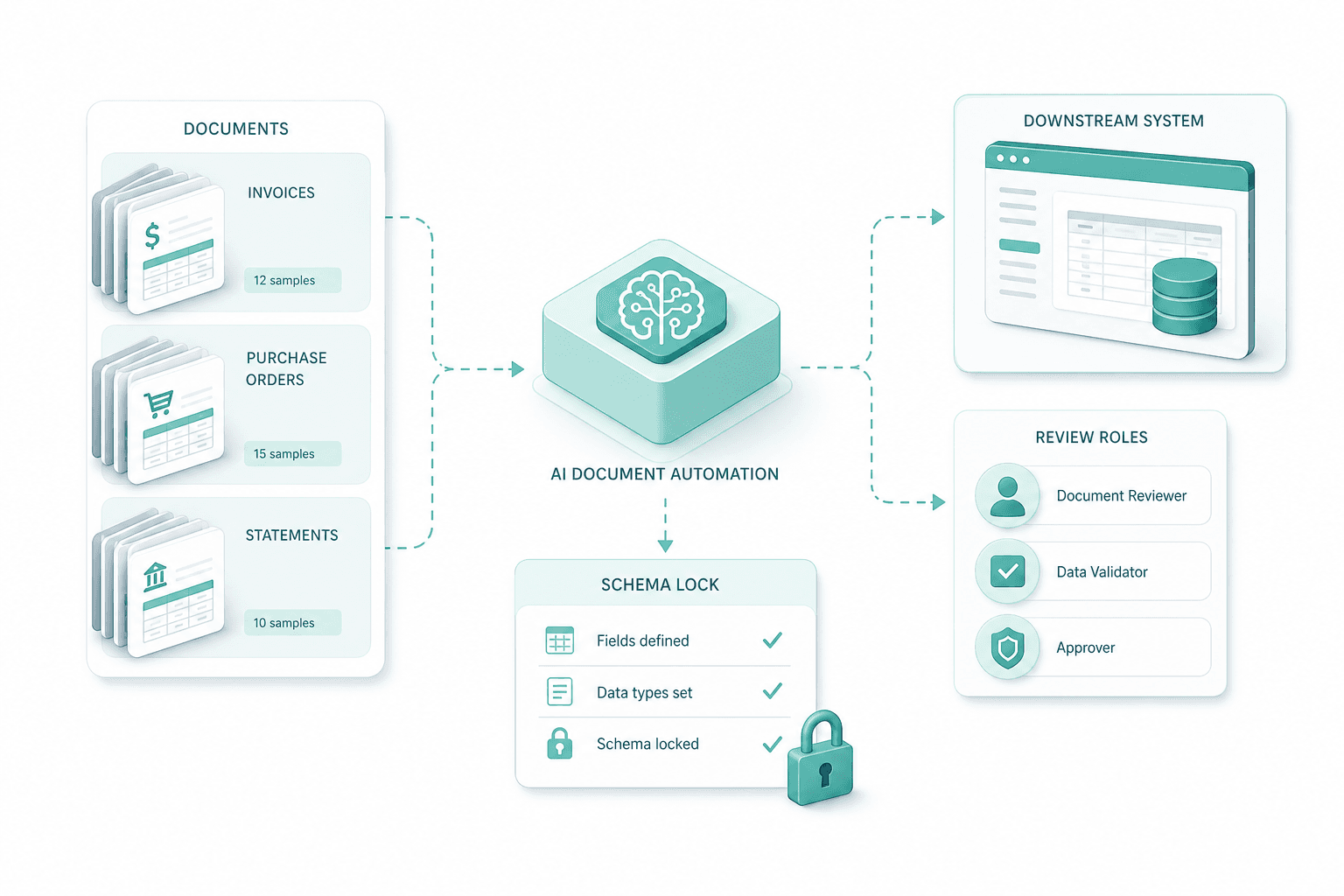
Pilot family deployment
The pipeline runs end-to-end for one family: ingestion, classification, extraction, HITL review, downstream update. We used this intelligent document automation to process hundreds of thousands of SKUs at Weita and Sanitas.
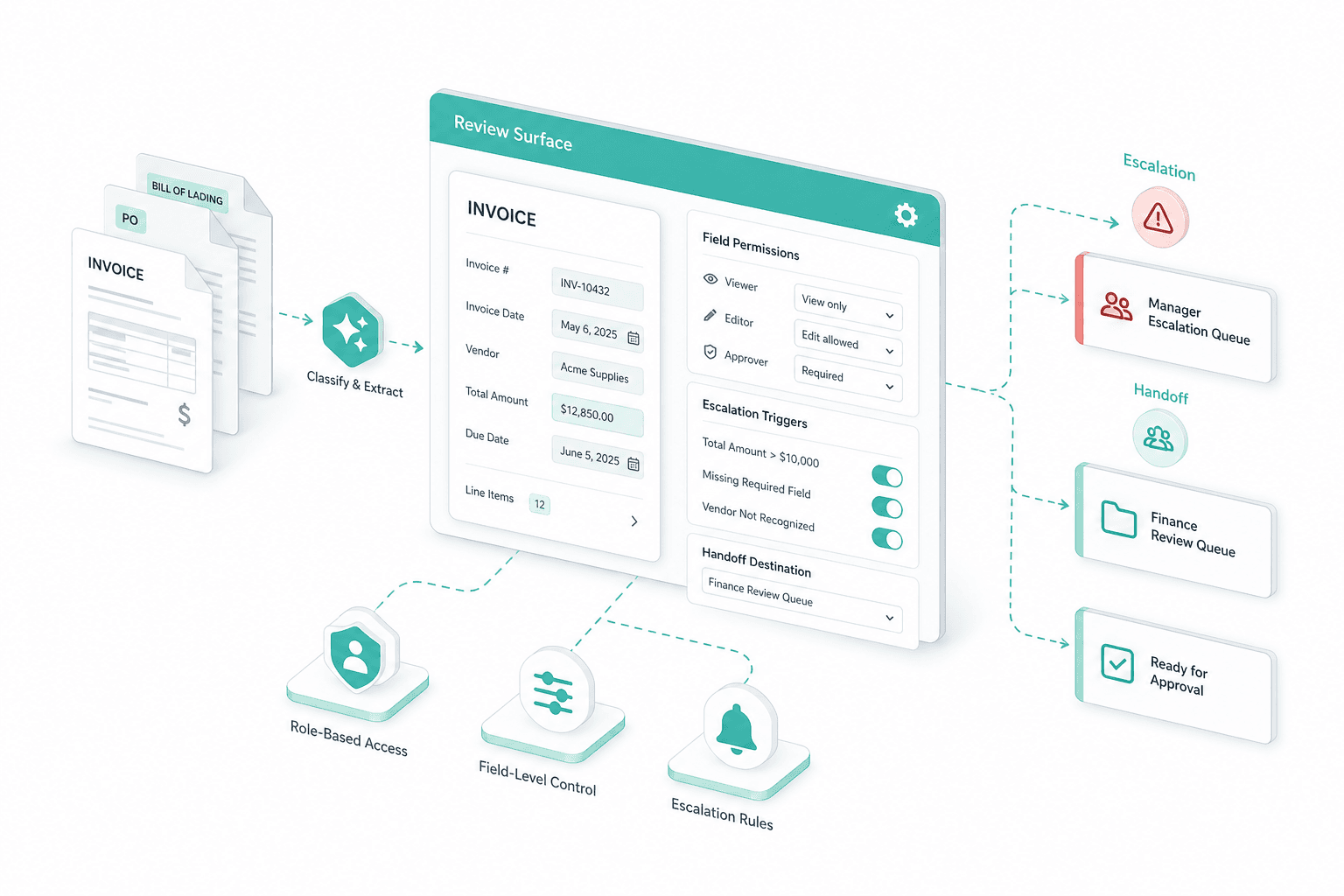
Review surface tuning
Customize the review experience to fit the roles of individuals within your organization — who can see and edit which fields, what triggers an escalation, and where each handoff lands.
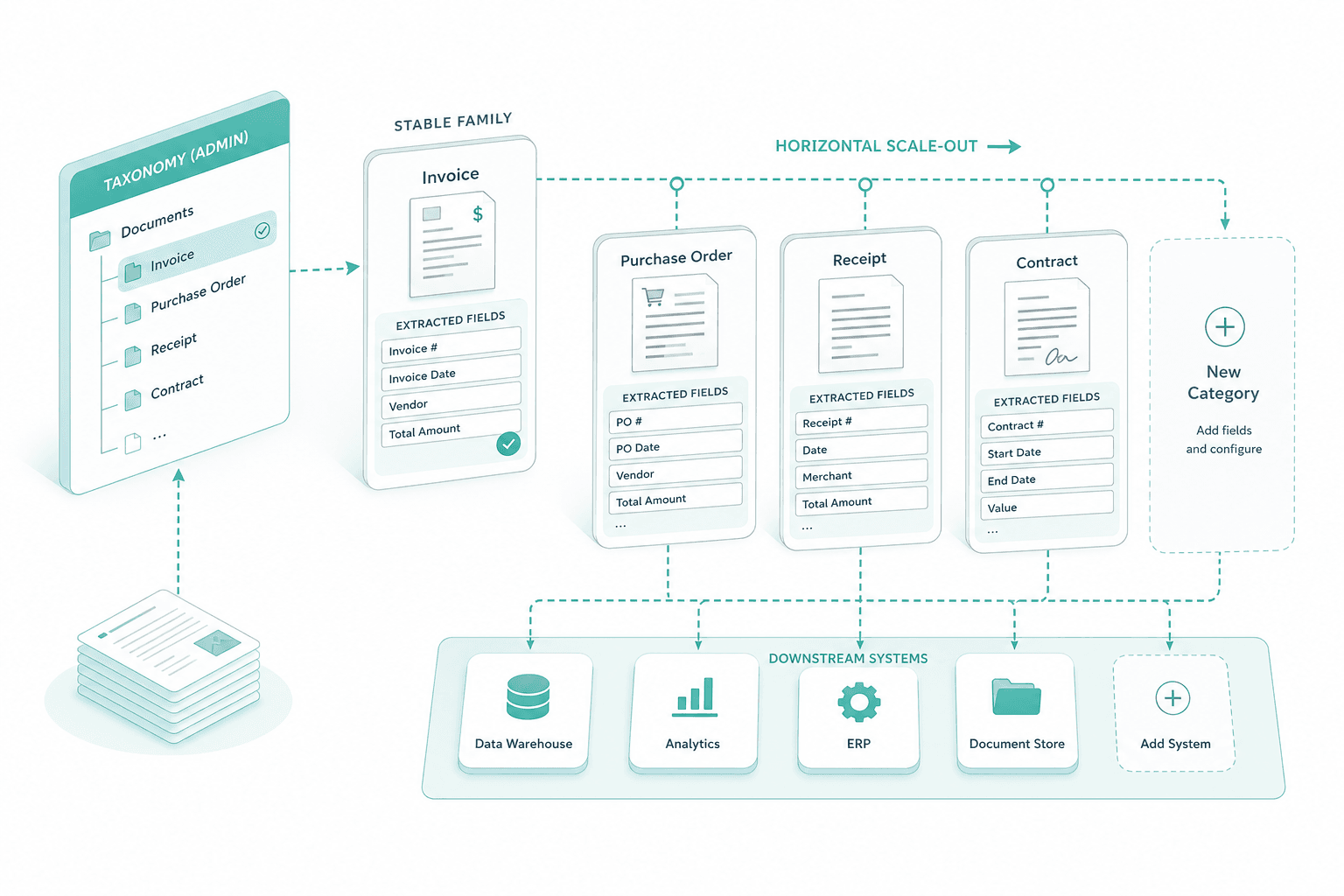
Horizontal scale-out
Once the first family is stable, we extend the rest of the taxonomy — new categories, field blocks, downstream systems. Because document classification follows the admin-defined schema, every new family is a configuration sprint.
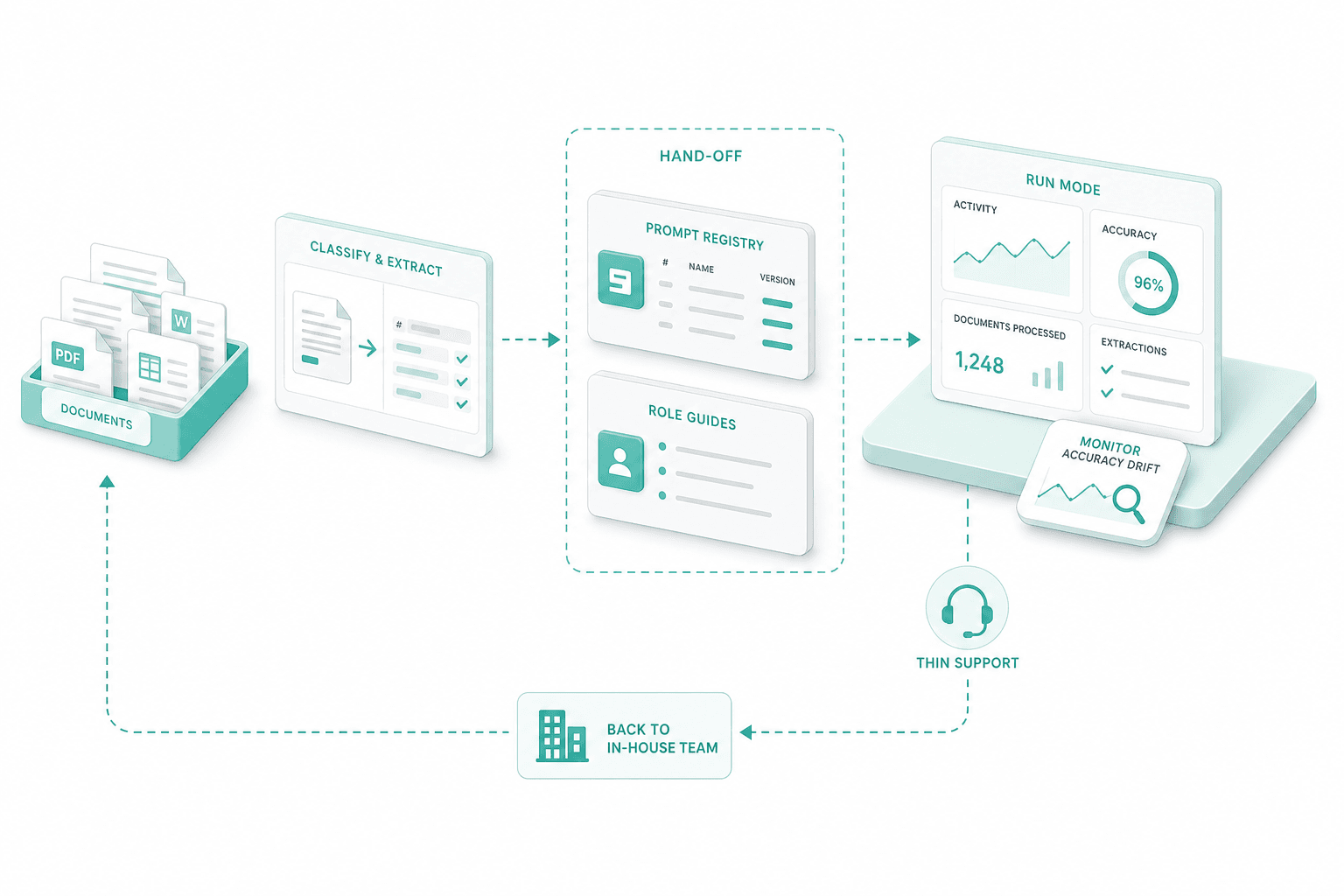
Hand-off and run mode
We hand over the prompt-registry for them to update prompts and also hand over role guides and a thin support engagement for them to monitor for accuracy-drift. Sometimes customers hand it back to their in-house team.
We start with your documents — sample sets per family, the downstream system that will consume the data, and the roles tasked with review. AI document automation begins with concrete schemas, not abstractions.
The pipeline runs end-to-end for one family: ingestion, classification, extraction, HITL review, downstream update. We used this intelligent document automation to process hundreds of thousands of SKUs at Weita and Sanitas.
Customize the review experience to fit the roles of individuals within your organization — who can see and edit which fields, what triggers an escalation, and where each handoff lands.
Once the first family is stable, we extend the rest of the taxonomy — new categories, field blocks, downstream systems. Because document classification follows the admin-defined schema, every new family is a configuration sprint.
We hand over the prompt-registry for them to update prompts and also hand over role guides and a thin support engagement for them to monitor for accuracy-drift. Sometimes customers hand it back to their in-house team.
Selected engagements
SWISS INSURANCE POC
Insurance Document Automation POC for a Swiss Back Office

How SAPIENTROQ built a schema-driven insurance document automation POC for a Swiss back office: Mistral OCR plus OpenAI JSON-mode extraction, schemas generated live from admin-defined categories, with provider-swappable AI behind a single interface.
View Case
SANITAS TROESCH
PIM Implementation with HITL AI for Sanitas Troesch
How SAPIENTROQ delivered a PIM implementation with a multi-agent HITL pipeline that ingests 200k+ supplier SKUs from PDFs, Excel and Jira into the Sanitas Troesch PIM with audit-grade governance.
View Case
Why this engine, not generic IDP
Schema you control, not a vendor template
Most IDP products ship with their own document taxonomy and force the customer to fit it. We flip that: your Category and FieldBlock model is the spec, and the AI binds to it. When operations adds a new document family in month six, you reconfigure it — no vendor ticket.
Built on Swiss delivery, not retrofitted
Weita, Sanitas Troesch, and the insurance AI POC all run the same engine in Swiss back-office operations. Bilingual EN/DE is baked in. Mistral OCR runs the two-pass classifier. Reverb provides the editing surface for AI document extraction. Same architecture, three verticals.
HITL where it matters, automation where it doesn't
We don't pretend the model is 100% right. Low-confidence extractions and unmapped categories surface in the role-gated review queue; approvals flow back into the prompt registry. High-confidence routine documents skip the queue entirely. AI document automation is verified, not assumed.
One engine, three verticals already proven
The same architecture covers Swiss wholesale PIM at Weita, construction-supply onboarding at Sanitas, and insurance claims at the POC. New verticals inherit the proven pattern — they extend the engine rather than rebuild it.
Audit-grade by construction
Every step is logged — category, prompt version, model ID, approver. The audit trail ships standard, not retrofitted. For FINMA, MDR and IVDR-sensitive customers, GDPR posture is part of the deployment template, including document classification provenance.
Frequently Asked Questions
OCR turns document images into characters. Intelligent document automation goes further — it classifies the document (invoice, order, delivery note), then extracts structured fields. Errors below threshold route to a reviewer; corrected data flows back into the pipeline.
PDFs (digital and scanned), image files, Word and Excel attachments, supplier datasheets, and email bodies. EN and DE are baked in; French and Italian extend via the prompt registry. Swiss-German is treated as DE, so all four Swiss languages share one pipeline.
Each extraction step carries a confidence rating. Below threshold, the data routes to a role-gated review queue (e.g. purchasing agent). The reviewer corrects or re-classifies; the correction is added to the prompt registry so similar mistakes degrade over time.
Yes. Category, FieldBlock and Field are admin-defined models — operations creates a new family with required fields and the reviewer role tied to it. Adding a new family for related documents is configuration, not code.
EU-hosted by default for GDPR. For FINMA, MDR or IVDR workloads we deploy on Swiss-resident servers, on-premises or customer-premises, and use a sovereign LLM track (Apertus) where content never reaches public endpoints.
We deliver a production-hardened IDP service for one document family within 8 weeks. Same classification and extraction quality and same HITL surface as a full rollout. Once the first family is stable, we extend to additional families on the same architecture.
Hyperscaler IDP products give you a managed extractor — but classification, FieldBlock authoring, HITL UI and downstream integration stay on you. We deliver the full pipeline with the taxonomy as the spec; the model layer remains swappable.
No. We can transfer the prompt registry, the Category and FieldBlock models as well as the roles and the deployment runbook to our customers. They normally keep us on a light support for the extractor contract, which then is provider-swappable.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ