Apertus-RAG-Integration
Was eine Apertus-RAG-Integration liefert
Konnektoren für Unternehmensquellen
Wir verbinden Apertus mit dem Dokumentenbestand, den Sie bereits betreiben — SharePoint Online und On-Prem, Confluence Cloud und Data Center, SMB- oder NFS-Fileshare sowie die gängigen DMS-Protokolle inklusive CMIS und direkter REST. Jeder Konnektor ist ein Vertrag: inkrementelle Sync, Übernahme der Quell-ACL und Audit-Eintrag pro Abruf.
PostgreSQL mit pgvector als Index
Der Retrieval-Index lebt in PostgreSQL mit pgvector, direkt neben der Anwendungsdatenbank. Ein Backup, eine Zugriffsrichtlinie, ein Betriebsteam, keine zusätzliche Vendor-Oberfläche. Qdrant, Pinecone und Weaviate prüfen wir je Engagement und routen nur dorthin, wenn Korpus oder Lastprofil es wirklich verlangen.
Evaluierungsset als Lieferobjekt
Jedes Apertus-RAG-Engagement bringt ein Evaluierungsset mit — echte Fragen Ihres Teams, mit den richtigen Passagen markiert durch Fachprüfer. Wir messen Recall, Precision und Latenz, justieren Chunking und Reranking, bis die Kurve sich stabilisiert, und frieren das Eval dann als Regressionssuite ein.
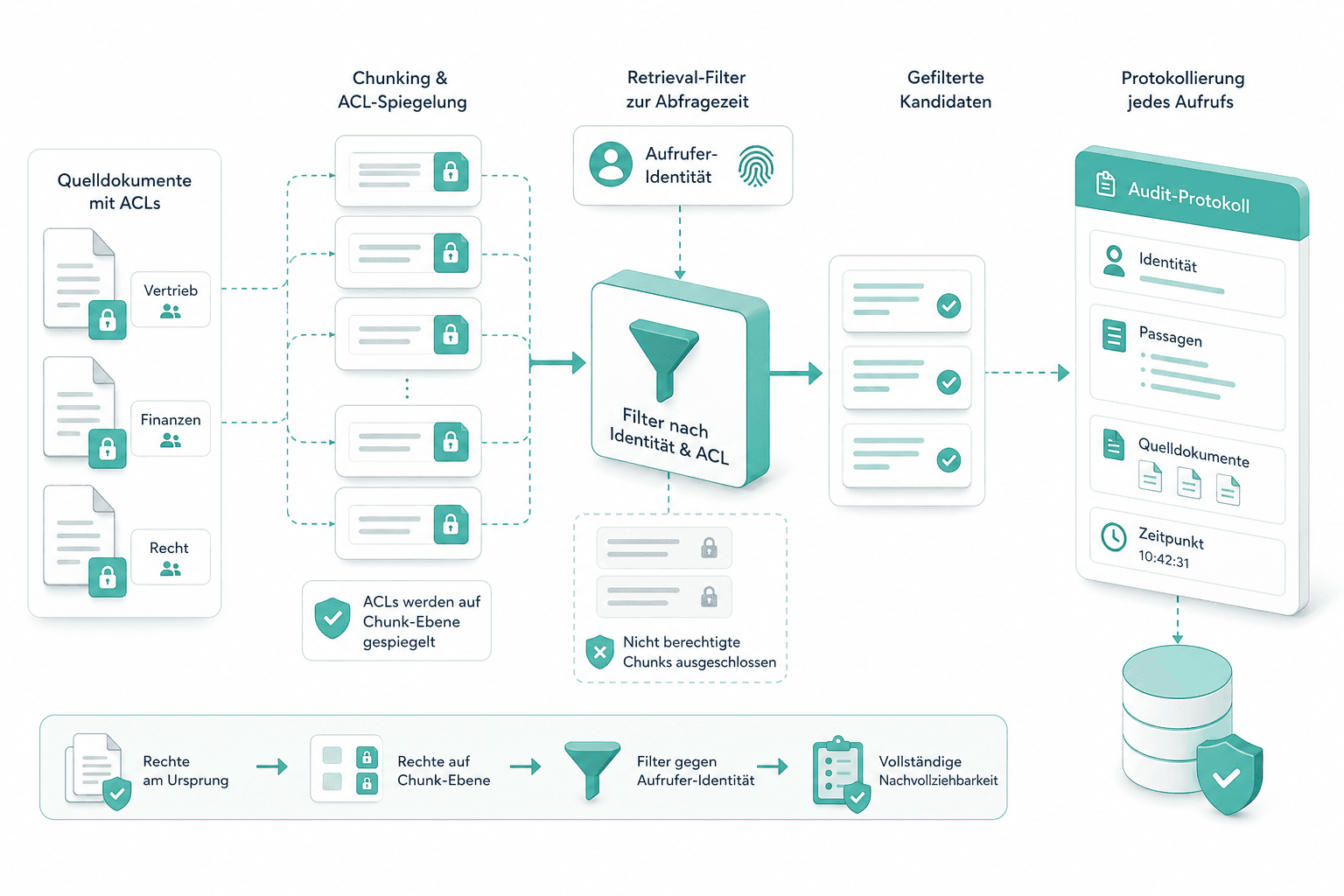
Berechtigungsfilter pro Nutzer
Berechtigungsmetadaten werden beim Indexieren an jedes Chunk gehängt und spiegeln die Quell-ACL aus SharePoint, Confluence oder dem DMS. Bei der Abfrage schneidet der Filter die Kandidaten gegen die Identität des Aufrufers, bevor eine Passage Apertus erreicht. Niemand sieht im Chat, was er nicht öffnen könnte.
Frische-Pipeline für Korpus
Unternehmens-Repositorien ändern sich jeden Werktag. Eine geplante Pipeline abonniert Änderungs-Events der Quellen — Microsoft-Graph-Deltas, Confluence-Webhooks, Fileshare-Watcher, DMS-Streams — und re-embeddet nur die tatsächlich geänderten Dokumente. Rechteänderungen laufen denselben Weg, eine Reorg ist sichtbar.
Generator-Anbindung an Apertus
Apertus läuft als Generator — 8B- oder 70B-Variante je nach Workload, ausgeliefert auf vLLM oder Text-Generation-Inference innerhalb Ihrer Hosting-Grenze. Treffer tragen Zitate, der Prompt ist neben dem Index versioniert, Antworten verlinken zurück auf das SharePoint- oder Confluence-Original.
So führen wir RAG ein
Inventur und Trust-Map
Wir gehen den Dokumentenbestand mit Ihrem Team durch — SharePoint-Sites, Confluence-Spaces, Fileshares, DMS — und klassifizieren jede Quelle nach Vertrauen, Frische und Rechtemodell. Die Inventur ist Basis für die Konnektorliste.
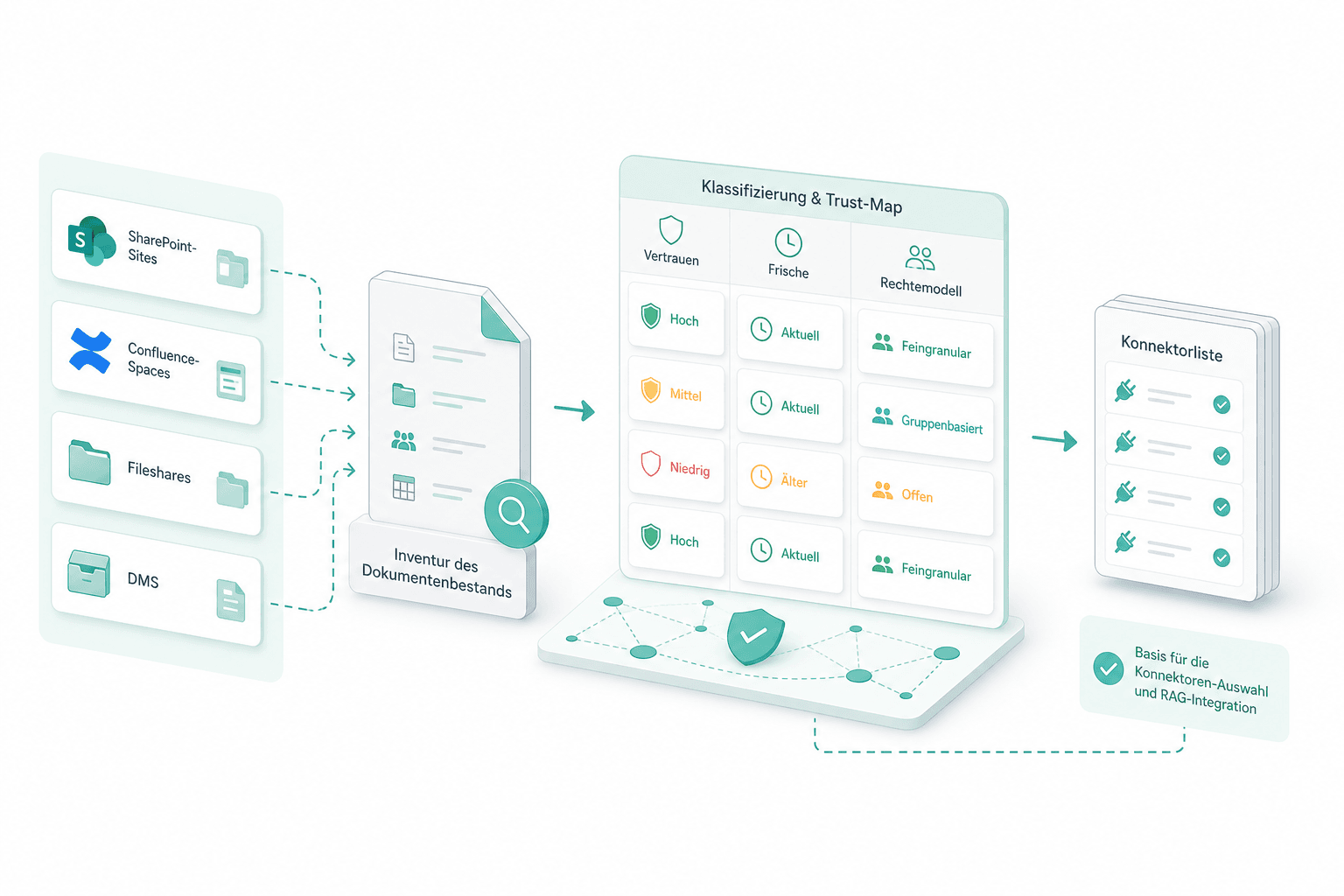
Schema und Chunking
Chunk-Grösse, Overlap, Metadatenfelder und Embedding-Modell werden vorab gegen Ihre Korpus-Form entschieden. Tabellen, Codeblöcke und Formulardokumente bekommen eigene Behandlung. Das Schema wird vor dem Index-Aufbau freigegeben.
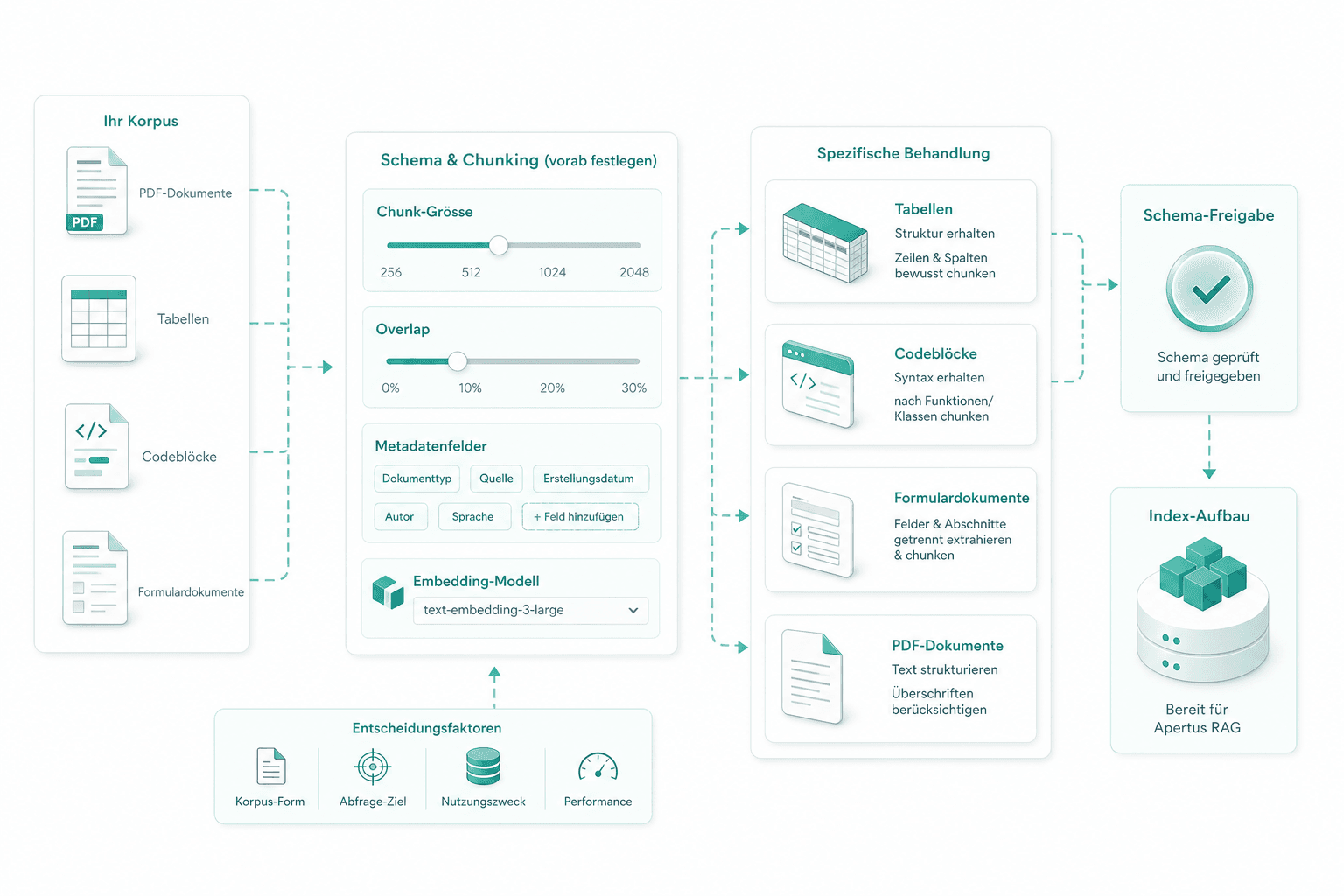
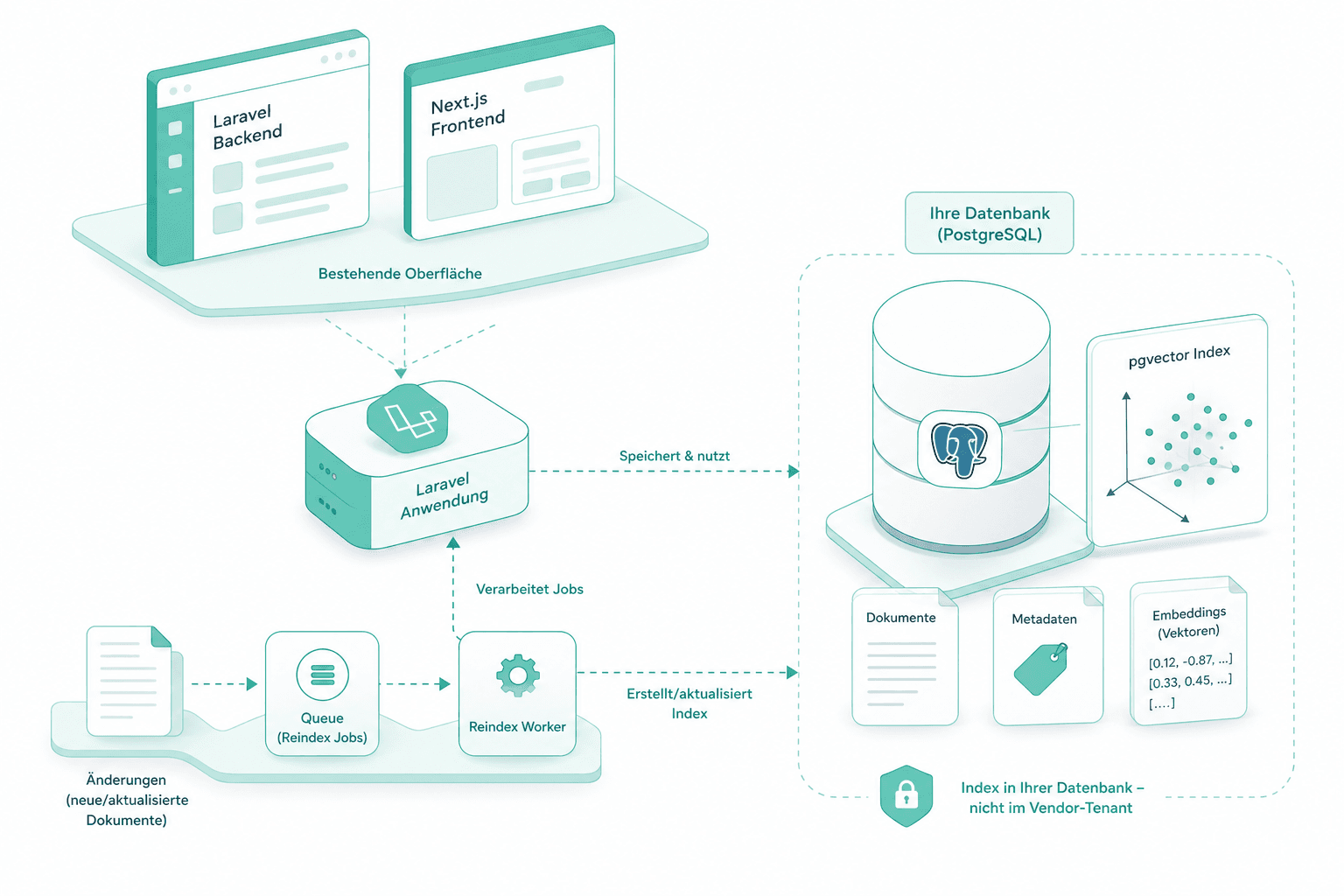
Index-Aufbau pgvector
Wir bauen den Produktiv-Index in PostgreSQL mit pgvector hinter derselben Laravel- und Next.js-Oberfläche, die bereits läuft. Reindex-Jobs laufen über die Queue. Der Index liegt in Ihrer Datenbank, nicht im Vendor-Tenant.
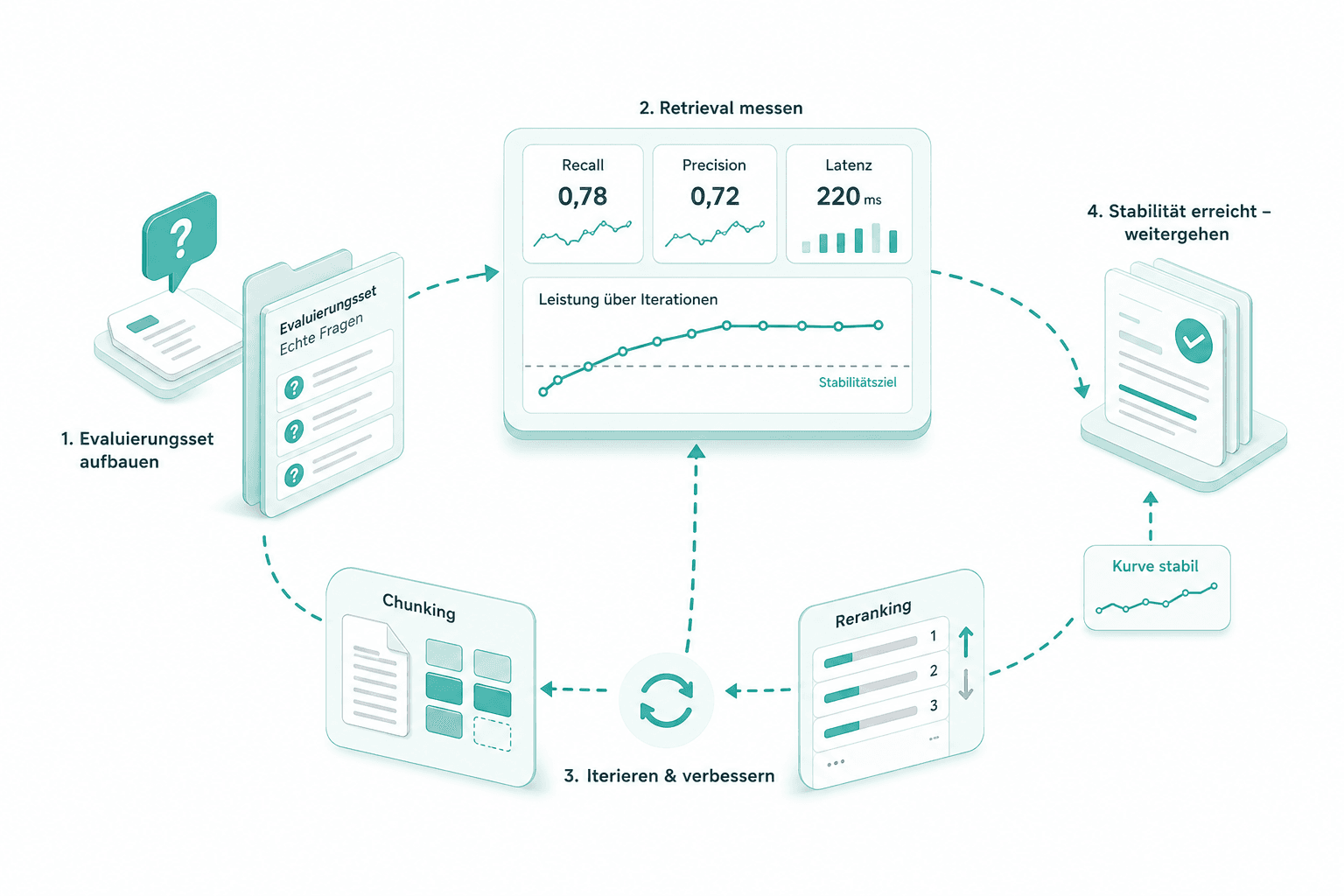
Evaluierungs-Loop
Ihre Fachprüfer bauen das Retrieval-Evaluierungsset aus echten Fragen. Wir messen Recall, Precision und Latenz, iterieren auf Chunking und Reranking und gehen erst weiter, wenn die Kurve stabil ist.
Rechte-Verdrahtung
Quell-ACLs werden auf Chunk-Ebene gespiegelt. Der Retrieval-Filter schneidet die Kandidaten gegen die Identität des Aufrufers zur Abfragezeit, und jeder Aufruf wird mit Identität, Passagen und Quelldokumenten protokolliert.
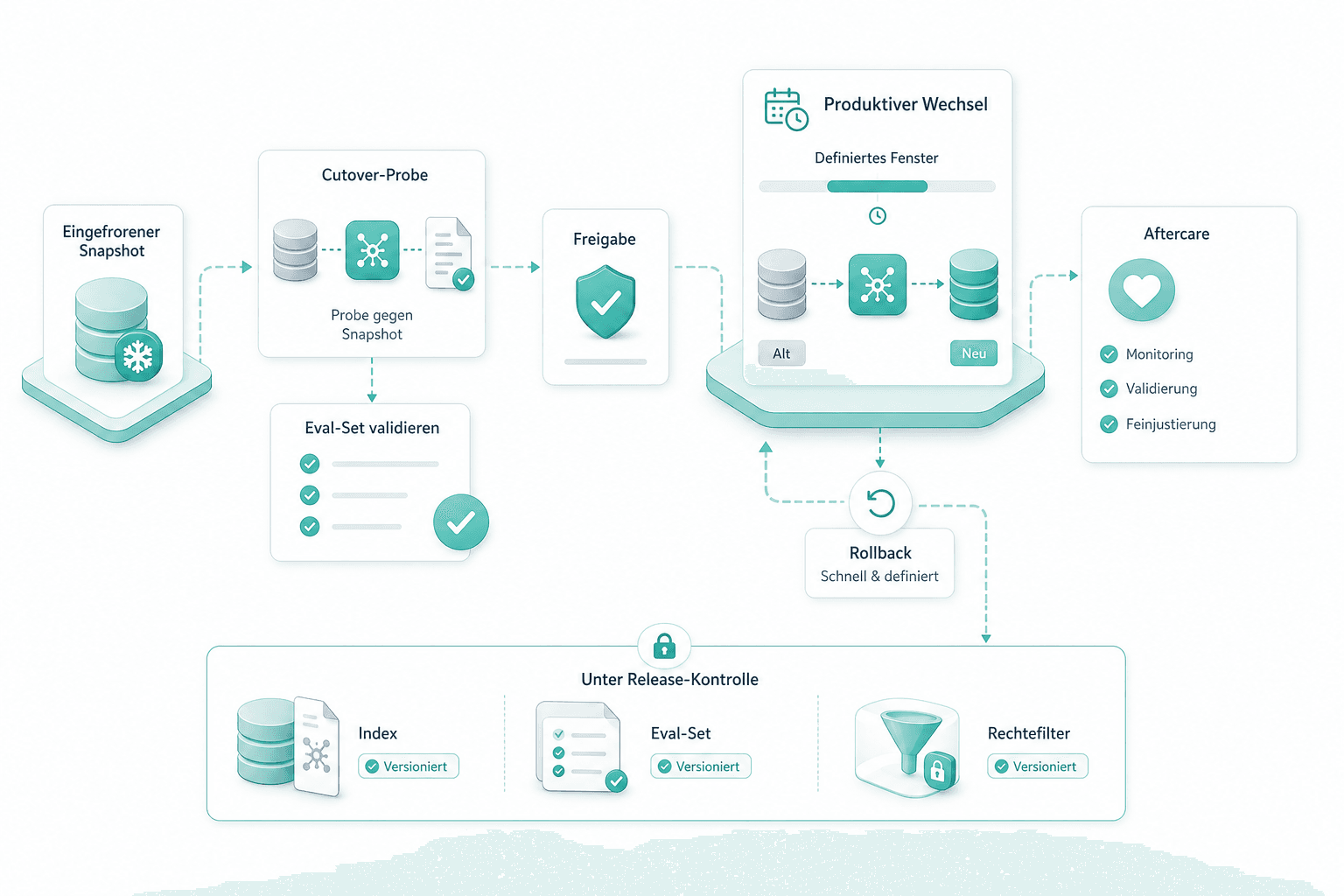
Cutover und Aftercare
Wir proben den Cutover gegen einen eingefrorenen Snapshot, validieren das Eval-Set, fahren dann den produktiven Wechsel in einem definierten Fenster mit Rollback. Index, Eval-Set und Rechtefilter bleiben unter Release-Kontrolle.
Wir gehen den Dokumentenbestand mit Ihrem Team durch — SharePoint-Sites, Confluence-Spaces, Fileshares, DMS — und klassifizieren jede Quelle nach Vertrauen, Frische und Rechtemodell. Die Inventur ist Basis für die Konnektorliste.
Chunk-Grösse, Overlap, Metadatenfelder und Embedding-Modell werden vorab gegen Ihre Korpus-Form entschieden. Tabellen, Codeblöcke und Formulardokumente bekommen eigene Behandlung. Das Schema wird vor dem Index-Aufbau freigegeben.
Wir bauen den Produktiv-Index in PostgreSQL mit pgvector hinter derselben Laravel- und Next.js-Oberfläche, die bereits läuft. Reindex-Jobs laufen über die Queue. Der Index liegt in Ihrer Datenbank, nicht im Vendor-Tenant.
Ihre Fachprüfer bauen das Retrieval-Evaluierungsset aus echten Fragen. Wir messen Recall, Precision und Latenz, iterieren auf Chunking und Reranking und gehen erst weiter, wenn die Kurve stabil ist.
Quell-ACLs werden auf Chunk-Ebene gespiegelt. Der Retrieval-Filter schneidet die Kandidaten gegen die Identität des Aufrufers zur Abfragezeit, und jeder Aufruf wird mit Identität, Passagen und Quelldokumenten protokolliert.
Wir proben den Cutover gegen einen eingefrorenen Snapshot, validieren das Eval-Set, fahren dann den produktiven Wechsel in einem definierten Fenster mit Rollback. Index, Eval-Set und Rechtefilter bleiben unter Release-Kontrolle.
Ausgewählte Projekte
BICOSY / BICO.CH
KI-Einkaufsassistent fuer bico.ch auf WooCommerce

Wie SAPIENTROQ BICOSY entwickelte: ein KI-Einkaufsassistent fuer den Schweizer Matratzenhaendler bico.ch — NestJS-Backend mit pgvector-RAG, deklarierte typisierte Tools und ein WordPress-Plugin, das WooCommerce-Events live in die Konversation streamt.
Fall ansehen
Warum Apertus-RAG mit unserem Team
RAG ist Engineering, kein Prompt
RAG is engineering, not a prompt. We treat the index, the retrieval evaluation set and the permission filter as production assets — same release discipline as a database migration. The model is the last component we change.
Diese Disziplin prägt jedes Apertus-RAG-Engagement. Konnektor, Chunking, Index und Berechtigungsfilter laufen unter Release-Kontrolle, bevor die Modellschicht justiert wird — ein späterer Modellwechsel ist Konfiguration, kein Projekt-Neustart.
pgvector als Default, Alternativen per Benchmark
Der Vektor-Index liegt direkt neben der Anwendungsdatenbank. Ein Backup, eine Zugriffsrichtlinie, ein Betriebsteam. Qdrant, Pinecone und Weaviate prüfen wir je Engagement und routen nur dorthin, wenn Korpus oder Lastprofil es verlangen — nie als Vendor-Partnerschaft, immer als Messung gegen Ihre Daten.
Rechtefilterung zur Abfragezeit
Rechte-Metadaten spiegeln die ACL der Quelle und werden beim Indexieren an jeden Chunk gehängt; bei der Abfrage schneiden wir gegen die Identität des Aufrufers, bevor Passagen den Generator erreichen. Kein Nutzer sieht im Chat etwas, das er in SharePoint, Confluence oder dem DMS nicht öffnen könnte.
Eine Plattform für den ganzen Apertus-Bestand
RAG ist die Engine hinter Dokumenten-Q&A-Copilots, läuft gegen Apertus on-prem oder Schweizer Hosting und teilt die Retrieval-Disziplin mit unserer KI-Dokumentenautomatisierung. Einstieg über den Apertus-Hub oder via KI-Beratung.
Häufig gestellte Fragen
Eine Konnektoren-Schicht zieht Dokumente aus SharePoint, Confluence, Fileshare oder DMS in einen Zwischenspeicher. Wir chunken, embedden und indexieren in PostgreSQL mit pgvector, hängen Rechte-Metadaten an und routen die Treffer mit Zitaten in Apertus als Generator.
SharePoint Online und On-Prem, Confluence Cloud und Data Center, SMB- und NFS-Fileshares sowie die DMS-Protokolle — CMIS-konforme Systeme und REST-Integrationen. Der Konnektor ist ein Vertrag: inkrementelle Sync, Rechteübernahme aus der Quell-ACL und Audit-Log pro Abruf.
pgvector ist unser Default, weil der Index direkt neben der Anwendungsdatenbank lebt — ein Backup, eine Zugriffsrichtlinie, ein Betriebsteam. Qdrant, Pinecone und Weaviate prüfen wir je Engagement und routen nur dorthin, wenn Korpus oder Lastprofil es wirklich verlangen.
Jedes Engagement bringt ein Retrieval-Evaluierungsset mit — echte Fragen Ihres Teams, mit den richtigen Passagen markiert. Wir messen Recall, Precision und Latenz, justieren Chunking und Reranking, bis die Kurve sich stabilisiert, und frieren das Eval als Regressionssuite ein.
Rechte-Metadaten werden beim Indexieren an jedes Chunk gehängt und spiegeln die ACL der Quelle. Bei der Abfrage schneidet der Filter die Kandidaten gegen die Identität des Aufrufers — niemand sieht im Chat etwas, das er in der Quelle nicht direkt öffnen könnte.
Eine geplante Pipeline abonniert Änderungs-Events der Quellen — Microsoft-Graph-Deltas, Confluence-Webhooks, Fileshare-Watcher, DMS-Streams — und re-embeddet nur betroffene Dokumente. Rechteänderungen laufen denselben Weg, eine Reorg ist in Minuten sichtbar.
Über SAPIENTROQ![]()
Sind Sie an einer Lösung interessiert?
Wir freuen uns, Ihnen die Möglichkeiten unverbindlich aufzuzeigen.

Roland Kurmann
CEO, SAPIENTROQ