Prototype Hardening Sprint
What we harden in your prototype
Audit, then a fixed-scope fix sprint
AI coding tools ship a working demo fast — and the same speed leaves auth scaffolding, missing tests, and database shortcuts behind. We run a one-week audit on the actual codebase, map the gaps that block production, and then run a 6-12 week fix sprint to close them. Scope is fixed after the audit. The client owns the code throughout, and the engagement ends with a production handoff or a continued retainer.
Real auth and access control
AI-generated auth scaffolding gets you a login form and a token, not a production session model. We refactor onto real RBAC, JWT or server-session with proper expiry and rotation, password reset and email verification flows, optional MFA, and audit logging on every privileged action. Permission checks move out of the UI and into the API where they belong.
Security audit and OWASP hardening
Input validation, secrets rotation, rate limiting, CORS, CSP, dependency upgrades, and a sweep against the OWASP Top 10. Secrets that ended up in the client bundle or the public repo get rotated and moved into a real secrets manager. CSP and rate limits get tuned to the real traffic shape, not copied from a template.
Database and data-model refactor
The typical AI-coded prototype puts everything in one wide JSON column and queries it on every render. We refactor into normalised tables with foreign keys and indexes, write the migrations that get you from the current state to the target schema without downtime, and fix the N+1 patterns that will fall over at real load.
Test coverage where there was none
Most vibe-coded prototypes ship with zero tests. We seed unit tests around the business logic, integration tests around the API and database boundary, and end-to-end tests for the critical user flows. The goal is not 100 percent coverage — it is a safety net that lets the team ship the next change without breaking the production paths you depend on.
CI/CD, observability and scaling readiness
Real deploy pipelines with environment separation (local, staging, production), secrets management, and an observability stack — logs, traces, errors and basic SLOs. We load test the hot paths, add a caching strategy where it matters, and stand up a queue and background-job architecture so the prototype stops doing real work on the request thread.
How we harden a prototype
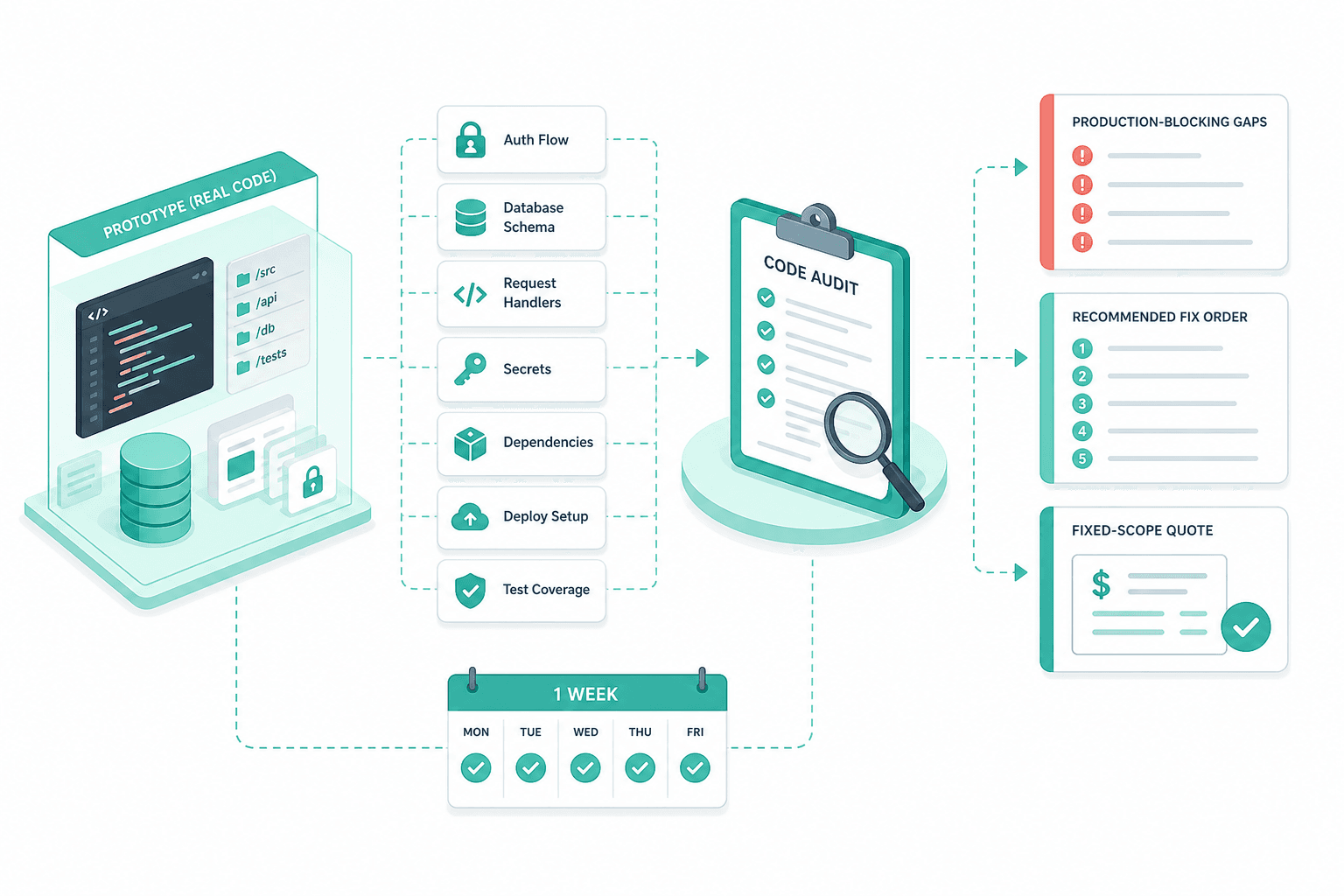
One-week audit on the real code
We read the prototype the way an incoming engineering hire would — auth flow, database schema, request handlers, secrets, dependencies, deploy setup, test coverage. Output is a written audit with the production-blocking gaps, the recommended fix order, and a fixed-scope quote for the sprint that follows.
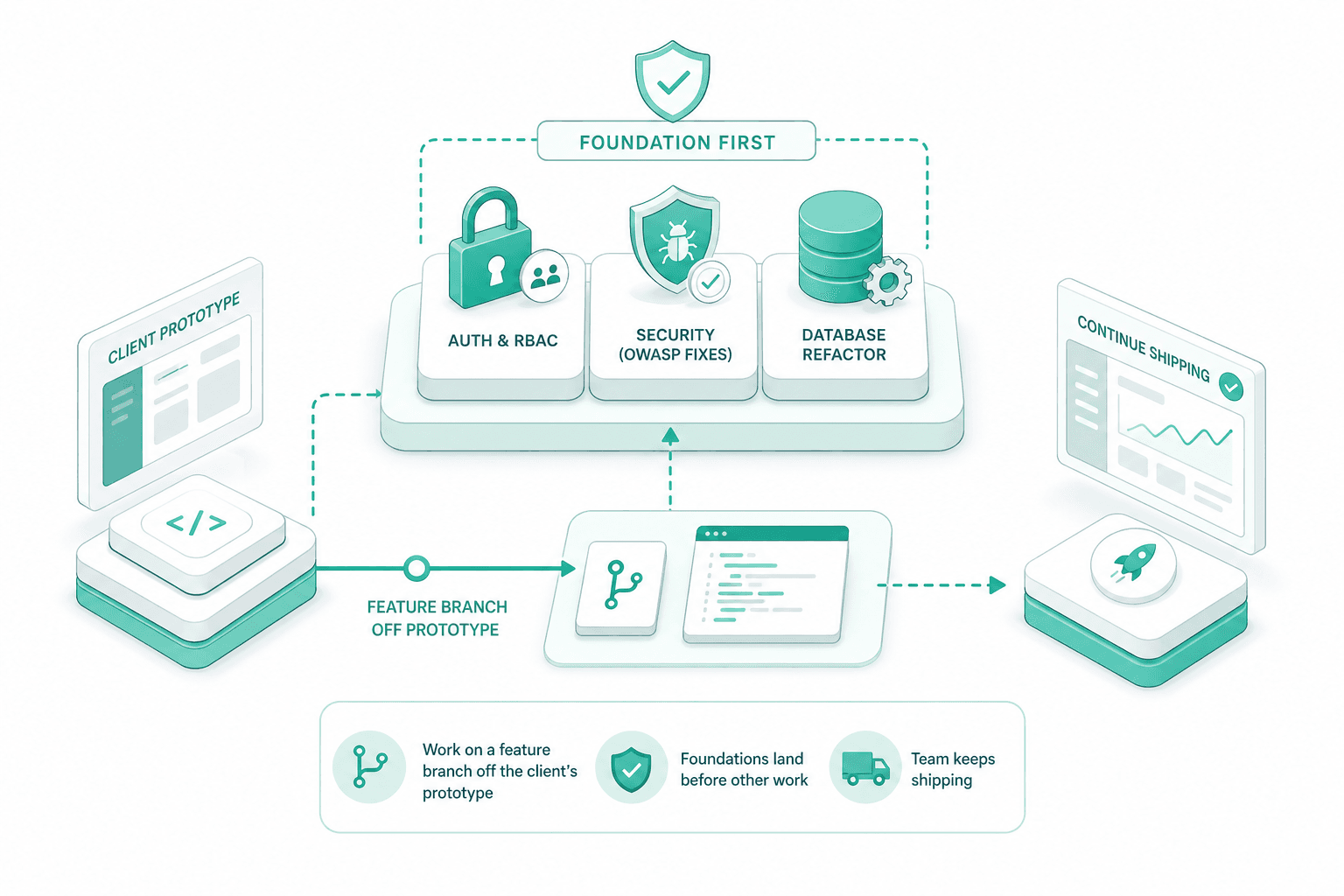
Foundation first — auth, security, database
The first weeks of the sprint go to the foundations that everything else sits on. Real auth and RBAC, OWASP fixes, and the database refactor land before we touch the rest. We work on a feature branch off the prototype the client has, not a parallel rewrite, so the team can keep shipping.
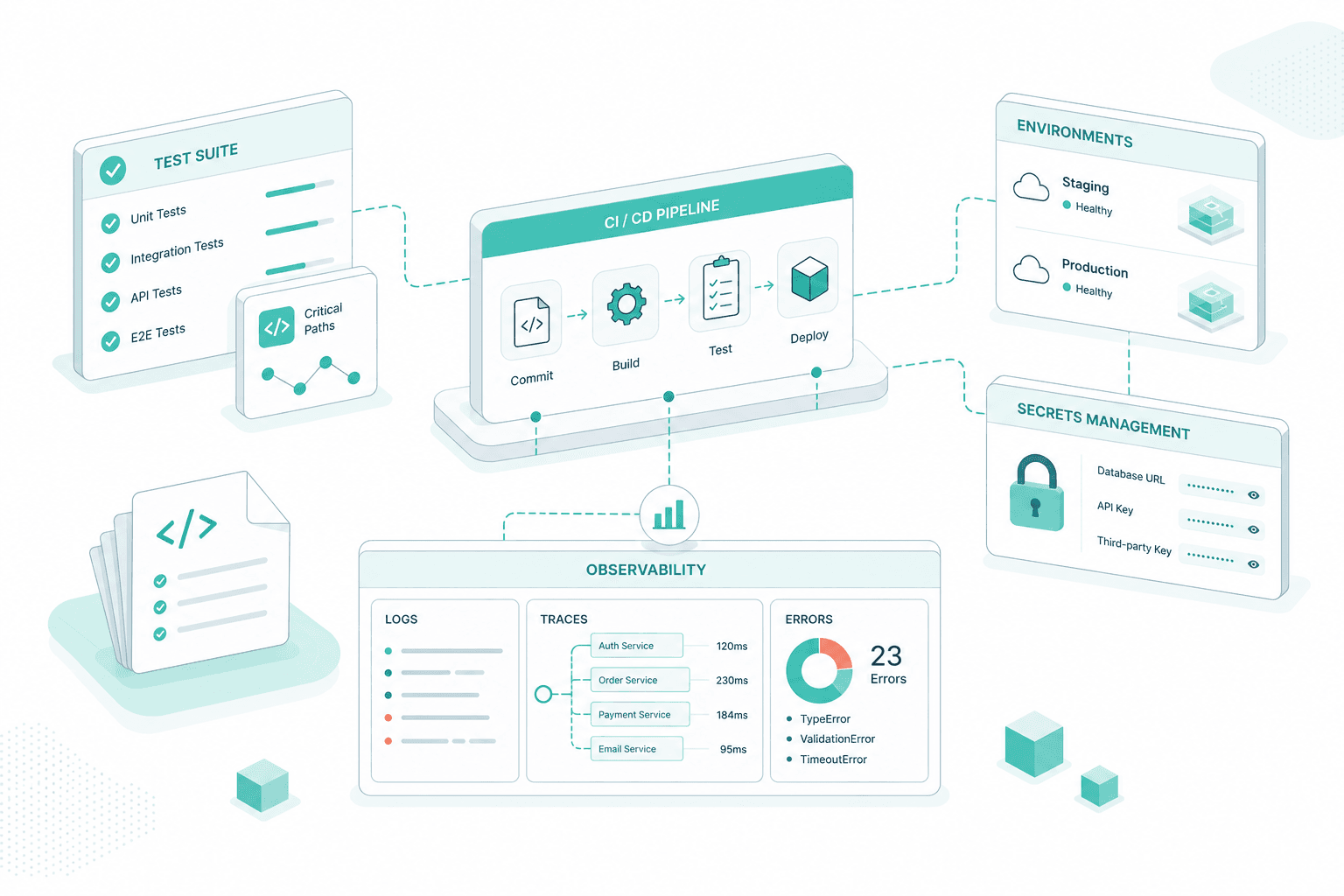
Tests, CI/CD and observability
Once the foundations are stable, tests, deploy pipelines and observability come online. We seed the test suite around the critical paths first, wire it into the CI, and set up staging and production environments with real secrets management and basic logging, traces and error reporting.
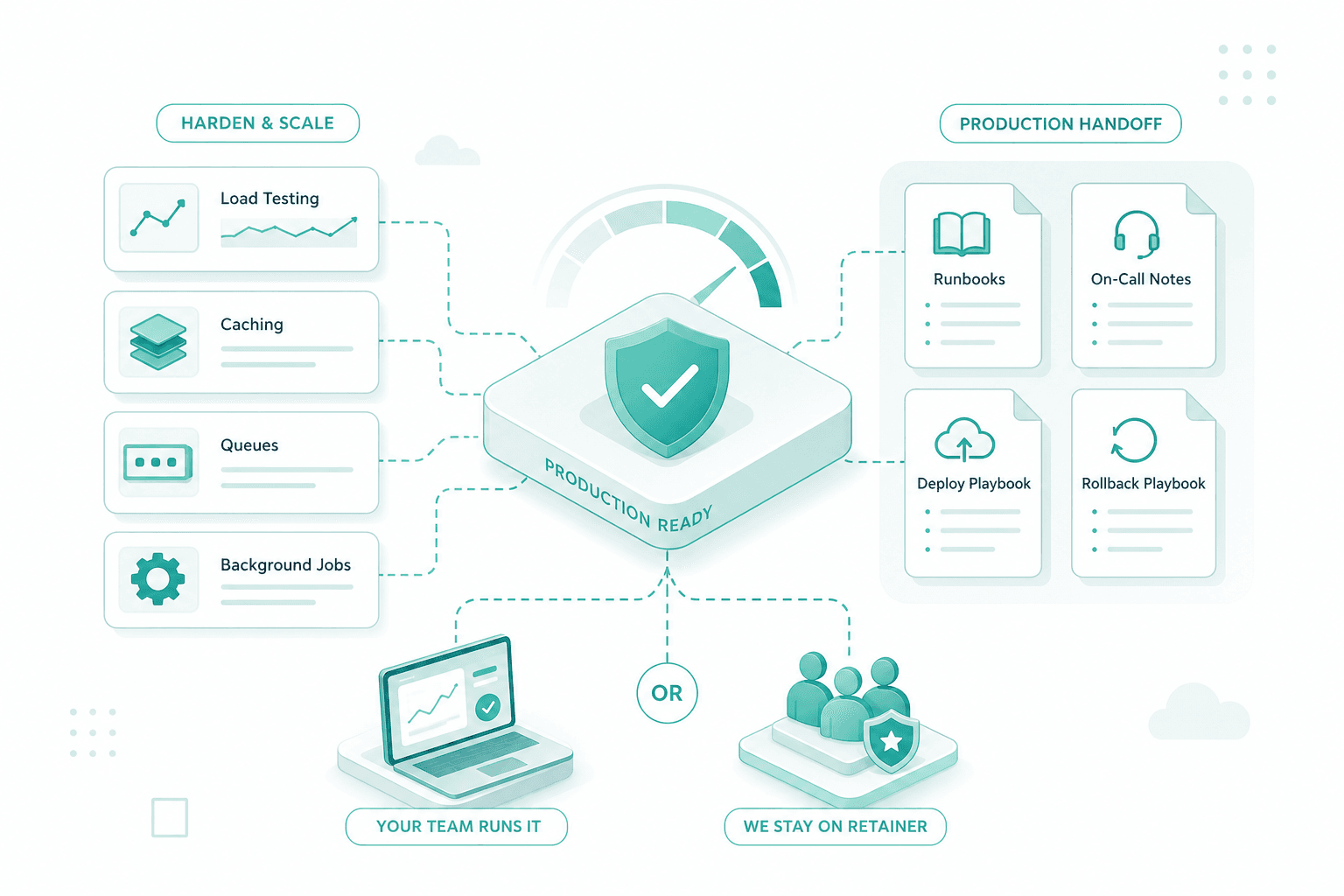
Scaling readiness and production handoff
The final stretch covers load testing, caching, queues and background jobs — whatever the prototype needs to hold up at the next traffic step. We close with a production handoff: runbooks, on-call notes, deploy and rollback playbooks. After that the founder team can run it themselves or keep us on retainer.
We read the prototype the way an incoming engineering hire would — auth flow, database schema, request handlers, secrets, dependencies, deploy setup, test coverage. Output is a written audit with the production-blocking gaps, the recommended fix order, and a fixed-scope quote for the sprint that follows.
The first weeks of the sprint go to the foundations that everything else sits on. Real auth and RBAC, OWASP fixes, and the database refactor land before we touch the rest. We work on a feature branch off the prototype the client has, not a parallel rewrite, so the team can keep shipping.
Once the foundations are stable, tests, deploy pipelines and observability come online. We seed the test suite around the critical paths first, wire it into the CI, and set up staging and production environments with real secrets management and basic logging, traces and error reporting.
The final stretch covers load testing, caching, queues and background jobs — whatever the prototype needs to hold up at the next traffic step. We close with a production handoff: runbooks, on-call notes, deploy and rollback playbooks. After that the founder team can run it themselves or keep us on retainer.
Selected engagements
SWISS INSURANCE POC
Insurance Document Automation POC for a Swiss Back Office

How SAPIENTROQ built a schema-driven insurance document automation POC for a Swiss back office: Mistral OCR plus OpenAI JSON-mode extraction, schemas generated live from admin-defined categories, with provider-swappable AI behind a single interface.
View Case
Why hardening beats a rewrite
Your prototype already proved the product
The AI coding tools earned their place — they got a working idea in front of users in days, not months. Throwing the code away to rewrite from scratch wastes that signal. Hardening keeps the product shape the users already validated and replaces only the parts that block production.
Auth scaffolding is the first thing that breaks
Demo auth is a login form and a token in local storage. Production auth is sessions with expiry and rotation, password reset and verification flows, audit logging on privileged actions, and permission checks enforced on the server. We do this refactor early because every other change depends on knowing who is allowed to do what.
Security defaults from a template are not your defaults
AI tools ship sensible-looking defaults that suit a tutorial more than a live product. Rate limits are usually too generous or missing entirely, CSP is permissive, CORS is wide open, secrets end up in the client bundle. We sweep these against OWASP Top 10 and tune them to the traffic shape the product actually has.
The database is where prototypes go to die at load
JSON columns and N+1 queries work fine for the first ten users. They stop working between user one hundred and user one thousand, exactly when the product is starting to matter. We refactor into a real schema with indexes and migrations, and we do it without dropping the production data the prototype has already collected.
Tests are a hiring decision, not a luxury
The team that inherits a zero-test codebase ships slower with every feature, because every change is a guess. We seed enough coverage that the next engineer hired — in-house or contractor — can change the code without fearing the silent regression. That coverage is the difference between a codebase that grows and one that stalls.
Handoff means you can run it without us
The sprint ends with runbooks, deploy and rollback playbooks, on-call notes and a written walkthrough of the production stack. If the founder team prefers to keep us on retainer, that path is open — but the handoff is real either way. The product was yours to begin with and stays yours when we leave.
Frequently Asked Questions
Six to twelve weeks. One week of audit on the real codebase, then a fixed-scope fix sprint that the audit quotes. We cap engagements at sixteen weeks — if the work would take longer than that, the prototype is past hardening and a Custom Platform Development rewrite is the honest recommendation.
Those three cover most of the inbound we see. We have also hardened prototypes from Cursor-driven greenfields, Replit Agent and hand-rolled GPT-coded codebases. The pipeline does not care which tool produced the code — we read the actual repository in week one and quote the sprint from there.
No. Rewrites are a separate Custom Platform Development engagement. Hardening keeps the prototype the users already validated and replaces only the parts that block production — auth, security, database, tests, CI, scaling. If the audit shows the code is past hardening, we say so and quote the rewrite path instead.
A written audit covering auth flow, database schema, request handlers, secrets, dependencies, deploy setup and test coverage — with the production-blocking gaps ranked, the recommended fix order, and a fixed-scope quote for the sprint. The audit is a billable one-week engagement and the deliverable is yours to keep, whether you hire us for the sprint or not.
You do. The prototype repository stays in your account from day one. We commit to a feature branch you control, you merge on your schedule, and we never hold the code hostage as part of a retainer. The handoff at week twelve includes runbooks and playbooks so the team can keep running it without us.
We migrate in place when the existing engine fits — PostgreSQL with a schema refactor is the common path. We move to a different engine only when the prototype picked something the product cannot live on at scale. Either way, we write the migrations that take the live data from the current shape to the target schema without downtime.
Yes — most engagements end with a smaller engineering retainer (one to two engineers for two to four months) that ships the next set of features on the hardened foundation. The retainer is optional, scoped separately, and starts only after the production handoff is complete.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ