Klassifizieren & Extrahieren
Suite für intelligente Dokumentenverarbeitung
Produktionsreife IDP, keine reine Demo
Wir liefern eine komplette IDP-Pipeline, die sich in Ihren Stack einfügt. Sie klassifiziert jedes eingehende Dokument, extrahiert die Felder, die Ihre nachgelagerten Systeme erwarten, und stellt eine rollenbasierte Prüfoberfläche bereit. Das Ergebnis sind verlässliche Daten, denen ERP und PIM vertrauen können.
Mehrformat-Eingang ohne Vorsortierung
PDFs, Bild-Scans, Word- und Excel-Anhänge, Lieferantendatenblätter und E-Mail-Inhalte laufen durch denselben Ablauf. Mistral OCR arbeitet in zwei Durchläufen: zuerst Rohtext, dann strukturierter Text. Handgeschriebene Belege und mehrspaltige Rechnungen werden zuverlässig als sauberer Text extrahiert.
KI-Klassifikation nach Ihrer Taxonomie
Die Klassifikation folgt einem vom Administrator definierten Kategoriemodell, nicht starren Regeln. Jede Kategorie legt Dokumenttypen, Pflichtfelder und die Prüfrolle fest. Neue Familien wie Leistungsabrechnung oder Lieferschein sind eine Konfigurationssache. Die KI-Dokumentenklassifizierung folgt Ihrem Schema, nicht umgekehrt.
Strukturierte JSON-Extraktion
Nach der Klassifikation wird jedes Dokument an das passende Extraktionsschema weitergeleitet: Feldblöcke, Felder, Typen, Pflicht- und Optionalkennzeichen. Im JSON-Modus von OpenAI liefert das Modell die Nutzdaten genau in der Struktur, die das nachgelagerte System erwartet. Die Dokumentenextraktion liefert typisiertes JSON.
Rollenbasierte HITL-Prüfung
Extraktionen mit geringer Konfidenz, nicht zugeordnete Kategorien und Policy-Ausnahmen landen in der HITL-Warteschlange bei der zuständigen Rolle. Genehmigte Daten fließen weiter, abgelehnte werden im Prompt-Register als Trainingssignal abgelegt. So bleibt die KI-gestützte Dokumentenverarbeitung verifiziert, nicht bloss angenommen.
Viersprachige Schweiz: DE/EN/FR/IT
Das Schweizer Back-Office ist selten einsprachig. Jede Kategorie, jeder Feldblock und jede Prüfoberfläche bringt DE- und EN-Locales von Haus aus mit. Französisch und Italienisch lassen sich ohne Code-Änderung über das Prompt-Register ergänzen. Ein Lieferantenblatt aus der Romandie, eine Leistungsabrechnung aus Zürich und ein Vertrag aus dem Tessin laufen durch dieselbe Pipeline.
Schweizer Datenresidenz auf Wunsch
Für FINMA-, MDR- und IVDR-sensible Workloads läuft die Engine auf Schweizer Hosting oder on-prem beim Kunden. Mit dem Apertus-Modul steht zusätzlich ein souveräner LLM-Pfad bereit — Inhalte verlassen die Schweiz oder die EU nicht. Jede Klassifikations- und Extraktionsentscheidung wird revisionssicher protokolliert.
Unser Vorgehen
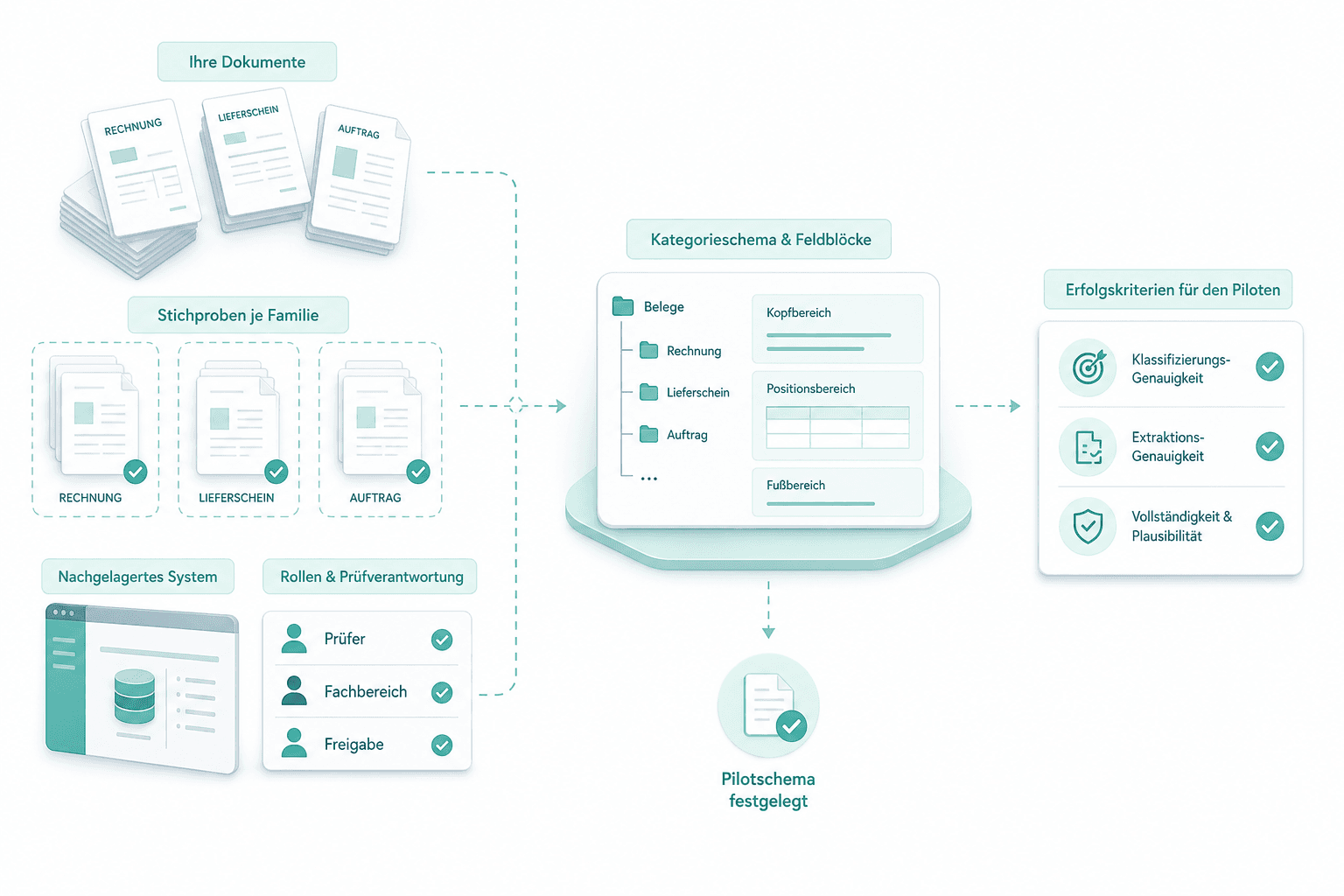
Discovery und Schemafestlegung
Wir beginnen mit Ihren Dokumenten: Stichproben je Familie, das nachgelagerte System, das die Daten weiterverarbeitet, und die Rollen mit Prüfverantwortung. Daraus leiten wir das Kategorieschema, die Feldblöcke und die Erfolgskriterien für den Piloten ab.
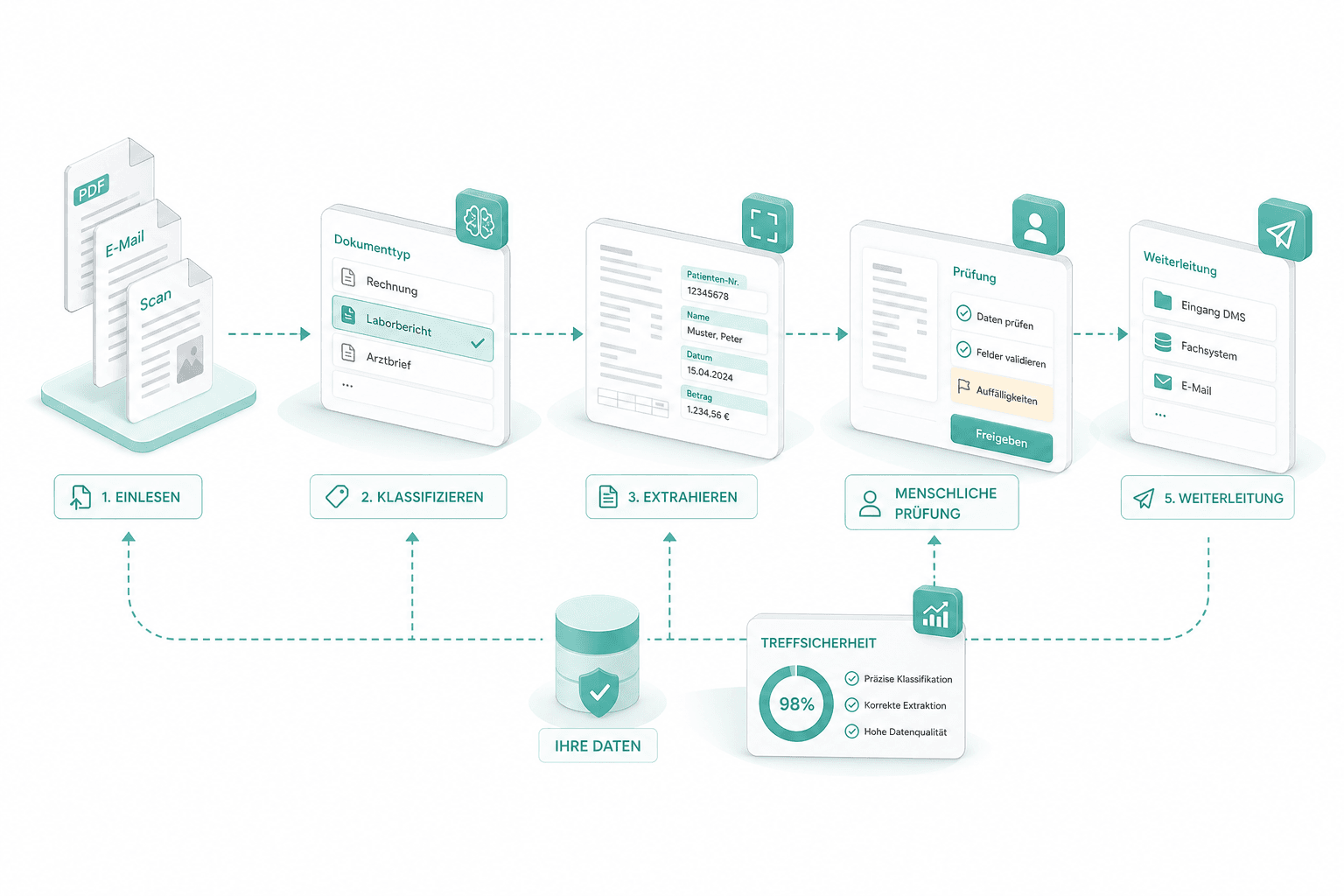
Pilotfamilie produktiv setzen
Wir setzen die Pipeline für diese Familie durchgängig auf: Einlesen, Klassifizieren, Extrahieren, menschliche Prüfung und Weiterleitung. Weita und Sanitas sind genau so gestartet. Die Treffsicherheit belegen wir mit Ihren eigenen Daten.
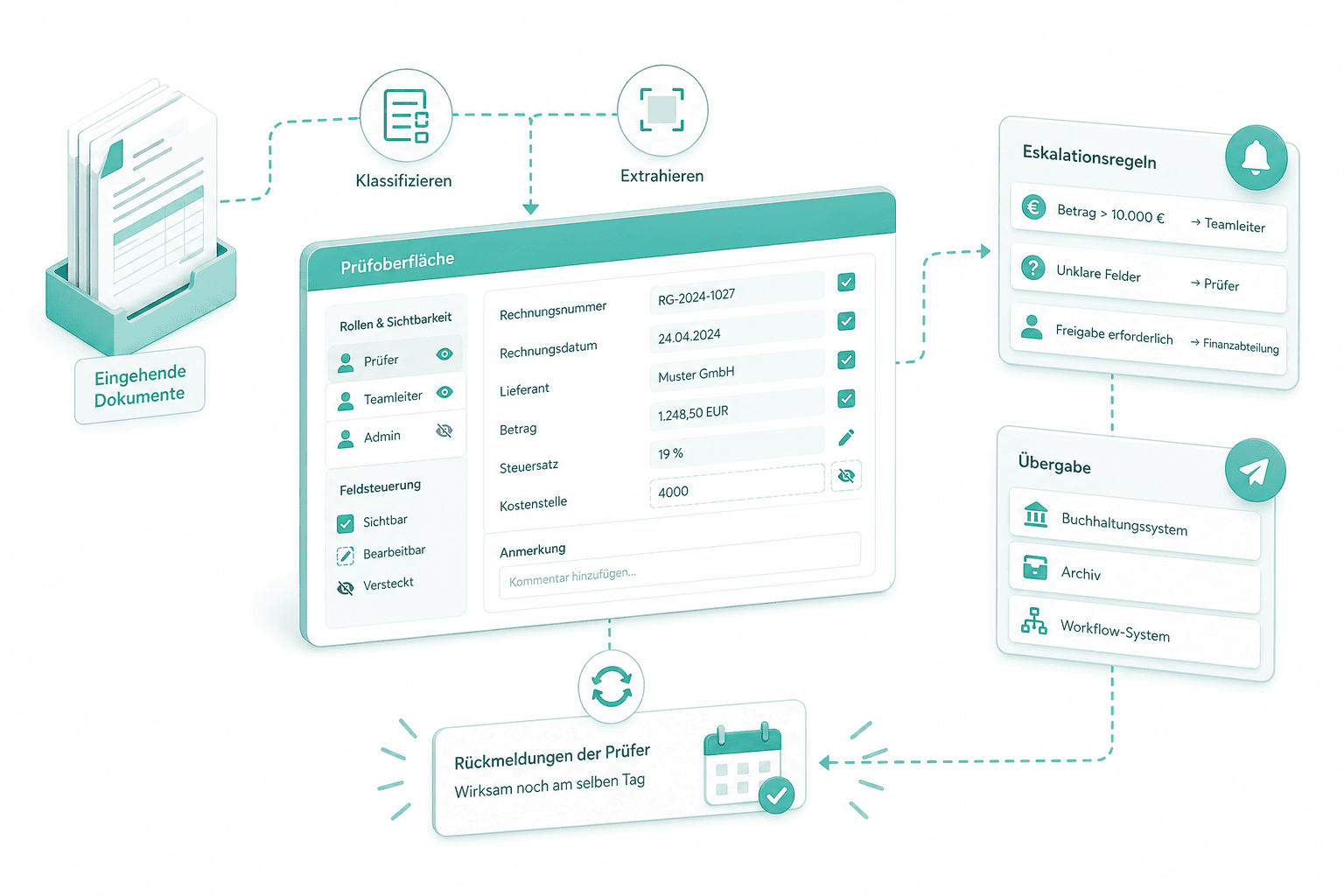
Prüfoberfläche feinjustieren
Wir passen die Prüfoberfläche an Ihre Rollen an: wer sieht und bearbeitet welche Felder, wann eskaliert das System, wohin geht die Übergabe. Rückmeldungen der Prüfer wirken sich noch am selben Tag im System aus.
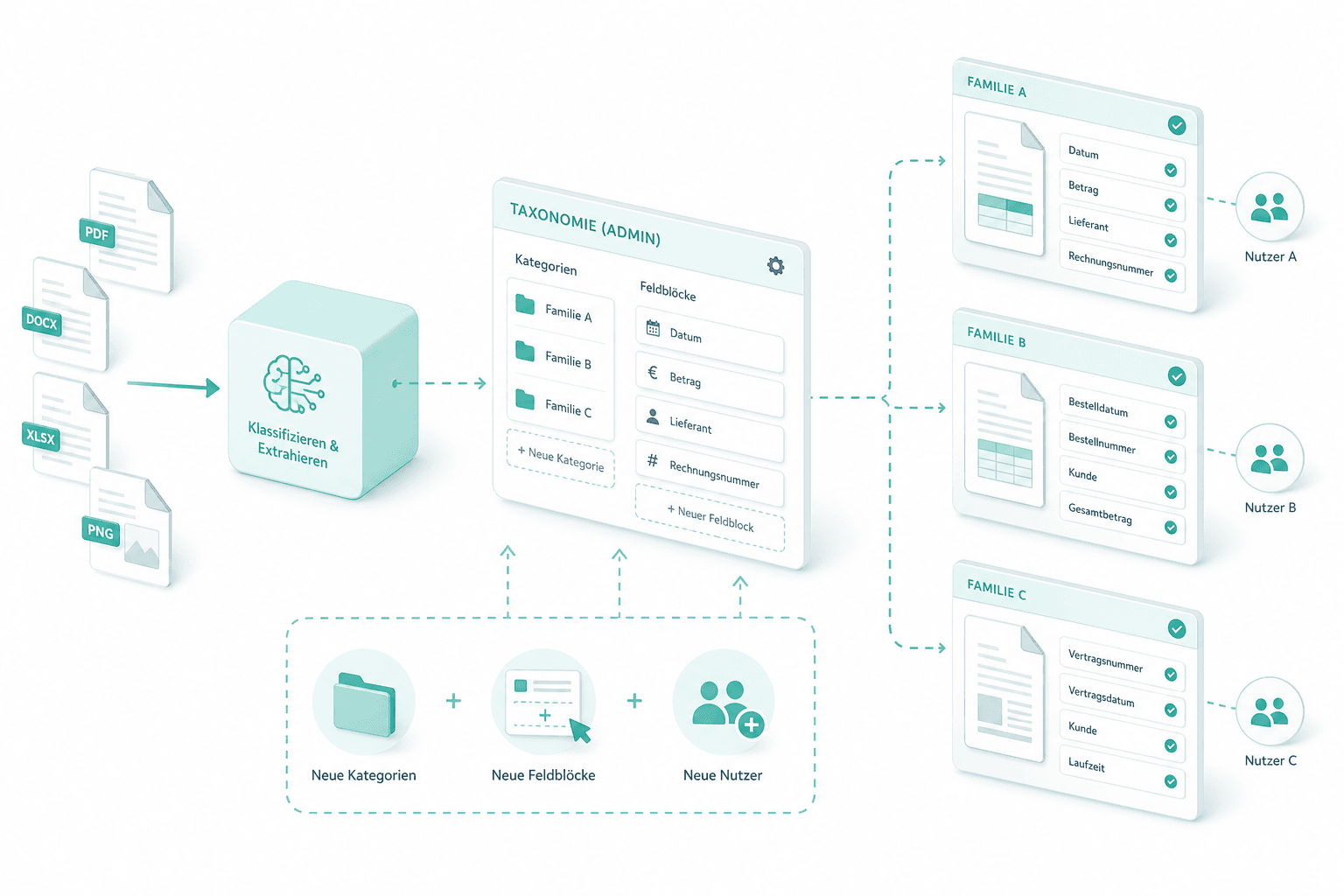
Horizontale Skalierung
Sobald die erste Familie stabil läuft, erweitern wir die Taxonomie: neue Kategorien, neue Feldblöcke, neue Nutzer. Weil die Dokumentenklassifizierung dem vom Administrator definierten Schema folgt, ist jede weitere Familie ein reiner Konfigurationsschritt.
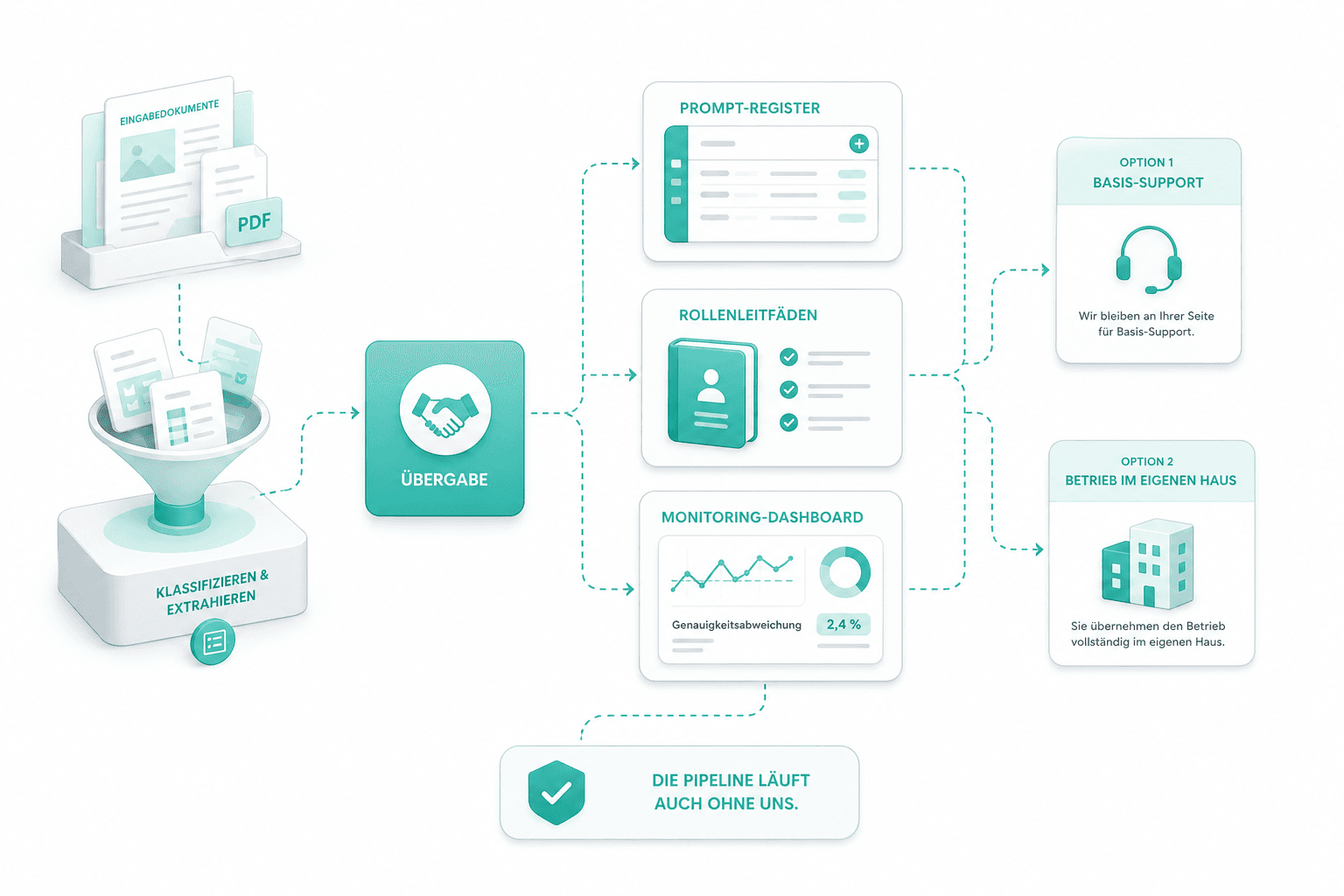
Übergabe und Betrieb
Wir übergeben den Zugang zum Prompt-Register, die Rollenleitfäden und das Monitoring-Dashboard für Genauigkeitsabweichungen. Die meisten Kunden behalten uns für Basis-Support; andere übernehmen den Betrieb vollständig im eigenen Haus. Die Pipeline läuft auch ohne uns.
Wir beginnen mit Ihren Dokumenten: Stichproben je Familie, das nachgelagerte System, das die Daten weiterverarbeitet, und die Rollen mit Prüfverantwortung. Daraus leiten wir das Kategorieschema, die Feldblöcke und die Erfolgskriterien für den Piloten ab.
Wir setzen die Pipeline für diese Familie durchgängig auf: Einlesen, Klassifizieren, Extrahieren, menschliche Prüfung und Weiterleitung. Weita und Sanitas sind genau so gestartet. Die Treffsicherheit belegen wir mit Ihren eigenen Daten.
Wir passen die Prüfoberfläche an Ihre Rollen an: wer sieht und bearbeitet welche Felder, wann eskaliert das System, wohin geht die Übergabe. Rückmeldungen der Prüfer wirken sich noch am selben Tag im System aus.
Sobald die erste Familie stabil läuft, erweitern wir die Taxonomie: neue Kategorien, neue Feldblöcke, neue Nutzer. Weil die Dokumentenklassifizierung dem vom Administrator definierten Schema folgt, ist jede weitere Familie ein reiner Konfigurationsschritt.
Wir übergeben den Zugang zum Prompt-Register, die Rollenleitfäden und das Monitoring-Dashboard für Genauigkeitsabweichungen. Die meisten Kunden behalten uns für Basis-Support; andere übernehmen den Betrieb vollständig im eigenen Haus. Die Pipeline läuft auch ohne uns.
Ausgewählte Projekte
SWISS INSURANCE POC (NDA)
POC zur Automatisierung von Versicherungsdokumenten

Wie SAPIENTROQ einen schema-getriebenen POC zur Automatisierung von Versicherungsdokumenten fur ein Schweizer Backoffice lieferte: Mistral OCR plus OpenAI JSON-Modus, Schemata live aus Admin-Konfiguration generiert, KI-Anbieter tauschbar hinter einer Schnittstelle.
Fall ansehen
SANITAS TROESCH
PIM-Implementierung mit HITL-KI für Sanitas Troesch
Wie SAPIENTROQ eine PIM-Implementierung mit einer Multi-Agent-HITL-Pipeline lieferte, die 200k+ Lieferanten-SKUs aus PDFs, Excel und Jira in das Sanitas-Troesch-PIM mit prüffähiger Governance einspielt.
Fall ansehen
Diese Engine, kein generisches IDP
Sie kontrollieren das Schema, nicht der Anbieter
Die meisten IDP-Produkte bringen ihre eigene Taxonomie mit und zwingen Sie, Ihre Daten daran auszurichten. Wir drehen es um: Ihr Modell aus Kategorien und Feldblöcken ist die Spezifikation, an die sich die KI bindet. Fügt das operative Team im sechsten Monat eine neue Familie hinzu, konfigurieren Sie das selbst — kein Ticket beim Anbieter.
Auf Schweizer Anforderungen gebaut, nicht nachgerüstet
Weita, Sanitas Troesch und der Insurance-AI-POC laufen mit derselben Engine in Schweizer Back-Office-Umgebungen. Zweisprachige EN/DE-Verarbeitung von Haus aus. Mistral OCR liefert den Two-Pass-Klassifikator. Die Editieroberfläche für die Dokumentenextraktion basiert auf Reverb, unserem internen Editor-Stack.
HITL wo nötig, Automatisierung wo möglich
Wir tun nicht so, als wäre das Modell zu 100 % korrekt. Extraktionen mit geringer Konfidenz und nicht zugeordnete Kategorien landen in der rollenbasierten Prüf-Warteschlange; Freigaben fliessen zurück ins Prompt-Register. Routinedokumente mit hoher Konfidenz überspringen die Warteschlange.
Eine Engine, drei bewährte Branchen
Dieselbe Architektur trägt das Grosshandels-PIM bei Weita, das Bau-Onboarding bei Sanitas Troesch und die Versicherungsschäden im POC. Neue Branchen erben das fertige Muster — sie erweitern die Engine, statt sie neu zu bauen.
Revisionssicher von Anfang an
Jeder Schritt wird protokolliert: Kategorie, Prompt-Version, Modell-ID, Freigabe-Rolle. Der Audit-Pfad ist Standard, nicht nachträglich angefügt. Für FINMA-, MDR- und IVDR-sensible Kunden ist die DSGVO-Konfiguration Teil der Deployment-Vorlage — inklusive nachvollziehbarer Provenienz der Dokumentenklassifizierung.
Häufig gestellte Fragen
OCR wandelt Dokumentenbilder in Zeichen um. Intelligente Dokumentenverarbeitung geht weiter: Sie ordnet das Dokument einer fachlichen Kategorie zu (Rechnung, Bestellung, Lieferschein), extrahiert die Felder und schickt Ausnahmen an den richtigen Prüfer. OCR ist im IDP der erste Schritt.
PDFs (digital und gescannt), Bilder, Word- und Excel-Anhänge, Lieferantendatenblätter und E-Mail-Inhalte. DE und EN von Haus aus. Französisch und Italienisch über das Prompt-Register. Schweizerdeutsch wird als DE behandelt — vier Amtssprachen, eine Pipeline.
Jede Extraktion gibt neben den Daten ein Konfidenzsignal zurück. Liegt es unter der Feld-Schwelle, landet das Dokument in der rollenbasierten Prüf-Warteschlange. Der Prüfer korrigiert, ordnet neu ein oder lehnt ab — die Korrektur fliesst zurück ins Prompt-Register.
Ja. Kategorie, Feldblock und Feld sind vom Administrator definierte Modelle. Die Operations-Administration legt eine neue Familie an, definiert Pflichtfelder und Prüfrolle. Die Pipeline übernimmt die Taxonomie beim Speichern und routet passende Dokumente beim nächsten Eingang.
Standard-Deployment ist EU-Hosting mit DSGVO-Konformität. Für FINMA-, MDR- oder IVDR-sensible Workloads setzen wir auf Schweizer Hosting oder on-prem. Wenn kein öffentliches Modell erreichbar sein darf, nutzen wir den souveränen LLM-Pfad über Apertus.
Den Piloten starten wir mit einer Dokumentenfamilie auf einer typischen Stichprobe. Klassifikation, Extraktion und HITL-Prüfung zeigen in den ersten Wochen die ersten vollständigen Durchläufe. Sobald die Genauigkeit gesichert ist, kommen weitere Familien dazu.
Hyperscaler-IDP-Produkte liefern einen verwalteten Extraktionsdienst. Pipeline, Taxonomie, HITL-Oberfläche und die Anbindung an nachgelagerte Systeme bleiben bei Ihnen. Wir liefern die komplette Verarbeitungskette mit Ihrer Taxonomie als Spezifikation; die Modellschicht bleibt austauschbar.
Nein. Wir übergeben Prompt-Register, Kategorie- und Feldblock-Konfiguration, Rollendefinitionen und Betriebs-Runbook. Die meisten Kunden behalten uns für Basis-Support. Die Modellschicht bleibt anbieterneutral.
Über SAPIENTROQ![]()
Sind Sie an einer Lösung interessiert?
Wir freuen uns, Ihnen die Möglichkeiten unverbindlich aufzuzeigen.

Roland Kurmann
CEO, SAPIENTROQ