Apertus On-Prem Deployment
Was Apertus-On-Prem-Deployment umfasst
Discovery und Inferenz-Installation
Wir starten mit einer belastbaren Discovery — Workload-Klasse, Konkurrenzprofil, Latenz-Budget, regulatorischer Rahmen — und installieren den Inferenz-Server in Ihrem Estate. vLLM ist Standard für Apertus-On-Prem-Deployment; TGI passt für Teams auf der Hugging-Face-Oberfläche. Die Installation landet in Ihrer CI und Image-Registry.
GPU-Sizing auf Ihren Prompt-Mix
Produktives Sizing wird nicht aus dem Model-Card geraten. Wir benchmarken Apertus 8B und, wo nötig, die 70B-Variante gegen Ihre echte Prompt-Verteilung und Konkurrenz. Cluster landen auf H100-, A100- oder L40S-Klasse-Silizium; quantisierte Varianten erweitern die 8B-Klasse auf leichtere Hardware. Hardware kaufen Sie selbst oder aus der Cloud.
Monitoring in Ihren Stack
Apertus wird an Ihr bestehendes Prometheus und Grafana angebunden, mit Alerting an Ihr On-Call-System. Wir exponieren GPU-Auslastung, Queue-Tiefe, Prompt- und Completion-Längen, Latenz-Verteilung und Fehlerklassen — die Metriken, die Ihr Plattform-Team ohnehin liest. Kein paralleles Observability-Silo für die Inferenz.
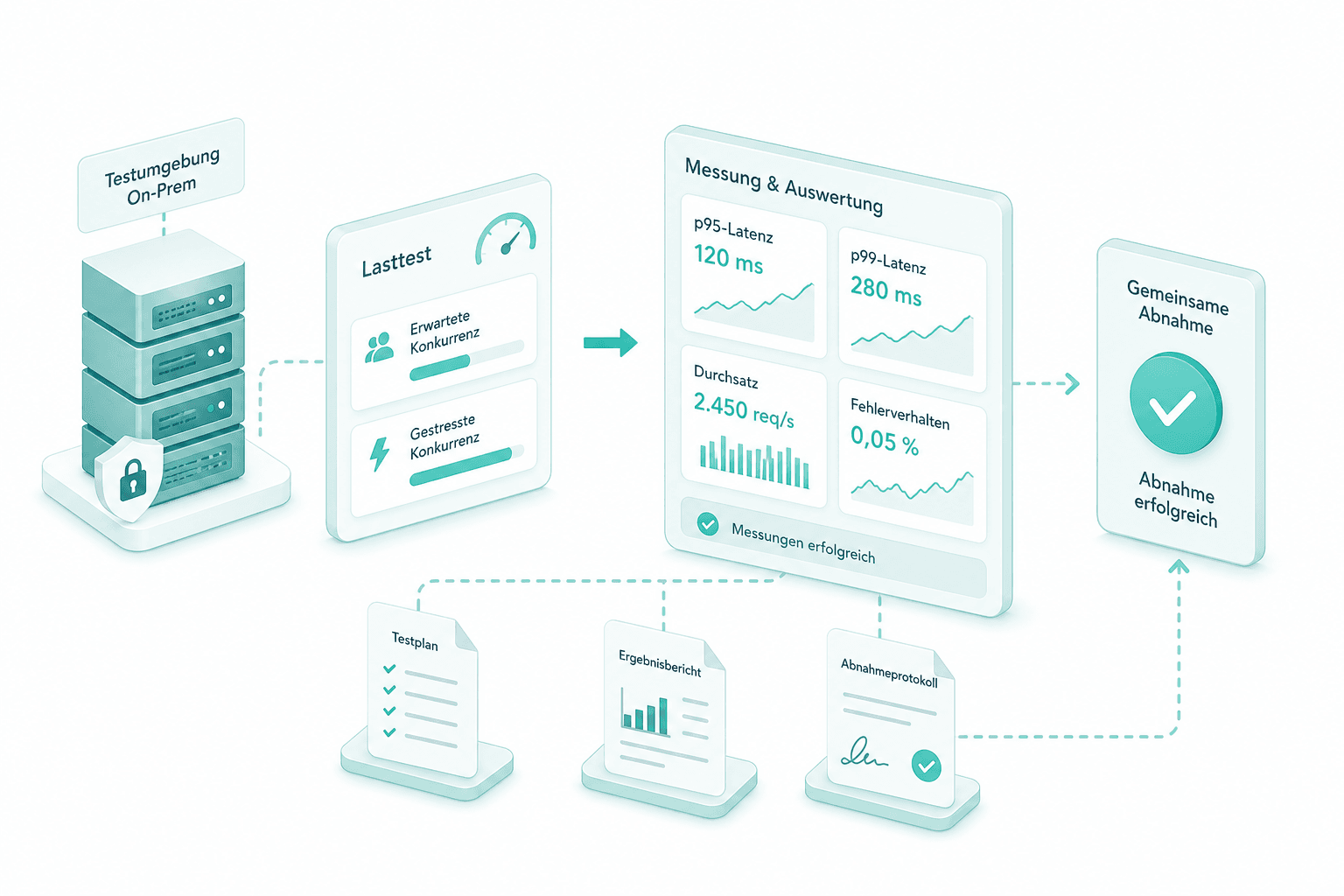
Lasttests gegen Abnahmemenge
Vor dem Go-Live wird der Cluster gegen einen repräsentativen Request-Mix und eine Abnahmemenge aus Ihren echten Prompts geprüft. Nachhaltiger Durchsatz, p95 und p99 Latenz, Queue-Sättigung und Fehlerverhalten werden unter erwarteter und gestresster Konkurrenz gemessen und gemeinsam abgenommen. Produktion startet auf einer Messung.
Produktive SLA und On-Call
Die SLA ist auf die Workload-Klasse zugeschnitten — interaktiver Chat, Batch-Anreicherung oder Background-RAG — und deckt Reaktionsziele, On-Call-Fenster, Vorfallklassifikation und Eskalation ab. Ziele liegen auf dem Latenz-Budget, das die Anwendung tragen kann, vereinbart in der Discovery statt aus einem Standardtext kopiert.
Übergabe an Ihr Plattform-Team
Wissenstransfer ist Teil des Engagements, kein Folgeangebot. Runbooks, Skalierungs-Playbook, Kapazitätsmodell, Image-Rebuild-Pipeline und Vorfall-Prozeduren werden für Ihr Team geschrieben und geübt. Für die Hosting-Alternative siehe Swiss-Datensouveränität-Hosting.
Unser On-Prem-Vorgehen
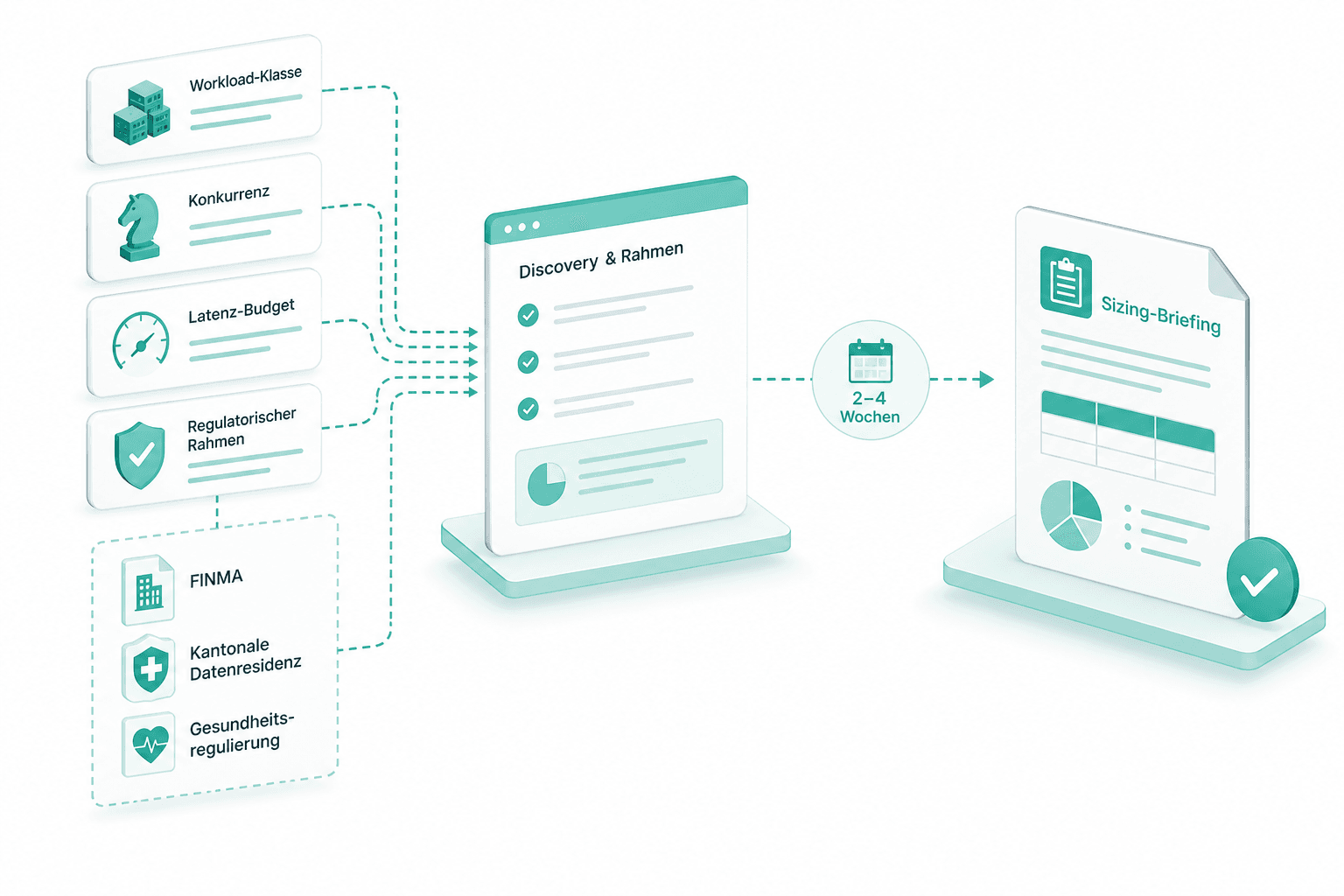
Discovery und Rahmen
Workload-Klasse, Konkurrenz, Latenz-Budget und regulatorischer Rahmen — FINMA, kantonale Datenresidenz, Gesundheitsregulierung — werden in zwei bis vier Wochen erfasst. Das Ergebnis ist das Sizing-Briefing.
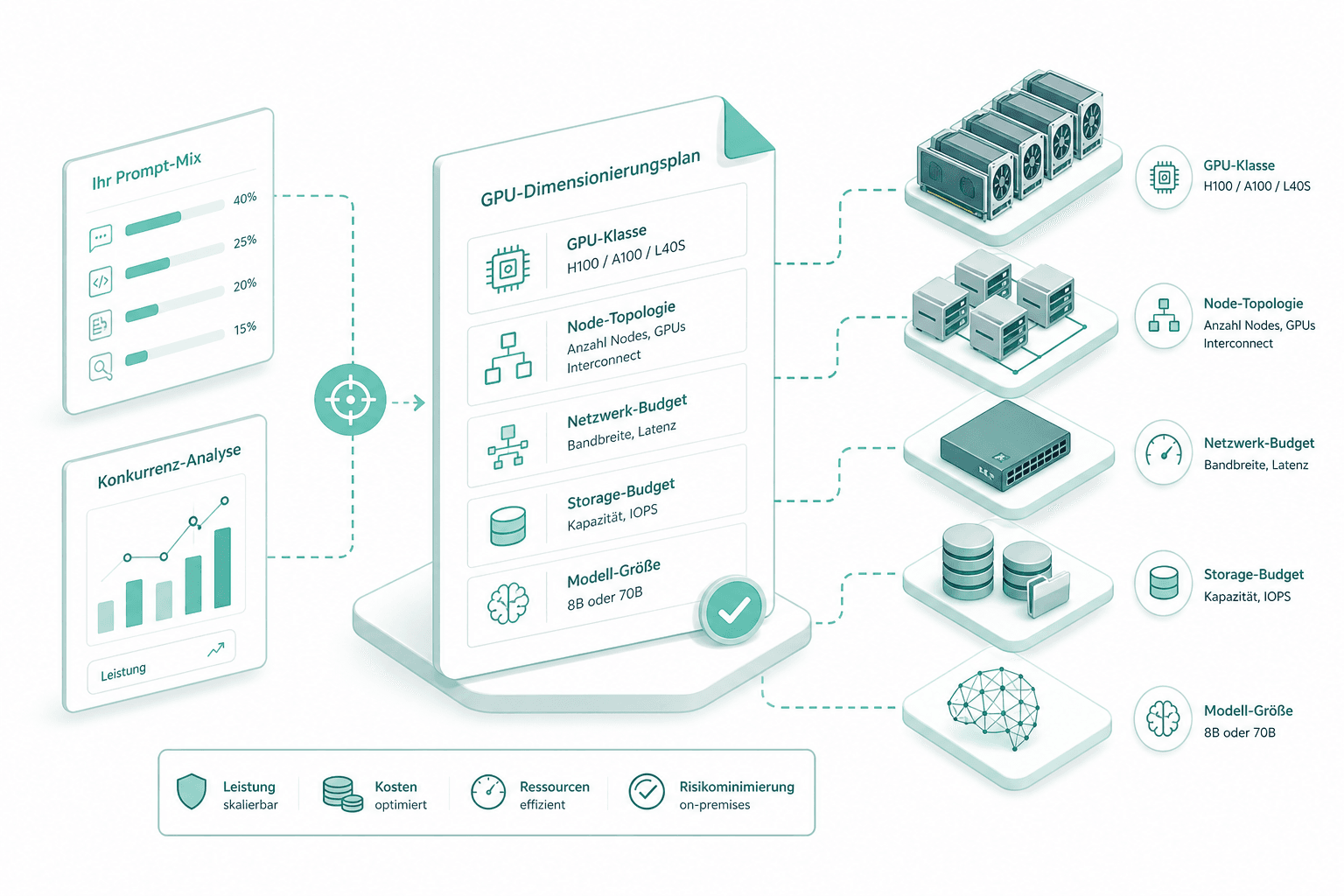
GPU-Sizing und Plan
Wir dimensionieren gegen Ihren echten Prompt-Mix und Ihre Konkurrenz, nicht gegen ein Standardrezept. Der Plan benennt GPU-Klasse (H100, A100 oder L40S), Node-Topologie, Netz- und Storage-Budget sowie 8B oder 70B.
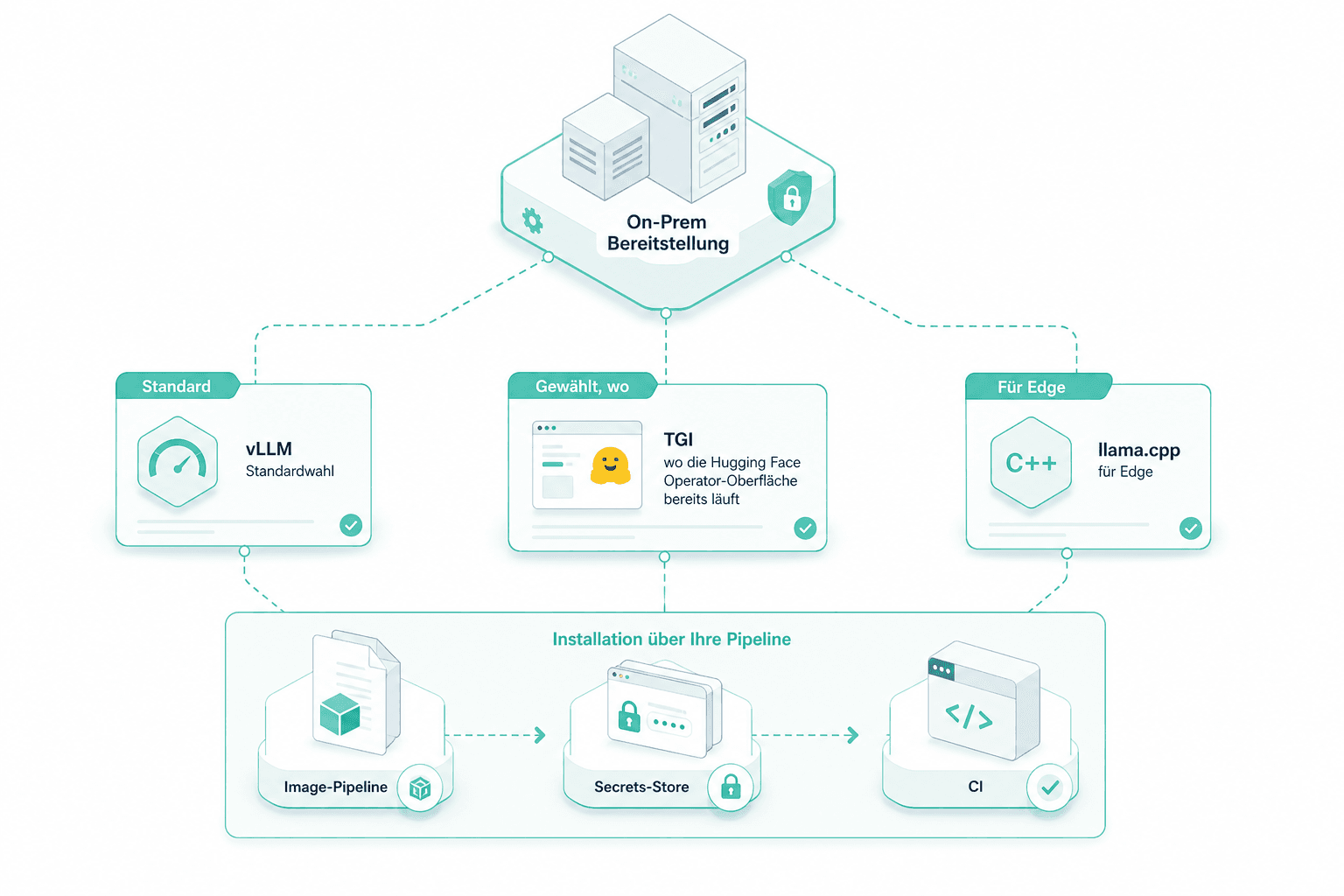
Installation und Wahl
vLLM ist Standard; TGI wird gewählt, wo die Hugging-Face-Operator-Oberfläche bereits läuft; llama.cpp bleibt für Edge. Die Installation läuft durch Ihre Image-Pipeline, Ihren Secrets-Store und Ihre CI.
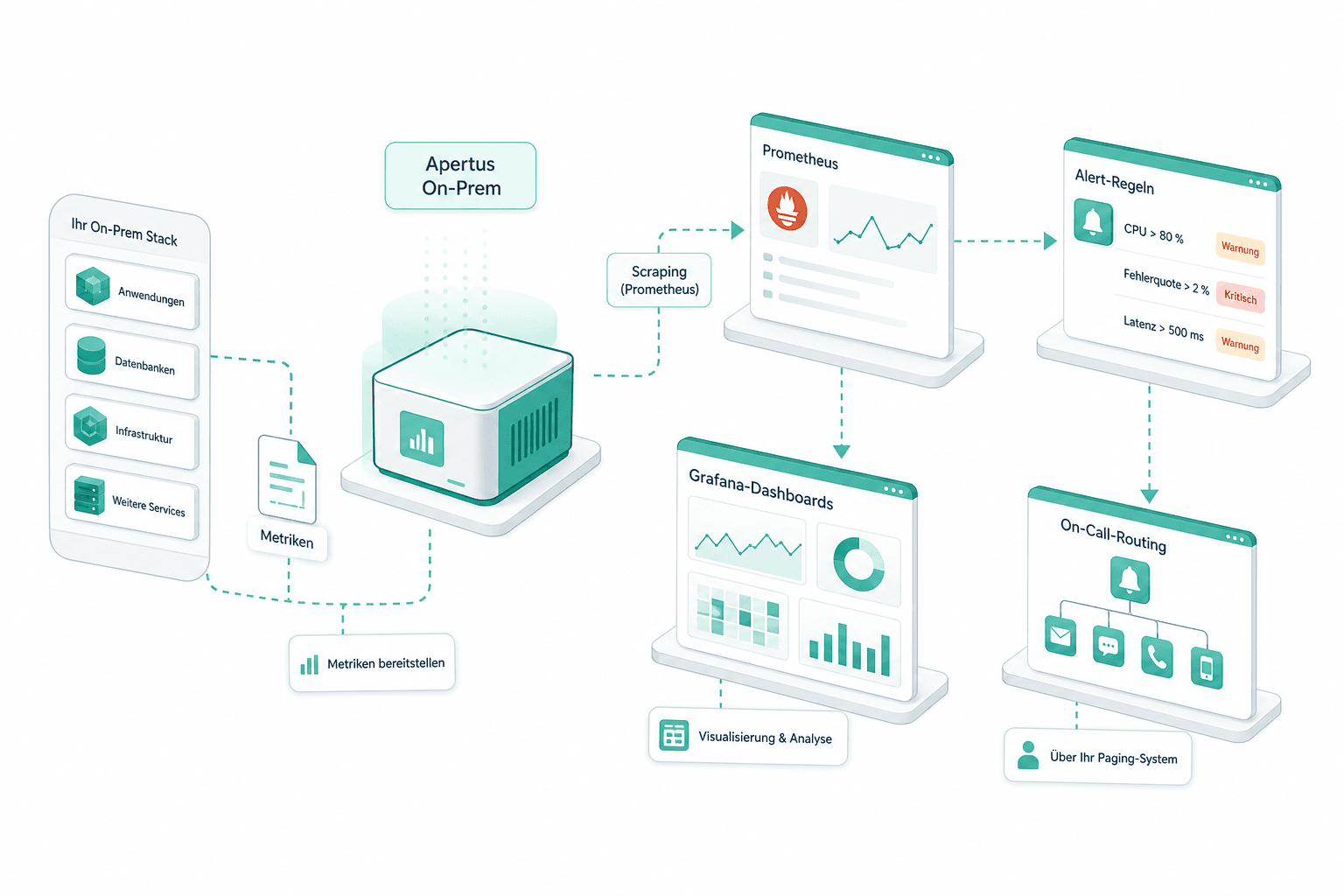
Monitoring und Alerting
Apertus liefert die Metriken, die Ihr Stack ohnehin spricht. Wir binden Prometheus-Scraping, Grafana-Dashboards und Alert-Regeln in Ihre bestehende Observability ein, mit On-Call-Routing über Ihr Paging-System.
Lasttest und Abnahme
Wir fahren einen repräsentativen Lasttest gegen Ihre Abnahmemenge unter erwarteter und gestresster Konkurrenz, erfassen p95- und p99-Latenz, Durchsatz und Fehlerverhalten und nehmen gemeinsam ab.
Go-Live und On-Call
Cutover läuft in einem definierten Fenster mit dokumentiertem Rollback. Wir bleiben durch den ersten Produktiv-Peak engagiert, übergeben Runbooks und Kapazitätsmodell und stehen unter SLA auf Abruf.

Workload-Klasse, Konkurrenz, Latenz-Budget und regulatorischer Rahmen — FINMA, kantonale Datenresidenz, Gesundheitsregulierung — werden in zwei bis vier Wochen erfasst. Das Ergebnis ist das Sizing-Briefing.
Wir dimensionieren gegen Ihren echten Prompt-Mix und Ihre Konkurrenz, nicht gegen ein Standardrezept. Der Plan benennt GPU-Klasse (H100, A100 oder L40S), Node-Topologie, Netz- und Storage-Budget sowie 8B oder 70B.
vLLM ist Standard; TGI wird gewählt, wo die Hugging-Face-Operator-Oberfläche bereits läuft; llama.cpp bleibt für Edge. Die Installation läuft durch Ihre Image-Pipeline, Ihren Secrets-Store und Ihre CI.
Apertus liefert die Metriken, die Ihr Stack ohnehin spricht. Wir binden Prometheus-Scraping, Grafana-Dashboards und Alert-Regeln in Ihre bestehende Observability ein, mit On-Call-Routing über Ihr Paging-System.
Wir fahren einen repräsentativen Lasttest gegen Ihre Abnahmemenge unter erwarteter und gestresster Konkurrenz, erfassen p95- und p99-Latenz, Durchsatz und Fehlerverhalten und nehmen gemeinsam ab.
Cutover läuft in einem definierten Fenster mit dokumentiertem Rollback. Wir bleiben durch den ersten Produktiv-Peak engagiert, übergeben Runbooks und Kapazitätsmodell und stehen unter SLA auf Abruf.
Warum Apertus on-prem mit uns
On-Prem ist die Arbeit — das Modell ist der einfache Teil
Wir installieren den Inferenz-Server, dimensionieren die GPUs gegen Ihren echten Prompt-Mix, binden Monitoring an Ihr bestehendes Prometheus und bleiben durch den ersten Produktiv-Peak auf Abruf. On-Prem ist die Arbeit — das Modell ist der einfache Teil.
Schweizer Lieferung für regulierte Workloads
Das Engineering-Team sitzt in der Schweiz und der EU; das Deployment landet in Ihrem Rechenzentrum oder in einer souveränen Swiss-Cloud. Der Rahmen passt zu FINMA, kantonaler Datenresidenz und Gesundheitsregulierung — wir implementieren unter diesen Regimes, wir verkaufen keine Zertifizierung. Für die Hosting-Alternative siehe Swiss-Datensouveränität-Hosting.
Sizing auf Ihrem Prompt-Mix, nicht auf einem Model-Card
GPU-Sizing wird in der Discovery gegen die Prompts entschieden, die Ihre Nutzer wirklich schicken, und gegen die Konkurrenz, die Sie wirklich sehen. Apertus-On-Prem-Cluster leben auf H100-, A100- oder L40S-Klasse-Hardware; 8B oder 70B werden nach Workload gewählt, nicht aus Begeisterung. Hardware bleibt kundenseitig beschafft.
Eine Plattform von POC über RAG bis Fine-Tuning
Dasselbe Engagement-Team, das den Produktiv-Rollout fährt, leitet auch den vorgelagerten Apertus-Evaluation-POC und die nachgelagerten Phasen Fine-Tuning und RAG-Integration. Das Plattform-Rückgrat — Laravel, Next.js, PostgreSQL mit pgvector, Redis, Mastra — liegt unter unseren Apertus-Swiss-LLM-Engagements und der AI-Consulting-Praxis.
Häufig gestellte Fragen
Das Engagement deckt Installation, GPU-Sizing gegen Ihren echten Prompt-Mix, Inferenz-Server-Setup mit vLLM oder TGI, Monitoring im Observability-Stack, Lasttests gegen Ihre Abnahmemenge und eine produktive SLA ab. Discovery und ein Apertus-POC laufen im Vorlauf.
Das Sizing wird in der Discovery gegen Prompt-Mix, Konkurrenzlast und Latenzziele entschieden. Apertus-On-Prem-Cluster nutzen typischerweise H100-, A100- oder L40S-Klasse; die 8B-Variante toleriert kleinere und quantisierte Footprints, die 70B schwerere Hardware.
vLLM ist der Standard für durchsatzstarke Serverseiten-Inferenz. TGI passt dort, wo die Hugging-Face-Operator-Oberfläche bereits im Einsatz ist. llama.cpp bleibt für Edge oder Entwickler-Laptops, nicht für Produktion. Die Wahl hängt am Konkurrenzprofil und am Betriebsteam.
Apertus wird an Ihr bestehendes Prometheus und Grafana angebunden, mit Alerting an Ihr On-Call-System. Metriken decken GPU-Auslastung, Queue-Tiefe, Prompt- und Completion-Längen, Latenz und Fehlerklassen ab. Ihr Plattform-Team sieht die Inferenz wie jeden anderen Produktivdienst.
Die SLA ist auf die Workload-Klasse zugeschnitten — interaktiver Chat, Batch-Anreicherung oder Background-RAG — und deckt Reaktionsziele, On-Call-Fenster, Vorfallklassifikation und Eskalation ab. Ziele werden in der Discovery gegen das Latenz-Budget Ihrer Anwendung vereinbart.
Ein typisches Apertus-Produktiv-Deployment läuft sechs bis zehn Wochen von der Beauftragung bis zur Live-Inferenz, sofern GPUs verfügbar sind. Discovery und POC liegen davor; Fine-Tuning und RAG dahinter.
Über SAPIENTROQ![]()
Sind Sie an einer Lösung interessiert?
Wir freuen uns, Ihnen die Möglichkeiten unverbindlich aufzuzeigen.

Roland Kurmann
CEO, SAPIENTROQ