Apertus-POC für Schweizer CTOs
Was die Engagement konkret liefert
Definition des Aufgabensets
Wir legen zuerst fest, welche Workloads in den POC einfliessen — Extraktion, Dokumenten-Q&A, Zusammenfassung in DE/FR/IT, Klassifikation, leichte agentische Flows. Das Aufgabenset wird abgenommen, bevor ein Modell läuft, damit der apertus benchmark schweiz nicht in eine Demo abdriftet.
Massgeschneidertes Eval-Set
Das Eval-Set entsteht an Ihren echten Datensätzen, nicht an einem öffentlichen Benchmark. Wir sampeln aus Lieferantenblättern, Verträgen, Stammdaten oder Ticket-Historie unter NDA, lassen ein bewertetes Subset von Ihren Fachreviewern annotieren und frieren es als Vertrag des apertus evaluation poc ein.
Side-by-side gegen Ihr Modell
Apertus 8B oder 70B läuft gegen dasselbe Eval-Set wie Ihr heutiges GPT-4o, Claude oder Gemini, im selben Harness. Qualität, Latenz und Kosten je Aufgabentyp landen in einer Vergleichstabelle, sodass die apertus machbarkeitsstudie als ein Dokument im Steering-Komitee gelesen werden kann.
Laufender Prototyp statt Foliendeck
Am Ende der Engagement bedient Apertus echte Inferenz auf einem Endpunkt — vLLM oder TGI auf einem Sandbox-Cluster, hinter derselben Laravel- und Next.js-Spine wie produktiv. Ihr Team kann ihn ansprechen, Ihren bestehenden Client umhängen und die Latenz auf Schweizer Hosting spüren.
Go/No-Go-Empfehlungsdokument
Das Abschluss-Artefakt ist eine Empfehlung: Go auf Apertus, Verbleib auf dem aktuellen Modell, oder Split nach Aufgabentyp. Das Dokument trägt die Eval-Tabelle, das Kostenmodell, die Risikohinweise und die Deployment-Form, die wir als Nächstes bauen würden. Es liest sich auch ohne Engineering-Hintergrund.
Eval-Set-Übergabe in Produktion
Bei einer Go-Entscheidung wandert das Eval-Set direkt in die Produktivphase — dieselben nummerierten Tests sichern jeden Release des On-Prem-Baus oder der Migration ab. Nichts wird neu gebaut; die apertus poc-Ergebnisse werden zum Abnahmevertrag für das, was als Nächstes ausgeliefert wird.
So fahren wir den POC
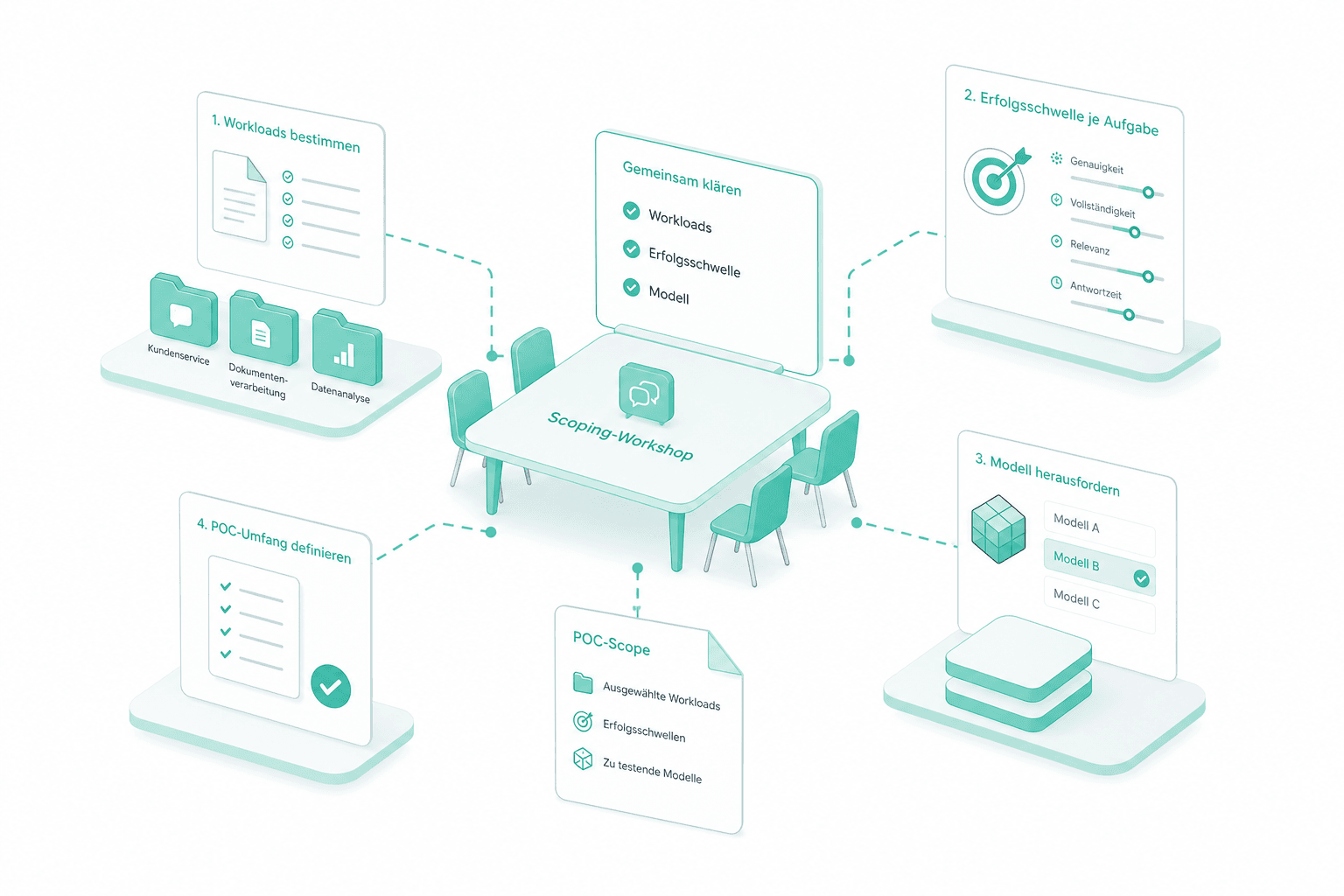
Scoping-Workshop
Wir führen einen strukturierten Workshop mit Ihrem Head of AI oder CTO, um festzulegen, welche Workloads in den POC einfliessen, was die Erfolgsschwelle je Aufgabe ist und welches Modell herausgefordert wird.
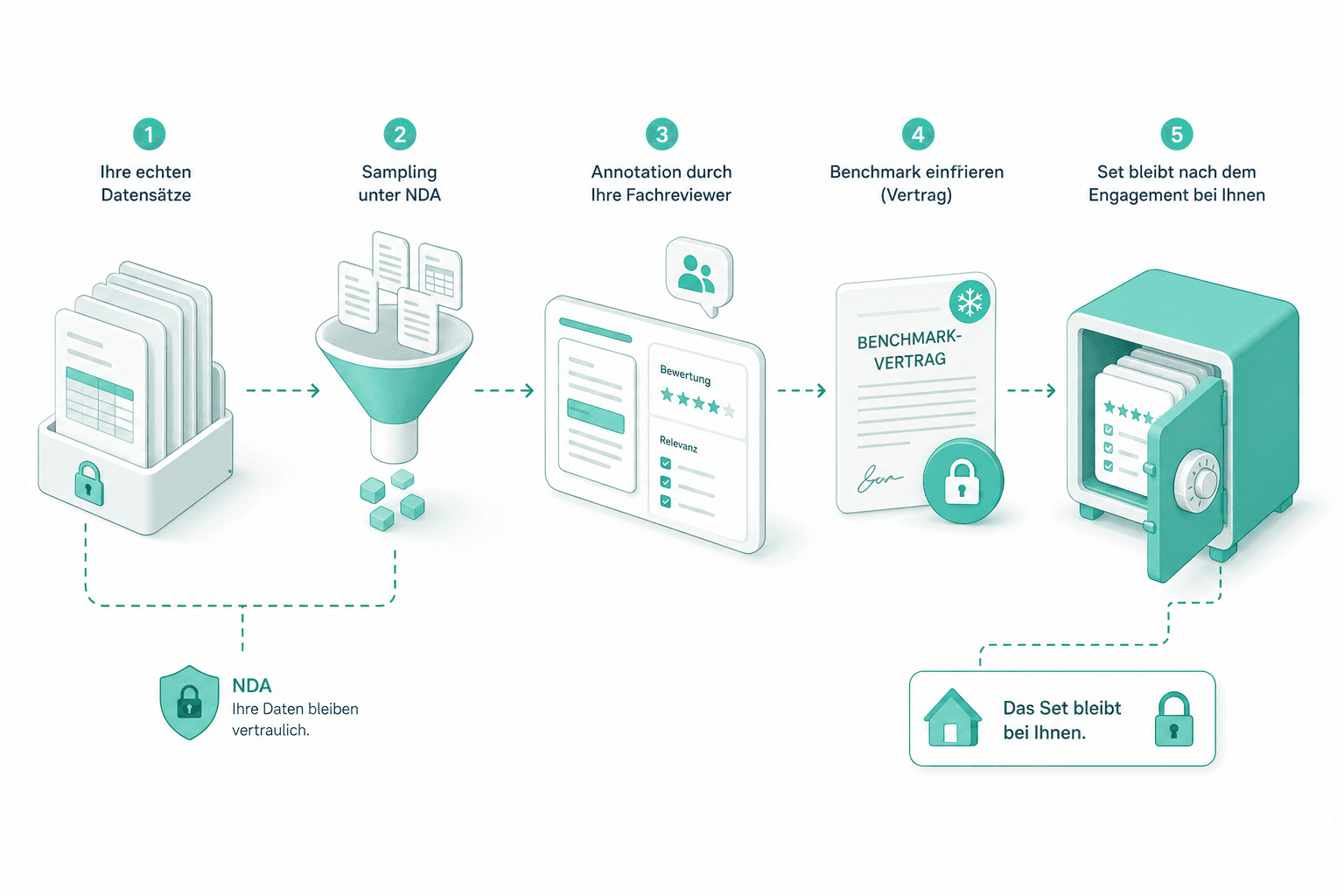
Eval-Set-Design
Wir sampeln Ihre echten Datensätze unter NDA, lassen ein bewertetes Subset von Ihren Fachreviewern annotieren und frieren es als Benchmark-Vertrag ein. Das Set bleibt nach dem Engagement bei Ihnen.
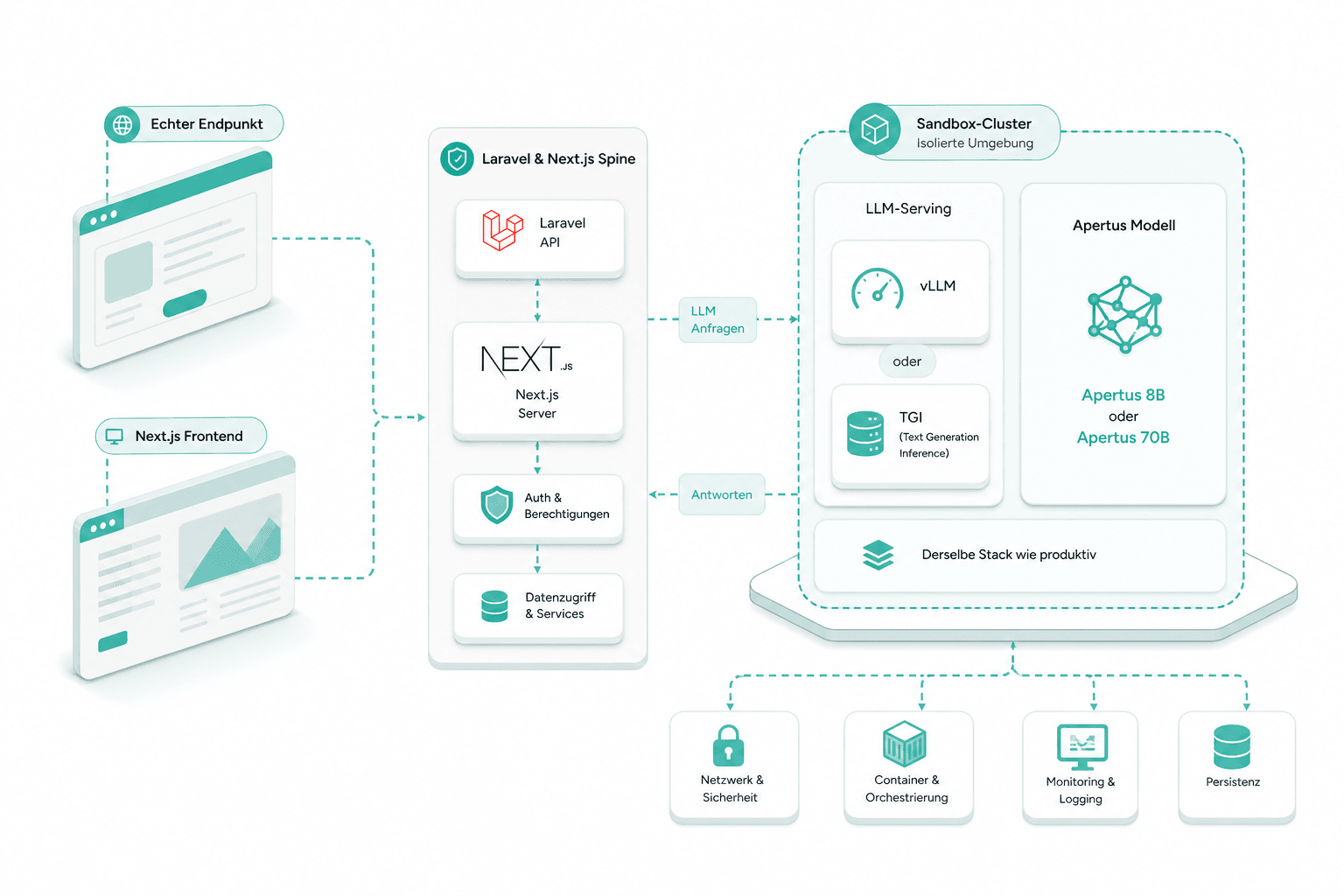
Aufbau des Prototyps
Apertus 8B oder 70B wird auf einem Sandbox-Cluster bedient — vLLM oder TGI, derselbe Stack wie produktiv. Der Prototyp läuft an einem echten Endpunkt hinter der Laravel- und Next.js-Spine.
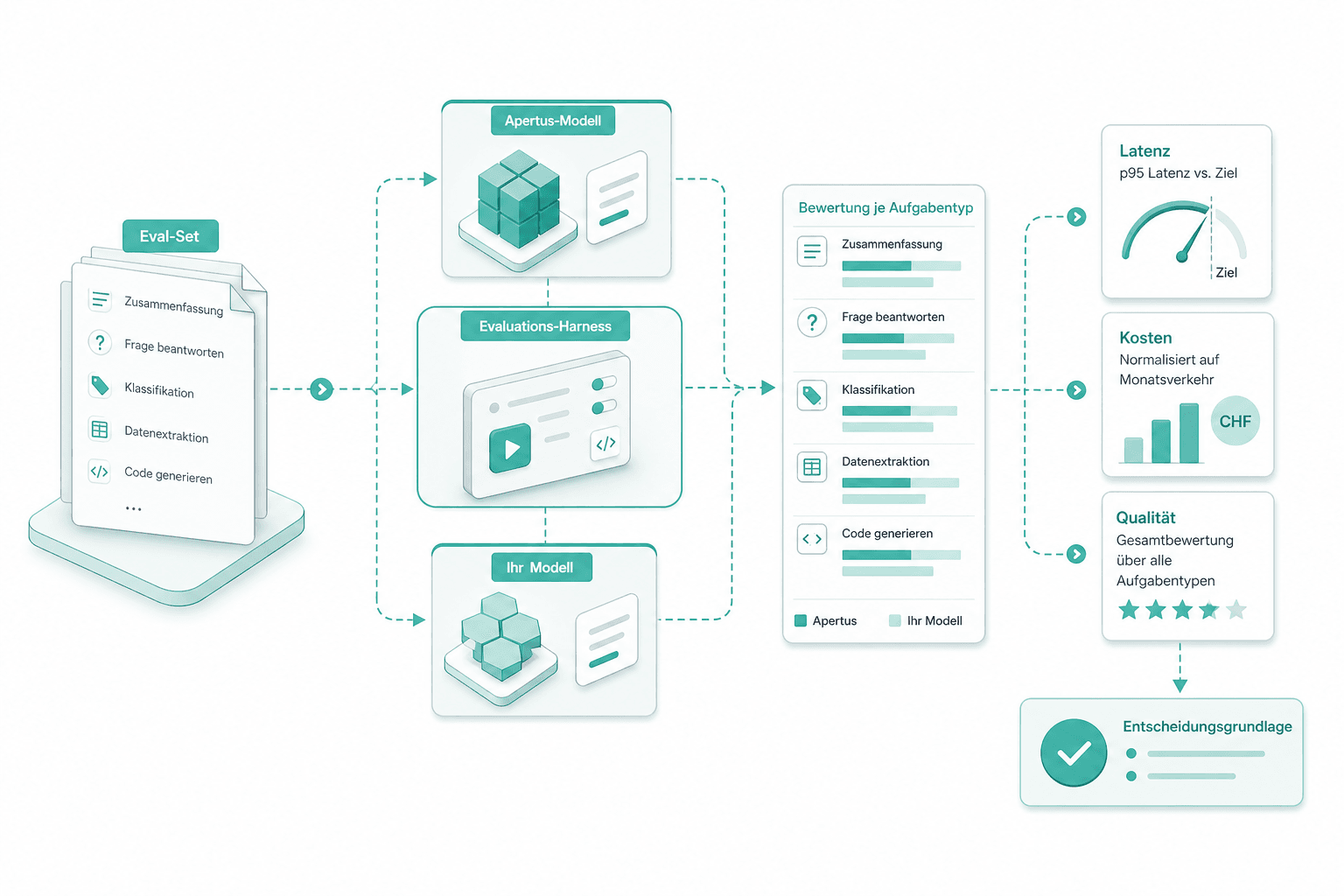
Benchmark-Läufe
Das Eval-Set läuft gegen Apertus und Ihr Modell im selben Harness. Qualität wird je Aufgabentyp bewertet, Latenz gegen das Serving-Ziel gemessen, Kosten auf den Monatsverkehr normalisiert.
Empfehlungsbericht
Wir schreiben das Go/No-Go-Dokument: Deployment auf Apertus, Verbleib auf dem aktuellen Modell oder Split nach Aufgabentyp. Der Bericht trägt Eval-Tabelle, Kostenmodell und Risikohinweise.
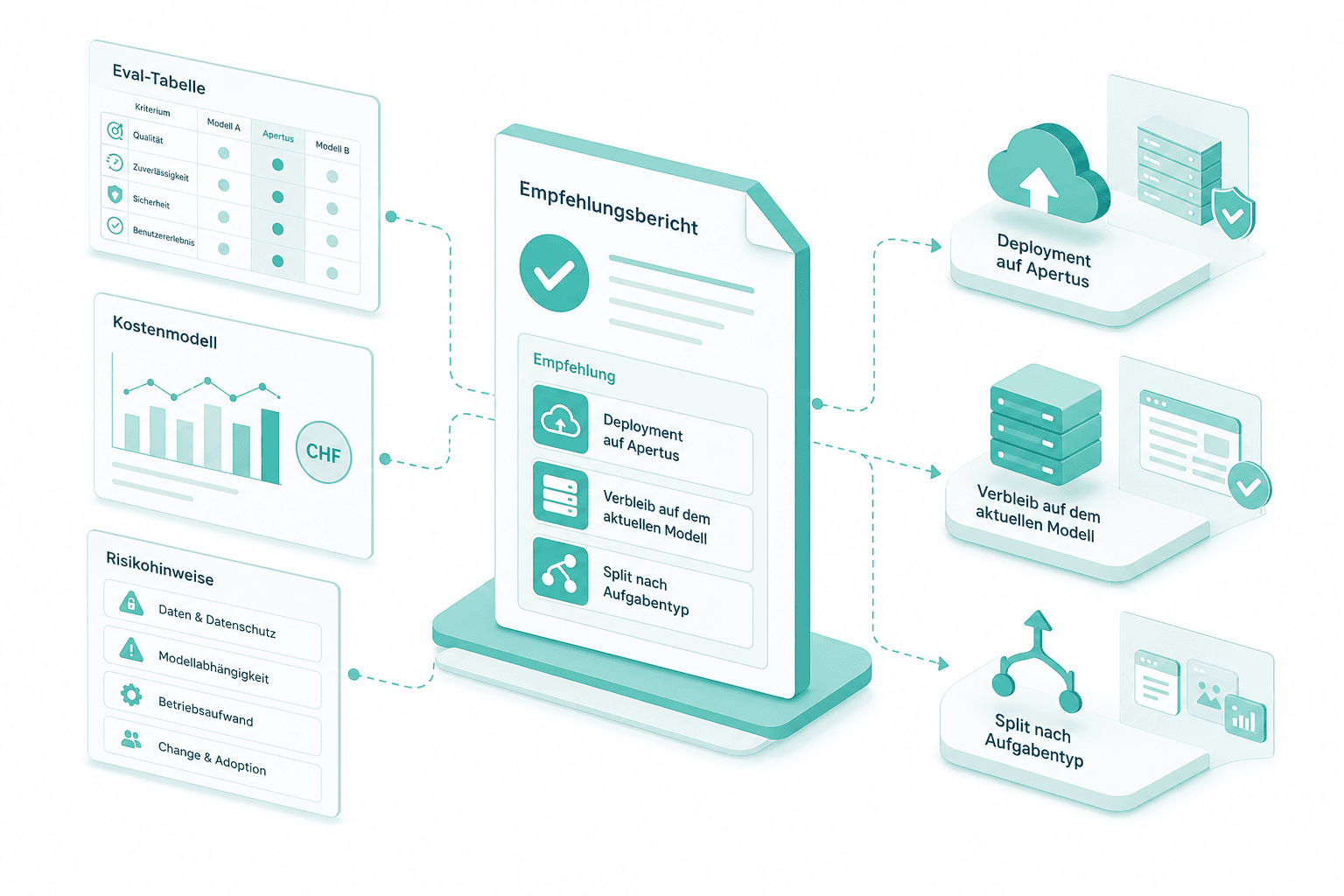
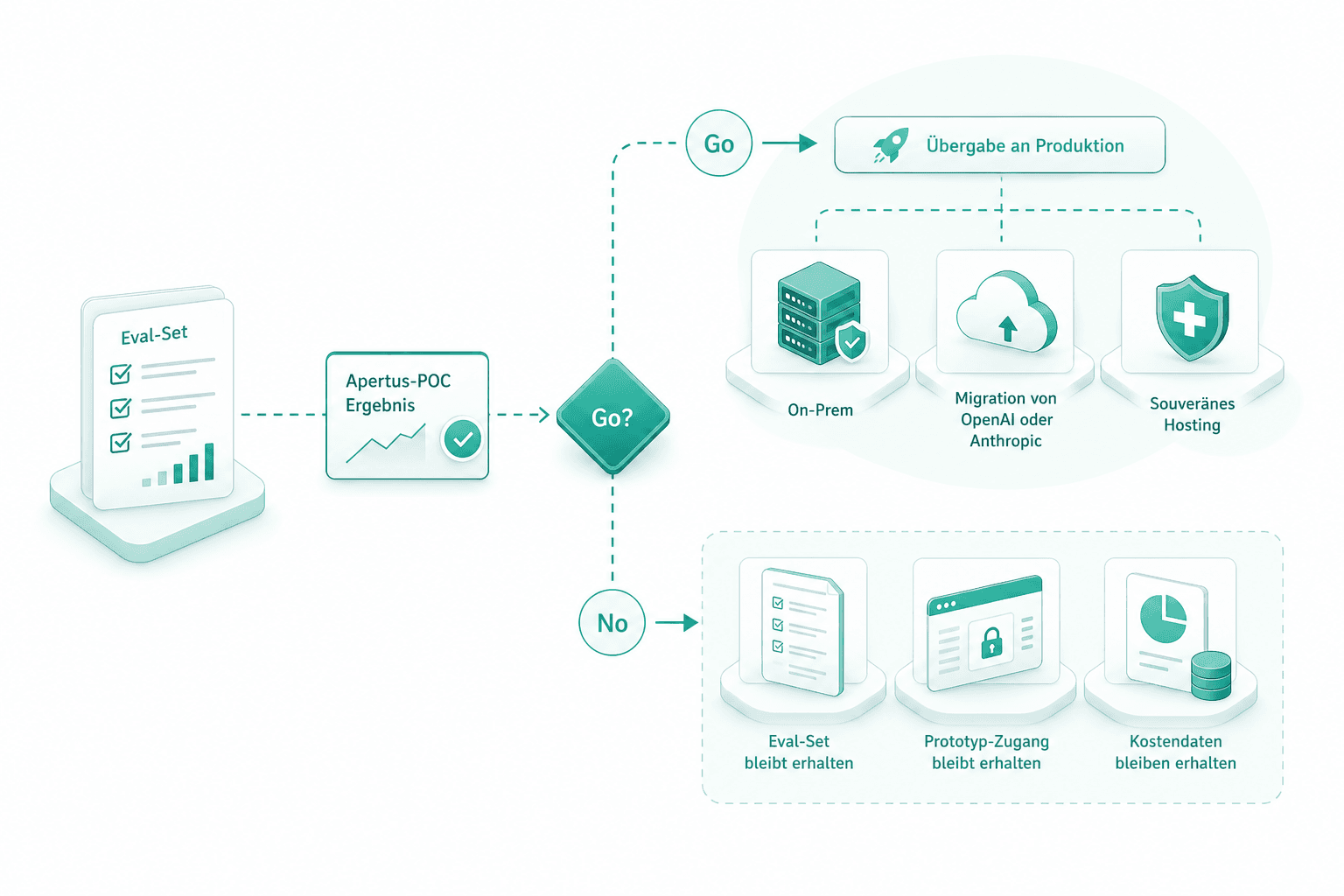
Übergabe an Produktion
Bei Go fliesst das Eval-Set in die nächste Phase — On-Prem, Migration von OpenAI oder Anthropic, oder souveränes Hosting. Bei No bleiben Eval-Set, Prototyp-Zugang und Kostendaten erhalten.
Wir führen einen strukturierten Workshop mit Ihrem Head of AI oder CTO, um festzulegen, welche Workloads in den POC einfliessen, was die Erfolgsschwelle je Aufgabe ist und welches Modell herausgefordert wird.
Wir sampeln Ihre echten Datensätze unter NDA, lassen ein bewertetes Subset von Ihren Fachreviewern annotieren und frieren es als Benchmark-Vertrag ein. Das Set bleibt nach dem Engagement bei Ihnen.
Apertus 8B oder 70B wird auf einem Sandbox-Cluster bedient — vLLM oder TGI, derselbe Stack wie produktiv. Der Prototyp läuft an einem echten Endpunkt hinter der Laravel- und Next.js-Spine.
Das Eval-Set läuft gegen Apertus und Ihr Modell im selben Harness. Qualität wird je Aufgabentyp bewertet, Latenz gegen das Serving-Ziel gemessen, Kosten auf den Monatsverkehr normalisiert.
Wir schreiben das Go/No-Go-Dokument: Deployment auf Apertus, Verbleib auf dem aktuellen Modell oder Split nach Aufgabentyp. Der Bericht trägt Eval-Tabelle, Kostenmodell und Risikohinweise.
Bei Go fliesst das Eval-Set in die nächste Phase — On-Prem, Migration von OpenAI oder Anthropic, oder souveränes Hosting. Bei No bleiben Eval-Set, Prototyp-Zugang und Kostendaten erhalten.
Ausgewählte Projekte
SWISS INSURANCE POC (NDA)
POC zur Automatisierung von Versicherungsdokumenten

Wie SAPIENTROQ einen schema-getriebenen POC zur Automatisierung von Versicherungsdokumenten fur ein Schweizer Backoffice lieferte: Mistral OCR plus OpenAI JSON-Modus, Schemata live aus Admin-Konfiguration generiert, KI-Anbieter tauschbar hinter einer Schnittstelle.
Fall ansehen
Warum bezahlter POC, kein Workshop
Ein POC, der mit einer Zahl endet, nicht mit einem Workshop
Ein POC ohne nummerierte Eval-Tabelle ist ein Workshop. Unser POC endet mit demselben Eval-Set, an dem das Produktivsystem gemessen wird — die Go/No-Go-Entscheidung ist eine Zahl, kein Gefühl. Das ist die Spielregel der Engagement und steht im Auftrag.
Das Eval-Set ist der Vertrag
Dasselbe annotierte Set, das Sie in Woche eins abnehmen, ist das Set, an dem Apertus und Ihr heutiges Modell in Woche drei laufen. Es wird nicht umgeschrieben, um das Ergebnis zu schmeicheln, und es verschwindet nach dem Bericht nicht — es wird zur Abnahmegrenze für jeden Release der nächsten Phase.
Bezahlt, zwei bis vier Wochen, je Projekt budgetiert
Es ist eine bezahlte Engagement, kein Gratis-Pilot. Die Dauer liegt bei zwei bis vier Wochen; der Preis wird je Projekt nach dem Discovery-Call quotiert, sobald Aufgabenset, Datenzugang und Erfolgsschwelle stehen. Bezahlung hält die Empfehlung ehrlich — auch wenn die Empfehlung Verbleib heisst.
Wohin der POC führt
Bei einer Go-Empfehlung folgt der produktive On-Prem-Bau, die Migration von OpenAI oder Anthropic oder das souveräne Schweizer Hosting. Die Engagement liegt unter der Apertus-Swiss-LLM-Linie und startet aus der KI-Beratung.
Häufig gestellte Fragen
Alle drei, aber der Wert liegt in der Empfehlung. Sie erhalten einen laufenden Apertus-Prototyp auf Ihren echten Aufgaben, einen Benchmark-Bericht gegen Ihr heutiges Modell in Qualität, Latenz und Kosten, sowie ein Go/No-Go-Dokument. Das Eval-Set bleibt bei Ihnen.
Der Standard liegt bei zwei bis vier Wochen, abhängig vom Aufgabenumfang und der Qualität der Quelldaten. Es ist eine bezahlte Engagement, je Projekt budgetiert — der Preis wird nach dem Discovery-Call quotiert, sobald Aufgabenset und Erfolgsschwelle schriftlich stehen.
Das Set ist Ihr Set — Extraktion aus Lieferantenblättern, Dokumenten-Q&A, deutsche oder französische Zusammenfassung, Klassifikation gegen ETIM, leichte agentische Flows. Wir wählen die Workloads, die für Ihren Fahrplan zählen, nicht ein generisches öffentliches Leaderboard.
Wir bauen ein Eval-Set, das gegen Apertus und Ihr heutiges GPT-4o, Claude oder Gemini im selben Harness läuft. Qualität wird je Aufgabentyp bewertet, Latenz gegen Ihr Serving-Ziel gemessen, Kosten auf Ihren Monatsverkehr normalisiert. Das Ergebnis ist eine Vergleichstabelle.
Ja, und genau dafür wird der POC bezahlt. Erreicht Apertus die Schwelle auf einer Aufgabe nicht — Genauigkeit, Latenz oder Betriebskosten —, sagt der Bericht das aus, und wir empfehlen Verbleib oder Workload-Split. Ein Nein ist ein abgeschlossener POC, kein gescheiterter.
Dasselbe Eval-Set wird zum Vertrag für die nächste Phase. Bei Go folgt der produktive On-Prem-Bau oder die Migration von OpenAI oder Anthropic, gemessen an denselben Zahlen wie im POC.
Über SAPIENTROQ![]()
Sind Sie an einer Lösung interessiert?
Wir freuen uns, Ihnen die Möglichkeiten unverbindlich aufzuzeigen.

Roland Kurmann
CEO, SAPIENTROQ