Apertus RAG Integration
What an Apertus RAG engagement delivers
Connectors for corporate sources
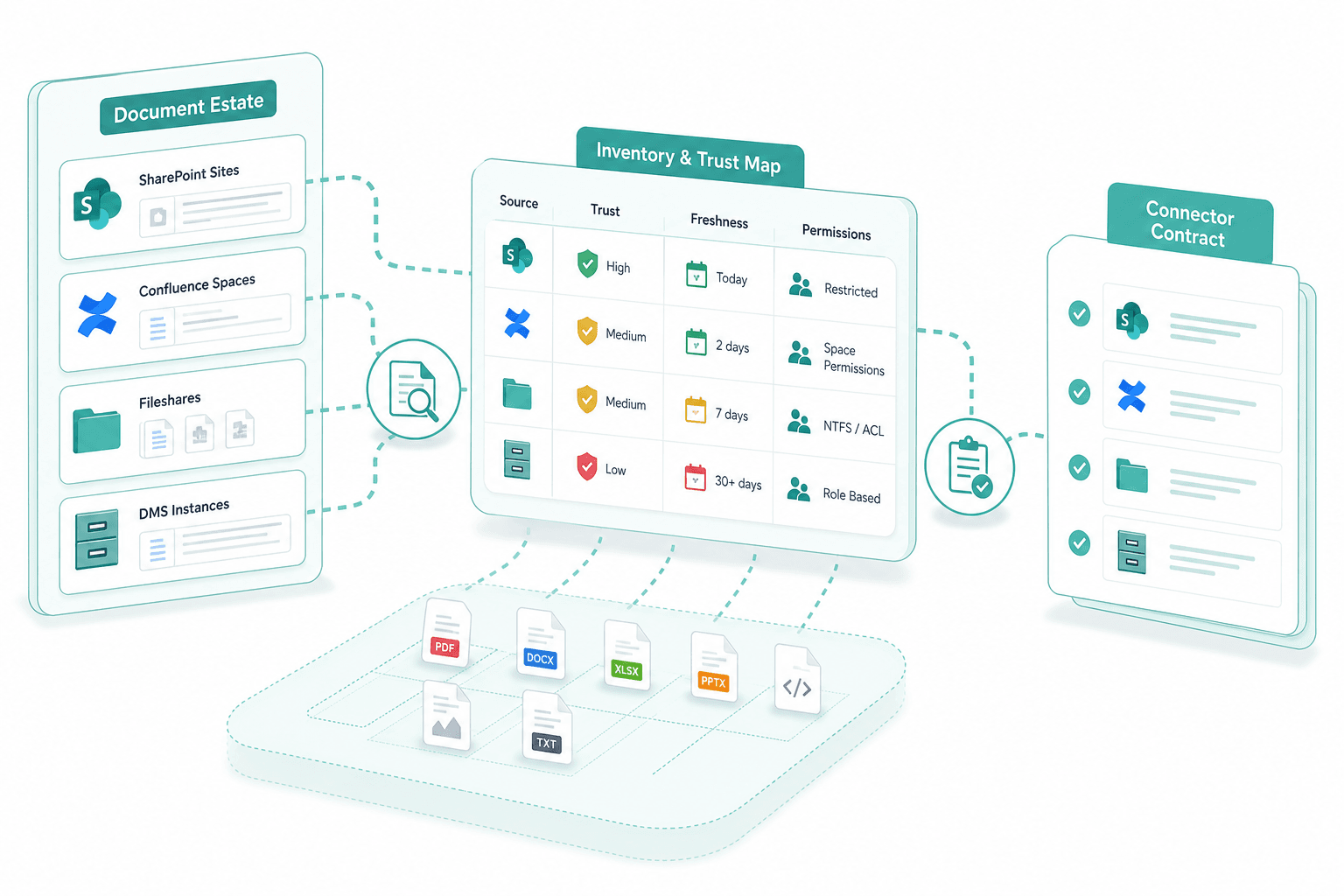
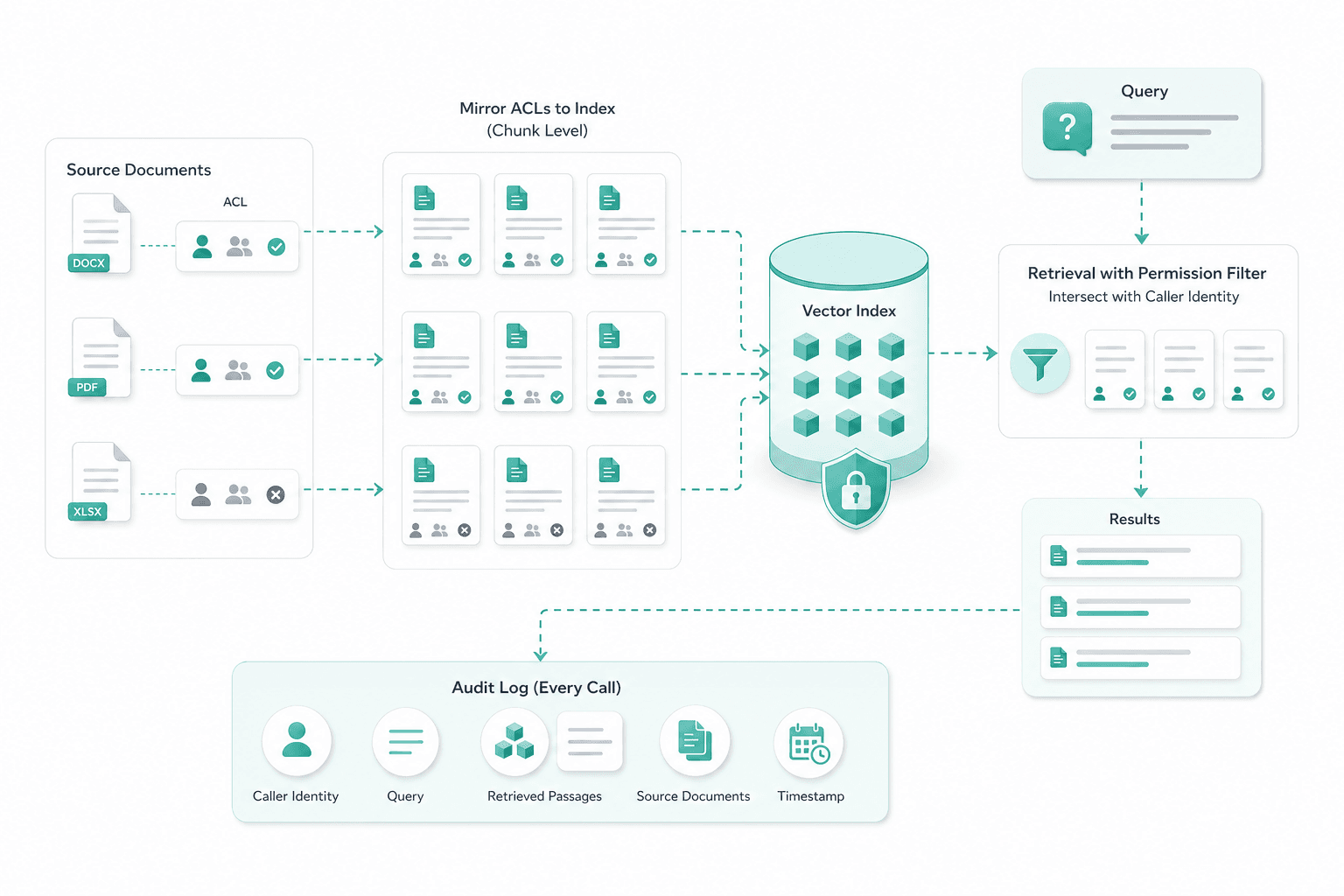
We connect Apertus to the document estate you already run — SharePoint Online and on-prem, Confluence Cloud and Data Center, SMB or NFS fileshare and the common DMS protocols including CMIS and direct REST. Each connector is a contract: incremental sync, permission carry-over from the source ACL and an audit log per fetch.
PostgreSQL with pgvector index
The retrieval index lives in PostgreSQL with pgvector, next to the application database. One backup window, one access policy, one operations team, no extra vendor surface to harden. We benchmark Qdrant, Pinecone and Weaviate per engagement and route there only if the corpus or query profile actually warrants it.
Evaluation set as a deliverable
Every Apertus retrieval-augmented generation engagement ships with an evaluation set — real questions from your team, with the right passages marked by a domain reviewer. We measure recall, precision and latency against it, tune chunking and reranking until the curve stabilises, then freeze the eval as a regression suite that ships with you.
Per-user permission filter
Permission metadata is attached to every chunk at index time, mirrored from the source ACL on SharePoint, Confluence or the DMS. At query time the retrieval filter intersects the candidate set with the caller's identity before any passage reaches Apertus. Nobody sees in chat what they could not open natively in the source system.
Fresh-index pipeline
Corporate repositories change every working day. A scheduled pipeline subscribes to source change events — Microsoft Graph deltas, Confluence webhooks, fileshare watchers, DMS event streams — and re-embeds only the documents that actually changed. Permission shifts ride the same channel, so a re-org reaches retrieval in minutes, not at month-end.
Generator wiring with Apertus
Apertus runs as the generator — 8B or 70B variant depending on the workload, served on vLLM or Text-Generation-Inference inside your hosting boundary. Retrieved passages carry citations, the prompt is versioned alongside the index, and answers link back to the originating SharePoint or Confluence document.
How we run RAG work
Inventory and trust map
We walk the document estate with your team — SharePoint sites, Confluence spaces, fileshares, DMS instances — and classify each source by trust, freshness and permission model. The result is the contract for the connector list.
Schema and chunking
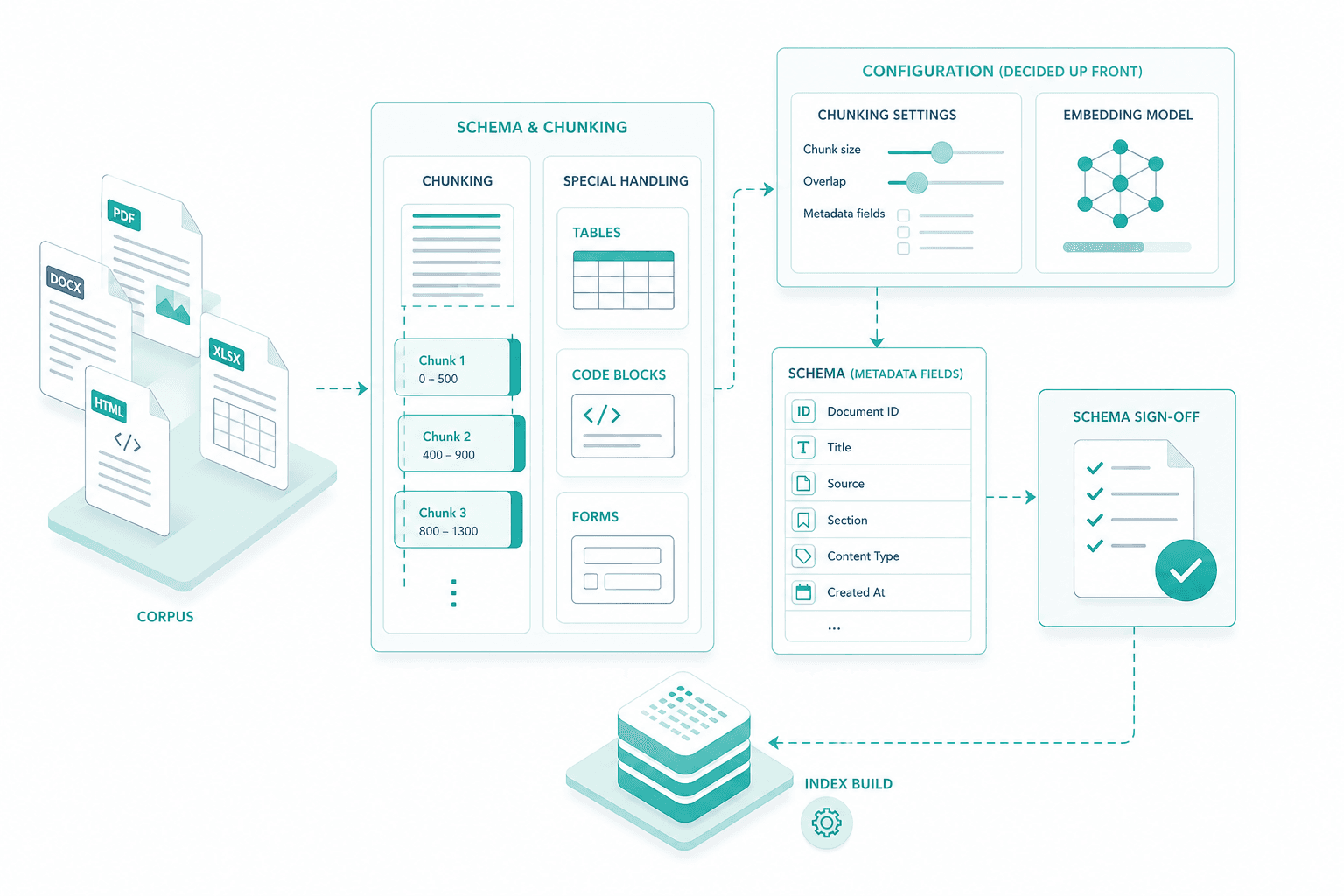
Chunk size, overlap, metadata fields and the embedding model are decided up front against your corpus. Tables, code blocks and forms get dedicated handling. The schema is signed off before index build.
Index build on pgvector
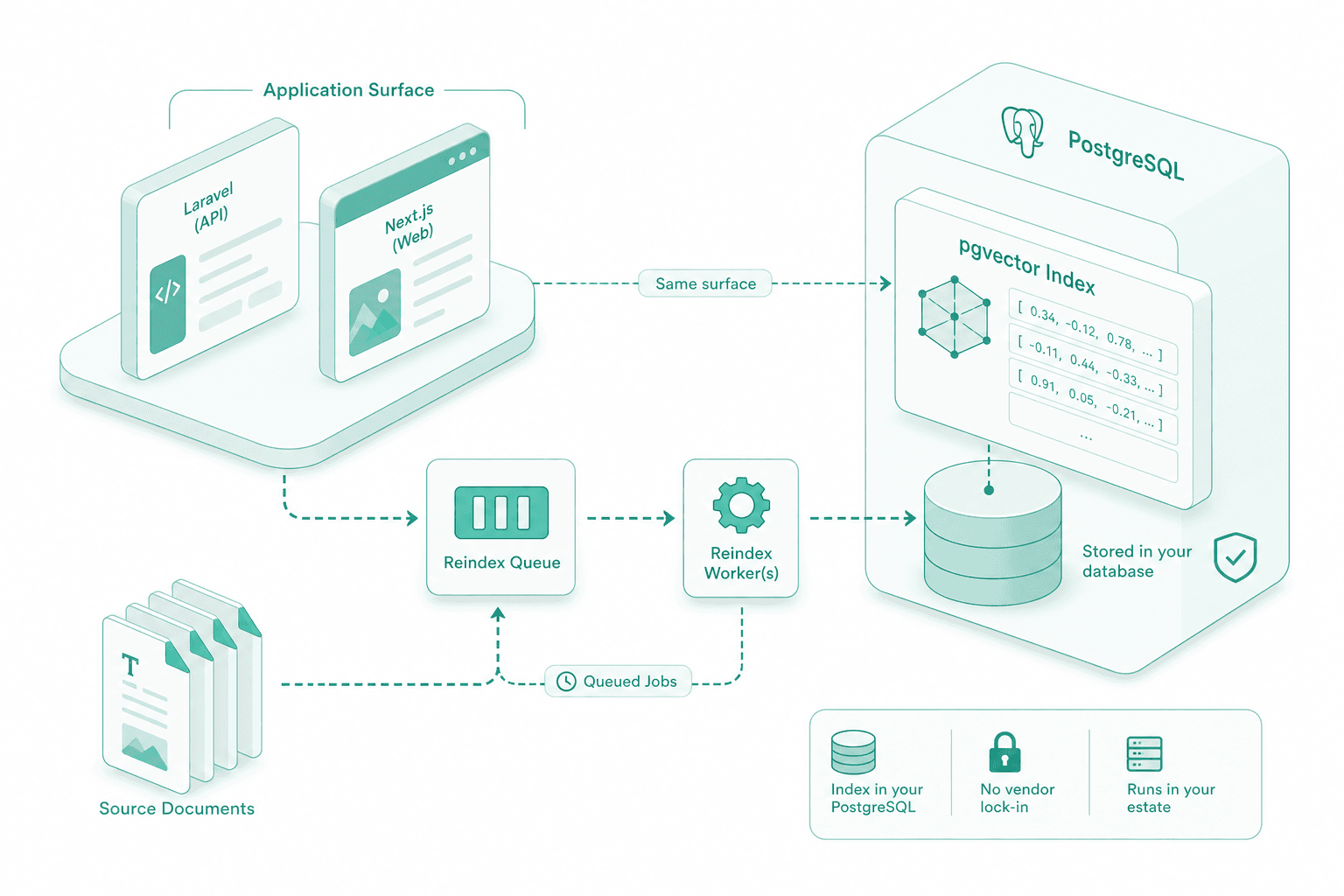
We build the production index in PostgreSQL with pgvector, behind the same Laravel and Next.js surface that already runs in your estate. Reindex jobs go on the queue. The index sits in your database, not a vendor tenant.
Evaluation loop
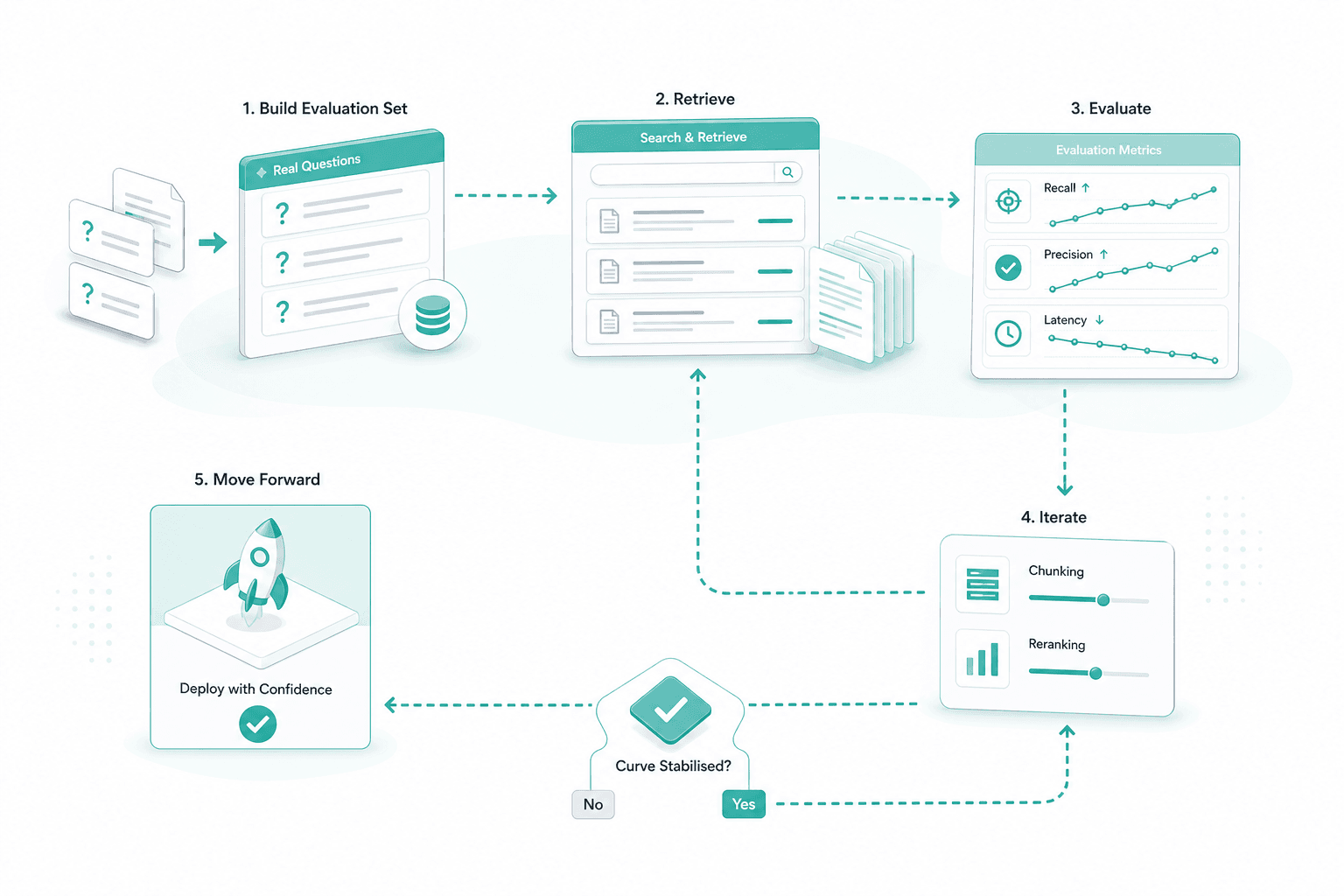
Your domain reviewers build the retrieval evaluation set from real questions. We measure recall, precision and latency, iterate on chunking and reranking, and only move forward when the curve stabilises.
Permission wiring
Source ACLs are mirrored onto the index at chunk level. The retrieval filter intersects candidates with the caller's identity at query time, and every call is logged with identity, passages and source documents for audit.
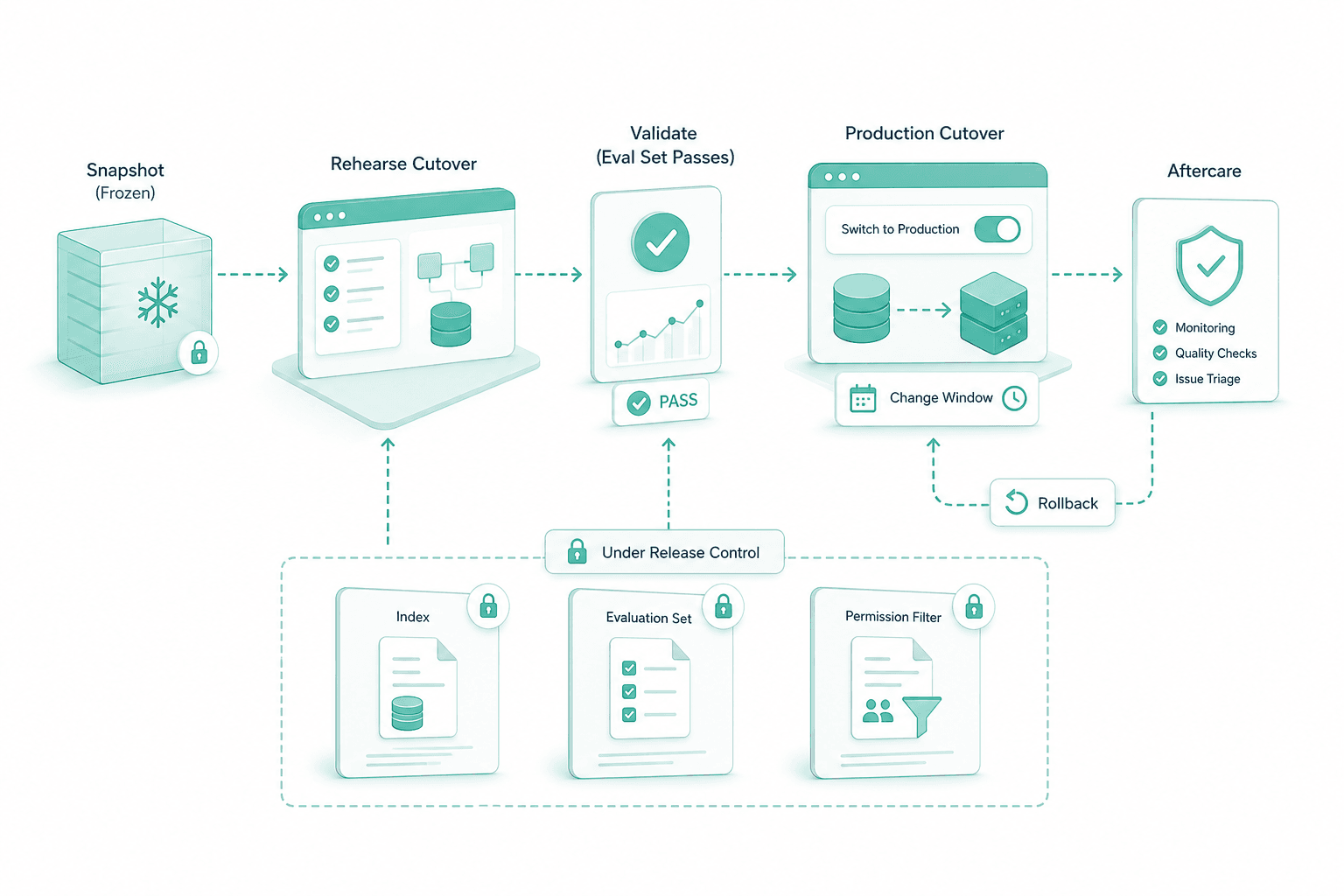
Cutover and aftercare
We rehearse the cutover against a frozen snapshot, validate the eval set passes, then run the production switch in a defined window with rollback. Index, evaluation set and permission filter stay under release control.
We walk the document estate with your team — SharePoint sites, Confluence spaces, fileshares, DMS instances — and classify each source by trust, freshness and permission model. The result is the contract for the connector list.
Chunk size, overlap, metadata fields and the embedding model are decided up front against your corpus. Tables, code blocks and forms get dedicated handling. The schema is signed off before index build.
We build the production index in PostgreSQL with pgvector, behind the same Laravel and Next.js surface that already runs in your estate. Reindex jobs go on the queue. The index sits in your database, not a vendor tenant.
Your domain reviewers build the retrieval evaluation set from real questions. We measure recall, precision and latency, iterate on chunking and reranking, and only move forward when the curve stabilises.
Source ACLs are mirrored onto the index at chunk level. The retrieval filter intersects candidates with the caller's identity at query time, and every call is logged with identity, passages and source documents for audit.
We rehearse the cutover against a frozen snapshot, validate the eval set passes, then run the production switch in a defined window with rollback. Index, evaluation set and permission filter stay under release control.
Selected engagements
BICOSY / BICO.CH
AI Shopping Assistant for bico.ch on WooCommerce

How SAPIENTROQ built BICOSY, an AI shopping assistant for the Swiss mattress retailer bico.ch — a NestJS backend with pgvector RAG, declared typed tools and a WordPress plugin that streams live WooCommerce events into the conversation.
View Case
Why run Apertus RAG with us
RAG is engineering, not a prompt
RAG is engineering, not a prompt. We treat the index, the retrieval evaluation set and the permission filter as production assets — same release discipline as a database migration. The model is the last component we change.
That discipline shapes every Apertus RAG engagement we run. Connector, chunking, index and permission filter all ship under release control before the model layer is tuned, so a model swap later is a configuration change rather than a project restart.
pgvector by default, alternatives by benchmark
The vector index lives next to the application database. One backup, one access policy, one operations team. We benchmark Qdrant, Pinecone and Weaviate per engagement and route there only when the corpus or query profile warrants it — never as a vendor partnership, always as a measurement against your data.
Permission filtering at retrieval time
Permission metadata is mirrored from the source ACL onto every chunk at index time and intersected against the caller's identity before passages reach the generator. A user never sees in chat a passage they could not have opened directly in SharePoint, Confluence or the DMS on a normal workday.
One platform across the Apertus estate
RAG is the engine behind document Q&A copilots, runs against on-prem Apertus or Swiss-resident hosting, and shares its retrieval discipline with our AI document automation track. Start at the Apertus hub or via AI consulting.
Frequently Asked Questions
A connector layer pulls documents from SharePoint, Confluence, fileshare or DMS into a staging store. We chunk, embed and index into PostgreSQL with pgvector, attach per-user permission metadata, then route the retrieved passages into Apertus as the generator with citations.
SharePoint Online and on-prem, Confluence Cloud and Data Center, SMB and NFS fileshare and the major DMS protocols — CMIS systems plus direct REST integrations. Each connector is a contract: incremental sync, ACL carry-over and an audit log entry per fetch.
pgvector is our default because the index lives next to the application database — one backup, one access policy, one operations team. We benchmark Qdrant, Pinecone and Weaviate per engagement and route there only if the corpus shape or the query profile actually warrants it.
Each engagement ships with a retrieval evaluation set — real questions from your team with the right passages marked. We measure recall, precision and latency against that set, tune chunking and reranking until the curve stabilises, then freeze the eval as a regression suite.
Permission metadata is attached to every chunk at index time, mirrored from the source ACL. At query time the retrieval filter intersects the candidate set with the caller's identity before passages reach Apertus, so nobody sees what they cannot open at source.
A scheduled pipeline subscribes to source change events — Microsoft Graph deltas, Confluence webhooks, fileshare watchers, DMS streams — and re-embeds only the affected documents. Permission shifts ride the same channel, so a re-org reaches retrieval in minutes, not at month-end.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ