OCR Software for Swiss Docs
OCR Software, productized
Two-pass OCR, not a single model call
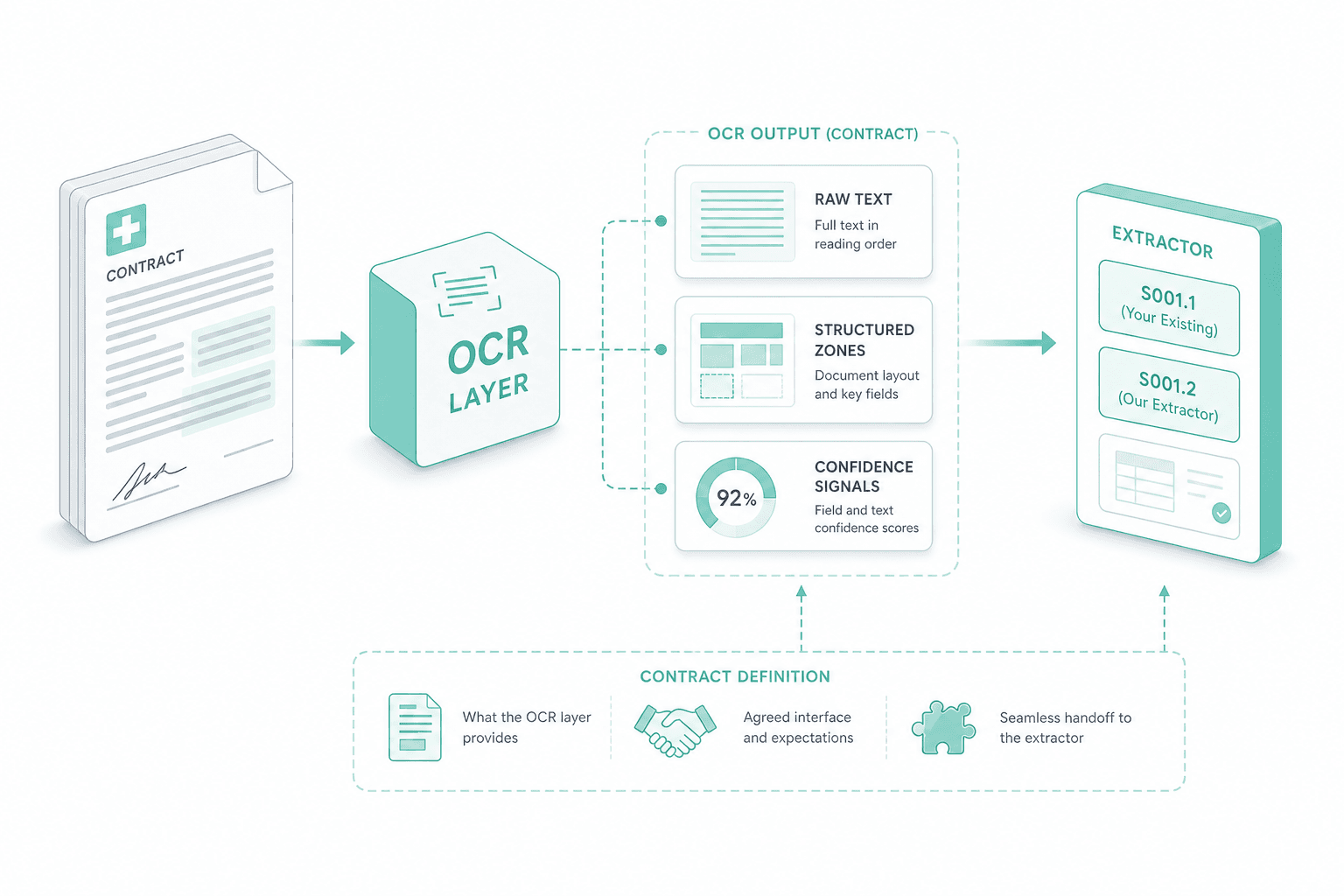
Our OCR software runs a two-pass Mistral OCR pattern. The first pass returns raw text from the page. The second pass returns structured zones — tables, columns, headers, key-value blocks. A single-model call collapses both into a guess; running them separately means the downstream LLM extractor sees both the words and the layout, and can decide which one to trust per field.
Swiss-German and DE forms handled
Multi-column German invoices, Swiss-German handwritten notes on supplier datasheets, and bilingual EN/DE forms all parse through the same OCR layer. Swiss-German is treated as DE — no separate Schweizerdeutsch model required. The OCR Switzerland angle is not a marketing line: it is what the layer is tuned against in production at Weita and Sanitas Troesch.
Scans, photos, mixed-quality PDFs
Real Swiss back-office documents are not clean digital PDFs. They are photographed receipts, archive scans with bleed-through, mobile snapshots of paper Belege, multi-page PDFs with mixed digital and scanned pages. The OCR layer handles each input shape on the same contract — raw text plus structured zones out, ready for the next step.
OCR API that feeds your extractor
The OCR layer is not the final answer. Its output is the contract for downstream classification and structured extraction. You can plug it into our S001.1 classification + extraction service, our S001.2 field extraction service, or your own LLM extractor — the OCR pass produces both raw text and structured zones, so an extractor can choose the right input per field.
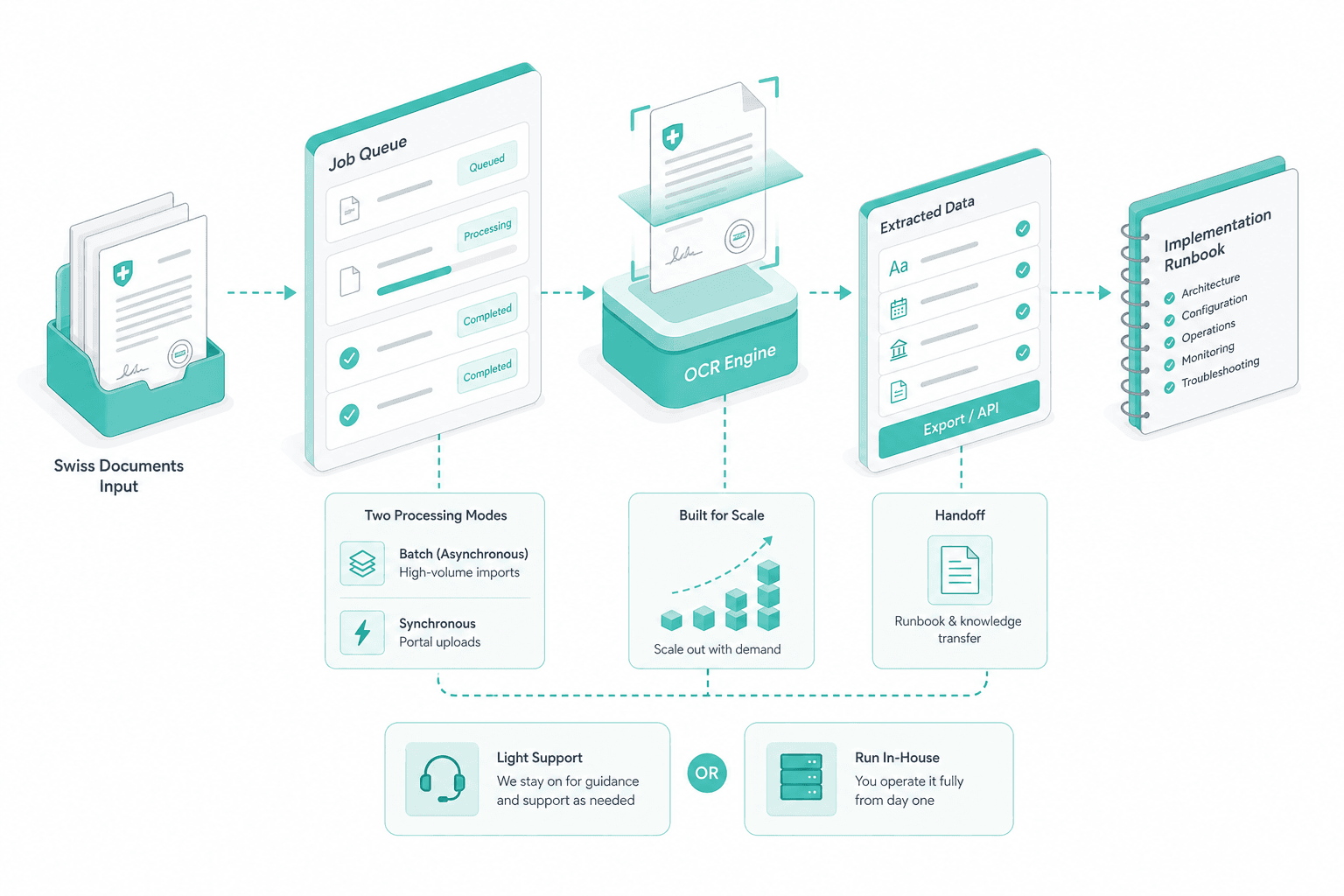
Batch and near-real-time
The OCR step runs inside a staged Laravel job queue. For high-volume nightly batches — supplier datasheets, archive imports — it scales horizontally on Docker workers. For near-real-time intake — a user uploading a Beleg in the customer portal — the same step runs synchronously and returns within seconds. Same code path, different queue priority.
Swiss data residency on request
For data-sensitive workloads the OCR layer runs on Swiss-resident hosting or on customer premises. The Apertus sovereign-LLM track is available where document content must not leave Swiss or EU jurisdiction. Every OCR pass is logged with model ID and version, so the provenance of the extracted text is auditable downstream.
How we deliver it
Sample collection and input audit
We start with your real documents — scanned datasheets, photographed Belege, archive PDFs, bilingual forms. We map what arrives in the inbox today versus what your downstream system actually needs as input.

Two-pass OCR on your inputs
We run the two-pass Mistral OCR pattern against the sample. Raw text first, structured zones second. You see exactly how the layer handles your worst documents, not a curated demo set.

Contract with the downstream extractor
We define the contract the OCR layer hands off — raw text, structured zones, confidence signals — so your existing or our S001.1 / S001.2 extractor can consume it without parsing tricks downstream.
Queue, scale and hand-off
We wire the OCR step into your job queue — batch for high-volume imports, synchronous for portal uploads — and hand over the runbook. Most customers keep us on light support; some run it fully in-house from week one.
We start with your real documents — scanned datasheets, photographed Belege, archive PDFs, bilingual forms. We map what arrives in the inbox today versus what your downstream system actually needs as input.
We run the two-pass Mistral OCR pattern against the sample. Raw text first, structured zones second. You see exactly how the layer handles your worst documents, not a curated demo set.
We define the contract the OCR layer hands off — raw text, structured zones, confidence signals — so your existing or our S001.1 / S001.2 extractor can consume it without parsing tricks downstream.
We wire the OCR step into your job queue — batch for high-volume imports, synchronous for portal uploads — and hand over the runbook. Most customers keep us on light support; some run it fully in-house from week one.
Selected engagements
SWISS INSURANCE POC
Insurance Document Automation POC for a Swiss Back Office

How SAPIENTROQ built a schema-driven insurance document automation POC for a Swiss back office: Mistral OCR plus OpenAI JSON-mode extraction, schemas generated live from admin-defined categories, with provider-swappable AI behind a single interface.
View Case
SANITAS TROESCH
PIM Implementation with HITL AI for Sanitas Troesch
How SAPIENTROQ delivered a PIM implementation with a multi-agent HITL pipeline that ingests 200k+ supplier SKUs from PDFs, Excel and Jira into the Sanitas Troesch PIM with audit-grade governance.
View Case

WEITA AG
Weita Supplier Onboarding Workflow: Wholesale Digital Transformation
How SAPIENTROQ built a Laravel and Next.js workflow that turns PDFs, emails, images and spreadsheets into compliant PIM products for Weita AG, with Mistral OCR, OpenAI JSON-mode extraction and a database-backed prompt registry.
View Case
Why two-pass OCR, not a single model call
Two passes give the extractor a choice
A single OCR call collapses words and layout into one guess. We run two passes — raw text first, structured zones second — and hand both to the downstream extractor. When a field is ambiguous in the raw stream, the structured zones disambiguate it; when the layout pass misreads a table, the raw text catches the value. Downstream LLM extraction in OpenAI JSON mode picks the right input per field instead of fighting one noisy stream.
OCR is a layer, not a product
Cloud OCR vendors sell the OCR call as the answer. In production it is not — it is the contract between paper and your extractor. Weita, Sanitas Troesch and the insurance AI POC all treat OCR as a staged step: Mistral OCR runs as one job in a Laravel queue, its output is the input for the next job, and HITL only shows up further downstream. Selling OCR as the final product hides where the real accuracy work happens.
Built against real Swiss documents
The OCR layer is tuned against the documents actually arriving at Swiss back offices today: scanned supplier datasheets with handwritten margin notes, multi-column German invoices, photographed Belege from mobile phones, archive PDFs with bleed-through. Swiss-German is treated as DE at the OCR step. Generic Swiss-German OCR claims are marketing — what is real is that the layer has been hardened on the documents three Swiss customers actually receive.
Frequently Asked Questions
Swiss-German is handled as DE at the OCR step. The layer does not require a separate Schweizerdeutsch model. In practice, the documents that hit production are written in standard DE with occasional Swiss-German notes — supplier names, place names, handwritten Belege. The two-pass pattern keeps both the raw text and the structured zones, so the downstream extractor can resolve ambiguities without us tuning a CH-only model.
No, and we do not pretend otherwise. Digital PDFs are easier — text is already encoded, the structured pass just confirms layout. Scans, photos and mixed-quality PDFs are where two-pass earns its keep: raw text and structured zones disagree more often, and the downstream extractor picks per field. We do not publish a single accuracy number because it is not meaningful across input shapes.
The OCR pass outputs raw text plus structured zones. Both go into the next queue step — classification, then field extraction in OpenAI JSON mode. The contract is explicit: the extractor sees text and zones, decides per field which one to trust, and writes a typed JSON payload. The OCR layer never makes business decisions; it produces inputs for the extractor that does.
Both. The OCR step lives inside a staged Laravel job queue. For nightly batches — supplier datasheet imports, archive ingestion — workers scale horizontally on Docker. For portal uploads where a user is waiting, the same step runs at higher priority and returns within seconds for typical Swiss documents. Same code path, different queue priority — no fork between batch and online.
We do not resell OCR by the page. We bill the engagement — discovery, integration, and run support — and pass the underlying Mistral OCR usage through at cost. For customers who already have an extractor and only want the OCR layer wired in, the engagement is short. For full IDP rollouts the OCR cost is folded into the broader S001 quote and rarely the dominant line item.
Yes. The OCR contract — raw text plus structured zones — is stable and provider-neutral. Customers who start with our S001.1 or S001.2 extractor can later swap the extraction model behind the same OCR layer, or vice versa. The two passes are designed to outlast the choice of downstream model.
Within Mistral OCR's published handwriting envelope, yes — handwritten margin notes on supplier datasheets, signed delivery notes, handwritten Belege. We do not claim handwriting recognition as a headline feature. In production, handwriting fields almost always route to HITL review downstream; the OCR pass just gives the reviewer a clean candidate to confirm or correct.
Default deployment is EU-hosted. For Swiss data-residency workloads, the OCR step runs on Swiss-resident servers or on customer premises. Where no public model endpoint may be reached, we wire in the Apertus sovereign-LLM track for the extractor and keep Mistral OCR on a Swiss-hosted gateway. Every OCR pass is logged with model ID and version for audit downstream.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ