MDR / IVDR Document AI
Where the engine supports your regulatory team
Technical documentation classification
Annex II technical documentation arrives from design, manufacturing, suppliers and post-market sources in mixed formats. The engine classifies each incoming document into your Annex II structure and the downstream review role, then surfaces gaps in the binder against your template. RA and QA decide what the gap means.
Post-market surveillance ingestion
Complaints, vigilance reports, field service notes and trend data feed into the PMS report template through one pipeline. The engine extracts the typed fields your PMS report expects, tags evidence against the device class, and routes anything below confidence to the reviewer. The narrative interpretation stays with the RA author.
Clinical evaluation file maintenance
Literature, post-market clinical follow-up data and equivalent-device evidence land in the clinical evaluation file with provenance preserved. The engine tags each evidence item, links it to the claim it supports, and flags gaps. The clinical reviewer signs off on every linkage.
Design history and technical file curation
DHF and TF documents accumulate across revisions. The engine indexes them by requirement, design output, verification and validation artefact, then preserves the cross-references as a queryable map. Re-ingestion of a revised document flags the downstream artefacts that need re-review.
Change-control trail on Annex II files
When a revised Annex II document is re-ingested, the engine diffs it against the prior version, surfaces the changed sections, and marks every linked downstream file as pending re-review. The change-control trail is logged with model version, prompt registry version and reviewer, so the evidence is preserved for audit.
Traceability matrix automation
Requirements, design outputs, verification and validation artefacts are linked across the binder. The engine maintains the traceability matrix as documents move through revision; QA reviews and approves the matrix at release milestones. The matrix is exportable in the format your notified body expects.
How a rollout actually runs
Regulatory document inventory with your RA lead
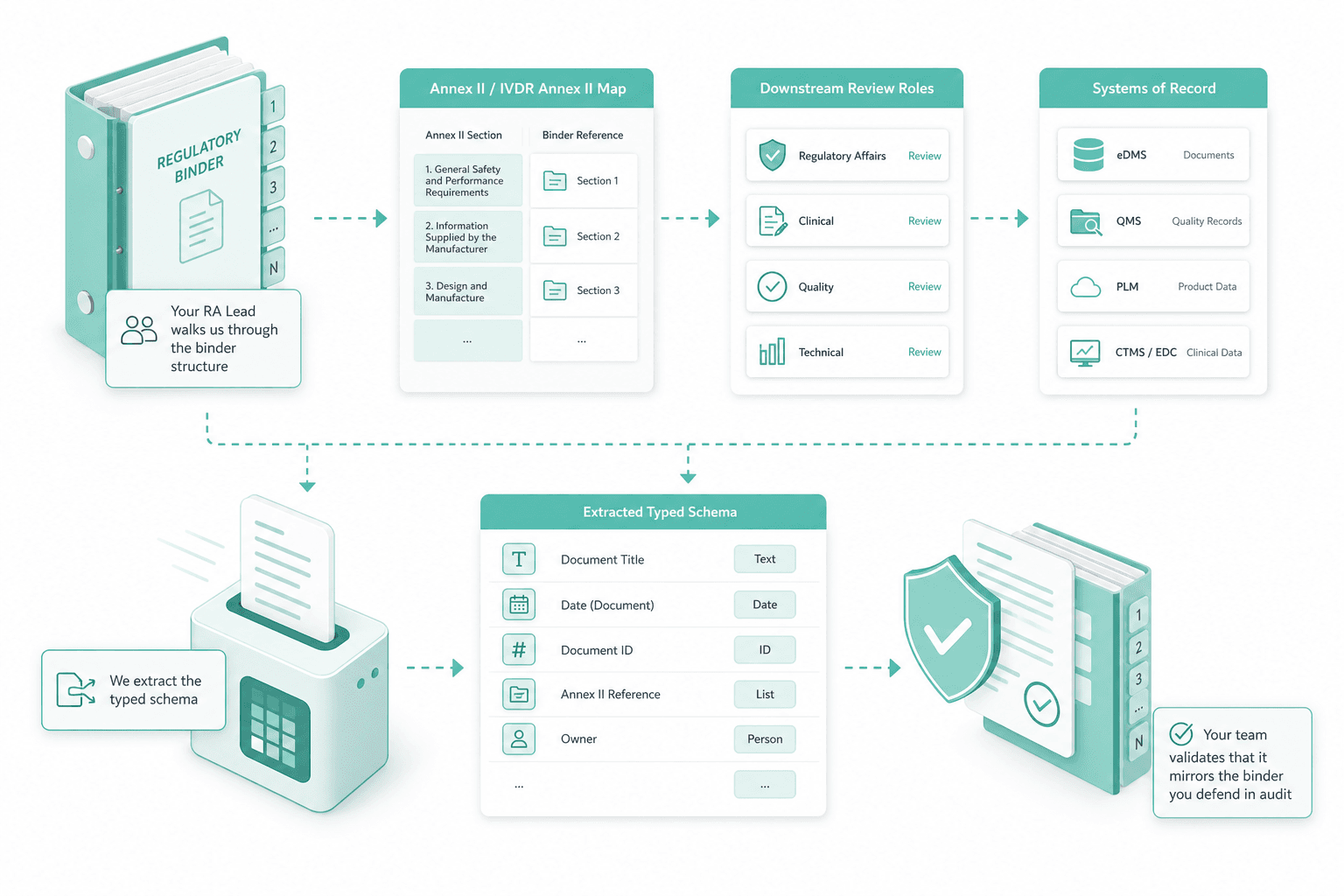
Your RA lead walks us through the binder structure, the Annex II / IVDR Annex II map, the downstream review roles and the systems of record. We extract the typed schema; your team validates that it mirrors the binder you defend in audit.
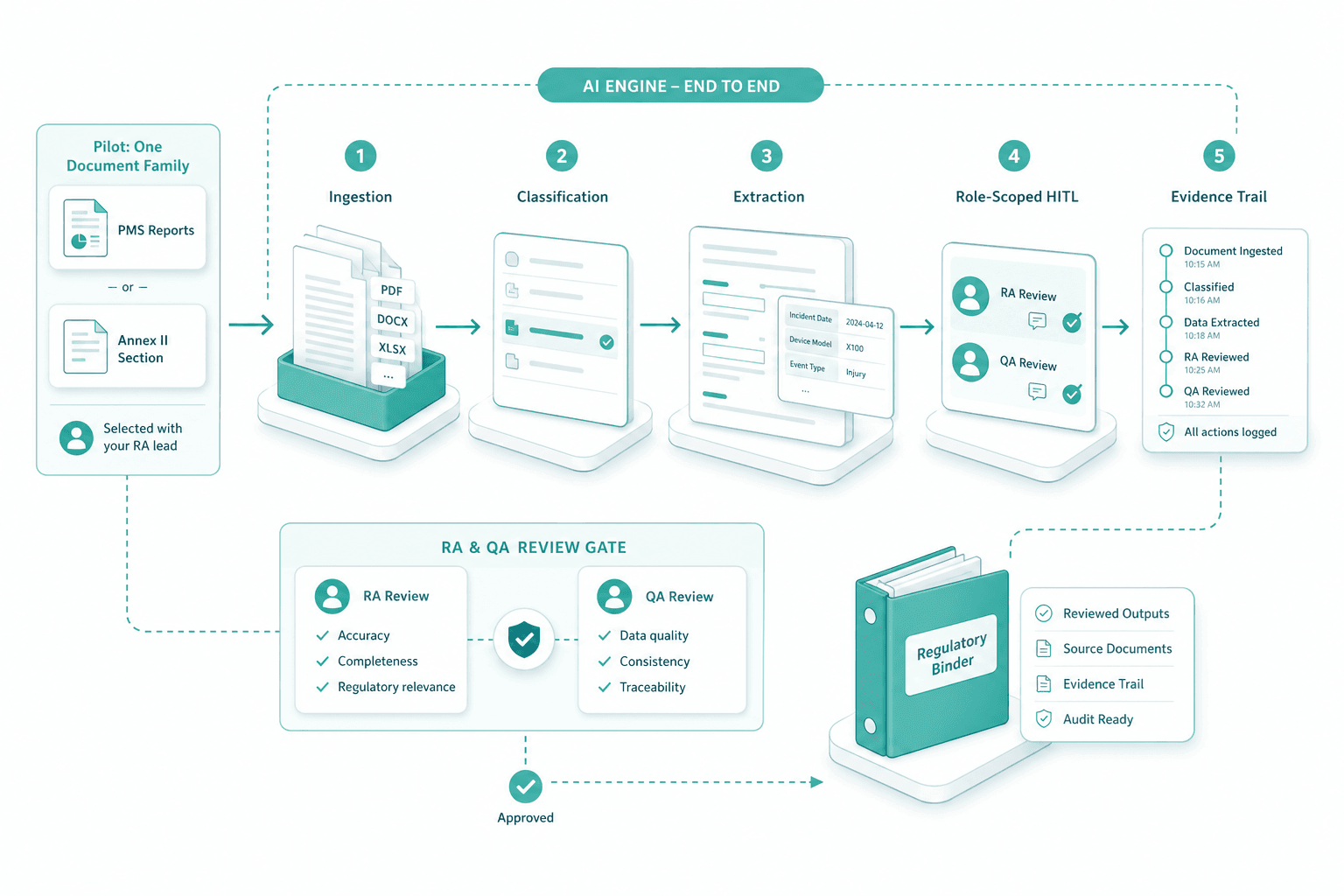
Pilot on one document family
We pick one family with your RA lead — typically PMS reports or one Annex II section. The engine runs end-to-end on real documents: ingestion, classification, extraction, role-scoped HITL, evidence trail. RA and QA review every output before it enters the binder.
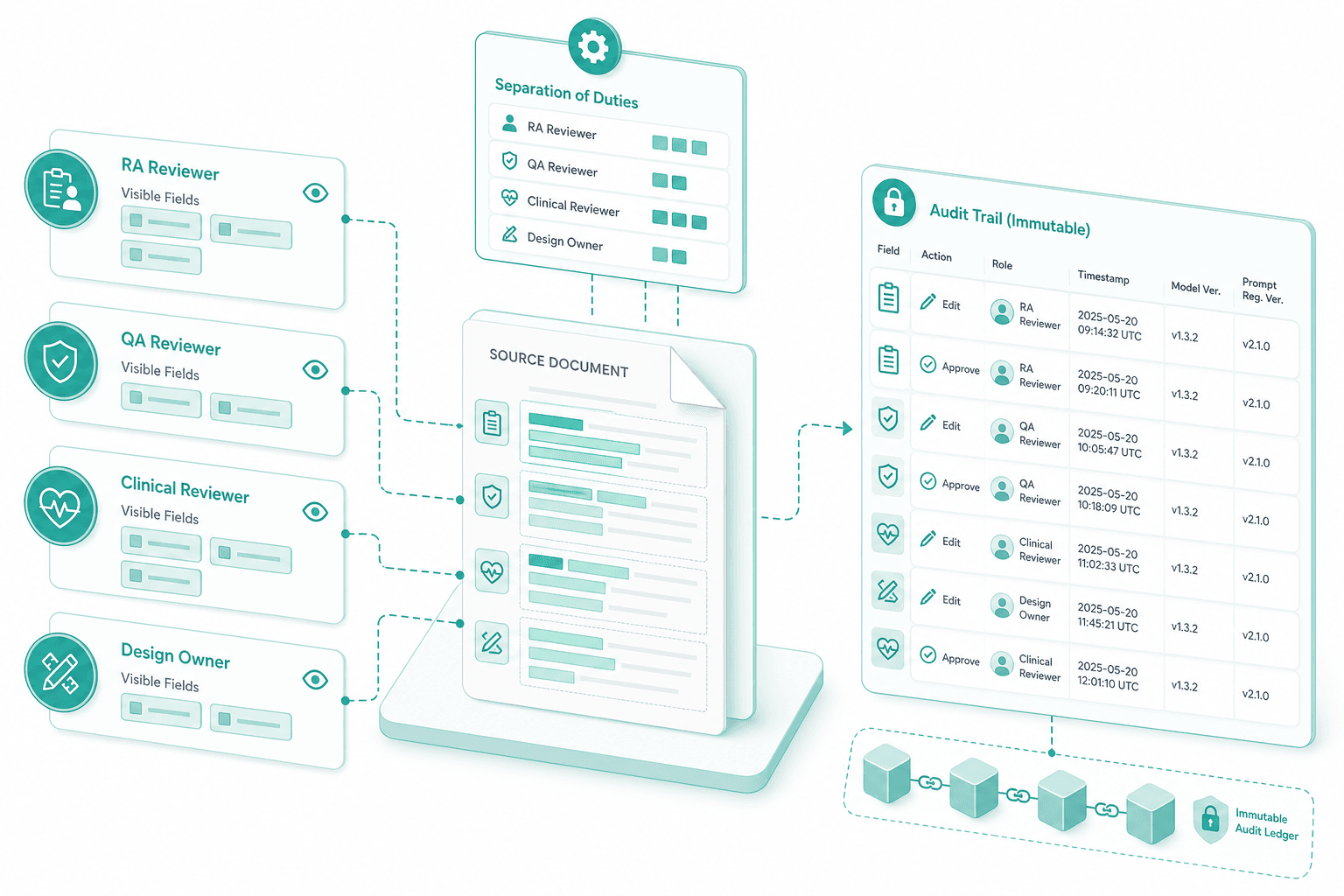
Role-scoped HITL with audit trail
RA reviewer, QA reviewer, clinical reviewer and design owner each see only the field blocks tied to their responsibility. Every edit, role, timestamp, model version and prompt registry version is logged immutably against the source document. Separation of duties is configured up front.
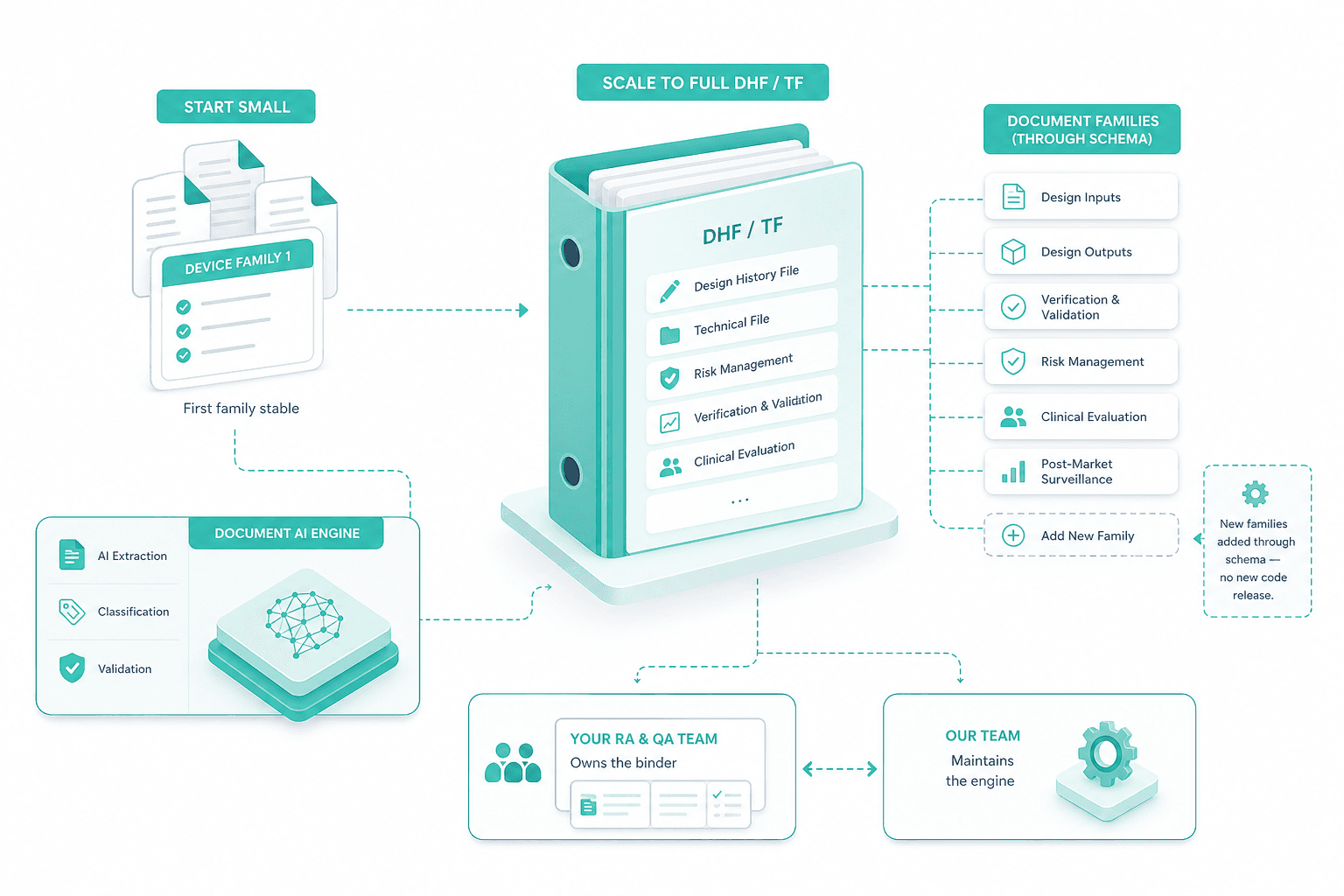
Scale to the full DHF / TF
Once the first family is stable, we extend the engine to the full design history file and technical file. New document families are added through the schema — no new code release. Your RA and QA team owns the binder; we maintain the engine.
Your RA lead walks us through the binder structure, the Annex II / IVDR Annex II map, the downstream review roles and the systems of record. We extract the typed schema; your team validates that it mirrors the binder you defend in audit.
We pick one family with your RA lead — typically PMS reports or one Annex II section. The engine runs end-to-end on real documents: ingestion, classification, extraction, role-scoped HITL, evidence trail. RA and QA review every output before it enters the binder.
RA reviewer, QA reviewer, clinical reviewer and design owner each see only the field blocks tied to their responsibility. Every edit, role, timestamp, model version and prompt registry version is logged immutably against the source document. Separation of duties is configured up front.
Once the first family is stable, we extend the engine to the full design history file and technical file. New document families are added through the schema — no new code release. Your RA and QA team owns the binder; we maintain the engine.
Selected engagements
SWISS INSURANCE POC
Insurance Document Automation POC for a Swiss Back Office

How SAPIENTROQ built a schema-driven insurance document automation POC for a Swiss back office: Mistral OCR plus OpenAI JSON-mode extraction, schemas generated live from admin-defined categories, with provider-swappable AI behind a single interface.
View Case
Why an audit-grade engine matters here
Every decision logged with its model and prompt version
When a notified body or internal audit asks why a document was classified the way it was, the engine answers with the model ID, the prompt registry version active at the time, the reviewer and the timestamp. The evidence is not reconstructed after the fact; it is captured at decision time and preserved against the source document.
Reproducible inference at audit time
Each classification or extraction event snapshots the model and prompt registry entry it ran against. Months later, the same document can be re-run against the same snapshot and produce the same output. Reproducibility is part of the evidence trail, not a separate feature.
Role-scoped HITL with separation of duties
RA, QA, clinical and design reviewers each see only the field blocks tied to their responsibility. The reviewer who edits a field cannot be the reviewer who approves it. Separation of duties is configured against the role model, not bolted on afterwards.
Data residency in CH or EU, sovereign LLM available
The engine deploys on AWS Zurich, EU regions or your own infrastructure. Where content cannot reach a public model endpoint, the Apertus sovereign-LLM track runs the same pipeline against a Swiss-hosted model. Document content stays inside the jurisdiction your binder requires.
What this engine does not do
It does not make a device compliant. It does not replace the RA function, the QA function or the clinical reviewer. It does not represent SAPIENTROQ as a notified body or a regulatory consultancy. It supports the team that owns those calls.
Frequently Asked Questions
No. Regulatory compliance under MDR (EU 2017/745) and IVDR (EU 2017/746) is decided by your RA and QA team, your notified body and your conformity assessment. The engine supports your team in preparing and maintaining the documentation that backs those decisions. The regulatory call stays with the people qualified to make it.
By default the engine deploys on EU-hosted infrastructure. For CH-resident binders we deploy on AWS Zurich, on customer-premises or on a Swiss-hosted private cloud. Where content cannot reach a public model endpoint, the Apertus sovereign-LLM track runs the pipeline against a Swiss-hosted model. Data residency is part of the deployment template.
Every classification or extraction event is logged with the model ID, the prompt registry version active at the time, the reviewer role, the user and the timestamp. The log is immutable and tied to the source document. At audit time the trail is queryable per document, per field and per revision — no after-the-fact reconstruction.
When a revised Annex II document is re-ingested, the engine diffs it against the prior version, surfaces the changed sections and marks every linked downstream file as pending re-review. The reviewer queue routes the affected items to the right role. The change and the re-review are logged as part of the evidence trail.
The engine writes into your QMS through its API or document repository, not in place of it. Categories, document types and field blocks are mapped to the QMS schema at discovery. The QMS remains the system of record; the engine prepares and maintains the documentation that lands there.
The extractor contract is provider-swappable. Model and prompt registry are versioned as data, not hard-coded. Prompt registry, category and field-block configuration, role definitions and the runbook are handed over to the customer. The pipeline runs without us.
Customer documents are not used to train shared models. Where a hosted model is used, the deployment uses the no-training endpoint of the provider. Where a sovereign LLM is required, Apertus runs on Swiss infrastructure under the customer's contract. The data path is documented per deployment.
No. SAPIENTROQ builds and operates the document AI engine. We do not interpret MDR or IVDR for you, we do not represent you to a notified body and we do not certify your device. Where you need a regulatory consultancy, we work alongside the one you have chosen.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ