SWISS INSURANCE POC
Insurance Document Automation POC for a Swiss Back Office
About the Project
How SAPIENTROQ built a schema-driven insurance document automation POC for a Swiss back office: Mistral OCR plus OpenAI JSON-mode extraction, schemas generated live from admin-defined categories, with provider-swappable AI behind a single interface.
Used technologies:
Country
Switzerland
Industry
Insurance
Development Hours
500+
Team Size
3-4
Challenge
A Swiss insurance back office receives heterogeneous documents every working day: a 40-page scanned PDF claim, an Excel premium list, a photographed handwritten cancellation, a German Leistungsabrechnung emailed by a provider. Operators read each one by hand, decide what category it belongs to, and re-key the relevant fields into the system of record.
The pain is twofold. Manual reading is slow and inconsistent across operators, and every new document family — a new sub-category, a new typed field — turns into an engineering ticket. The operations team wanted to validate, end-to-end on real documents, that insurance document automation could be done schema-first: new families added by config, not code, and AI providers swappable without a rewrite.
Architecture
We delivered the POC as a single Laravel 12 plus React 19 monorepo. The backend is plain Laravel with Pest for tests, the frontend is Inertia-style React served through Vite, Ziggy handles named routes shared with PHP, and Laravel Reverb runs as a first-party WebSocket server for live progress streaming.
Supporting infrastructure stays boring on purpose: Redis for queues and cache, Docker for local and CI parity, Swagger for the document extraction API, Radix UI and shadcn/ui on the frontend. The whole stack is one repository, one deploy artefact, one set of credentials — a deliberate choice for a POC engagement where the team needs to read every line before any production rollout. See our document automation hub for how this pattern scales beyond a single POC.
Schema-driven extraction
The core idea behind this engagement: the extraction schema is not hard-coded. Administrators define Categories (for example Leistungsabrechnung, Gesundheitspravention, Kundigung), sub-categories (Arzt, Medikament, Laboranalyse), file blocks (Patient, Leistungserbringer, Rechnungssteller) and typed fields, all through the admin UI.
At ingest time, MakeMetadataSchemaAction and MakeCategorySchemaAction walk those Eloquent models — Category, FieldBlock, Field, File, FileMetadata, FileDetail, FileProcessingStage — and assemble the JSON schema the LLM has to fill. Onboarding a new document family is a no-code operation. This is the same typed-field discipline we use on the master data management side, applied to inbound documents instead of master records.
Provider-swappable AI layer
OCR and extraction live behind a single AIExtractor contract. The OCR implementation calls Mistral OCR for page-level text recovery; the extractor implementation calls OpenAI in JSON mode through openai-php/laravel. Both are concrete classes bound to the contract at the container level.
The point is governance, not novelty: if Mistral OCR is replaced, or OpenAI is swapped for a Swiss-hosted model on the Apertus track later, the call sites do not change. Schema-driven extraction stays the same, the staged pipeline stays the same, only the binding moves. We frame the same principle in our AI consulting work — interface first, vendor second.
Staged async pipeline and live progress
Every file moves through a deterministic sequence of stages: prepare file, recognize images, extract metadata, extract details, save details, notify. The prepare stage branches on file type — poppler utilities rasterize PDFs to page images, single JPGs go straight through — so a 40-page PDF and a one-page scan land in the same downstream pipeline. Each stage is its own queued job and can be retried in isolation.
While the pipeline runs, Laravel Reverb broadcasts a FileProcessingEvent at each transition. The React dashboard subscribes via WebSocket and shows the operator exactly which stage their document is in, on which page, without polling. The document extraction API and the live dashboard read from the same event stream, so REST clients and humans see the same state.
Delivered value and what comes next
The POC delivered on the trust questions the back office set out to answer: heterogeneous incoming documents turn into clean structured records, manual reading time is cut, consistency across document families improves, and new families are added by config rather than by an engineering sprint. The same primitives extend naturally into ai claims processing, where extracted typed records feed a downstream claims engine. Operators see live progress per file instead of waiting on a black box.
This is a proof-of-concept engagement, not a production rollout — that is the point. The codebase, the schema-driven extraction primitives, the AIExtractor contract and the staged pipeline are now a clean baseline the team can take into production on their own terms. Plan your document intake POC with SAPIENTROQ — book a discovery call and bring one real document family; we will scope a POC against it the same week.
Solutions
Solutions in this engagement
- Single Laravel 12 plus React 19 monorepo with Reverb WebSockets
- Schema built at runtime from admin Categories, blocks and fields
- AIExtractor contract — Mistral OCR and OpenAI behind one interface
- Staged async pipeline — prepare, recognize, extract, save, notify
Delivered Value
- Unstructured incoming documents turned into clean records
- Manual reading time cut for the back office operators
- New document families added by config, not by engineering
- Live per-file progress visible to operators in real time
More Projects

WEITA AG
Interim CIOWeita, a well-established Swiss wholesale company, operates in the healthcare, cleaning, safety and hygiene, and non-food sectors.
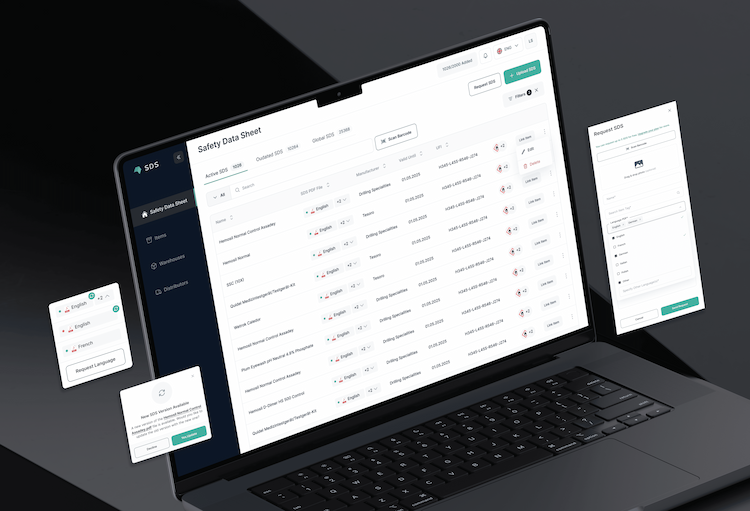
ProductRoom
AI-Powered SDS Management for ProductRoomHow SAPIENTROQ built ProductRoom — a safety data sheet management platform that extracts structured data from any layout with ai document extraction, makes the library searchable across languages, and keeps every sheet current with automatic sds renewal driven by direct manufacturer outreach.
BICOSY / BICO.CH
AI Shopping Assistant for bico.ch on WooCommerceHow SAPIENTROQ built BICOSY, an AI shopping assistant for the Swiss mattress retailer bico.ch — a NestJS backend with pgvector RAG, declared typed tools and a WordPress plugin that streams live WooCommerce events into the conversation.
Frequently asked about this engagement
Every file enters the same ai document intake pipeline. Poppler rasterizes PDFs or JPGs pass through, so a 40-page scan and a single image both become normalized page images. Mistral OCR recovers text, then OpenAI fills the category schema in JSON mode.
Administrators create a new Category in the admin UI, add sub-categories, define file blocks (Patient, Leistungserbringer) and the typed fields per block. MakeMetadataSchemaAction and MakeCategorySchemaAction assemble the schema from those rows. No code change, no deploy.
OCR and extraction sit behind one AIExtractor contract. Current bindings are Mistral OCR for the OCR pass and OpenAI through openai-php/laravel for the extractor, but the call sites only know the interface. Swapping provider is a binding change, not a rewrite.
Laravel Reverb runs as a first-party WebSocket server and broadcasts a FileProcessingEvent at each pipeline transition: prepare, recognize, extract metadata, extract details, save, notify. The React dashboard shows the operator which stage and page, in real time.
The schema is assembled from Eloquent models: Category, FieldBlock, Field, FileMetadata, FileDetail. MakeMetadataSchemaAction walks the category and blocks; MakeCategorySchemaAction adds sub-categories and typed fields. Admin changes flow into the next ingest.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ