Daten aus Dokumenten extrahieren
Suite für Dokumentendatenextraktion
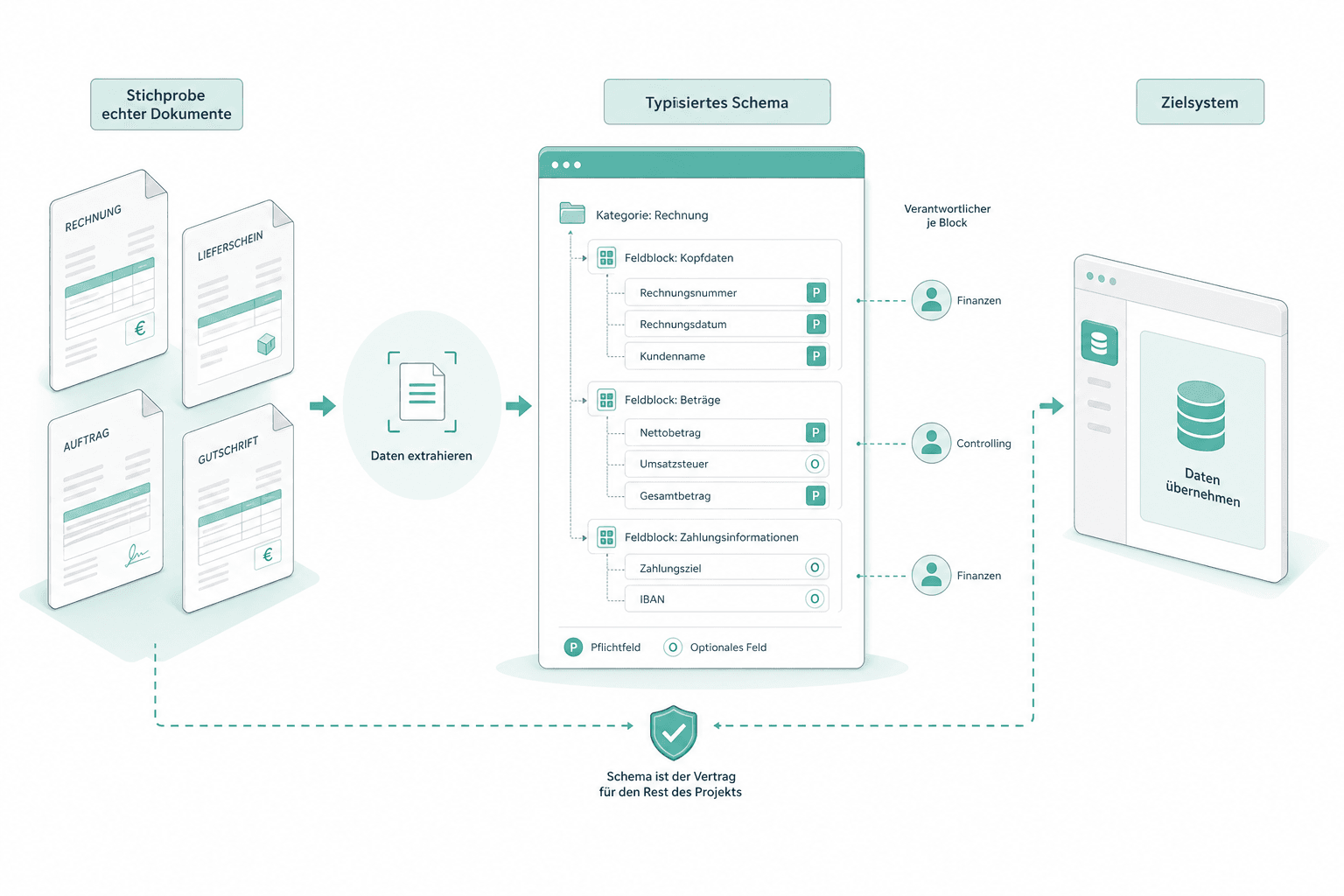
Typisiertes Schema statt freier Prompts
Die Extraktion ist an ein typisiertes Schema aus Kategorie, Unterkategorie, Feldblock und Feld gebunden. Jedes Feld hat einen Typ, ein Pflicht- oder Optionalkennzeichen und einen nachgelagerten Verantwortlichen. Das Modell muss diese Form füllen — es darf keine Fliesstexte über das Dokument schreiben. ERP, PIM oder Falldatensystem auf der anderen Seite erhalten Daten, die sie vor dem Speichern validieren können.
OpenAI JSON-Modus gegen das Schema
Der Extraktor läuft im JSON-Modus von OpenAI und ist durch die Felddefinitionen auf der Platte eingeschränkt. Fehlende Felder bleiben null, typisierte Felder bleiben typisiert, das Modell darf keine eigenen Schlüssel erfinden. Genau dieses Muster ist bei Weita in Produktion; im Insurance-AI-POC liegt zusätzlich eine Konfigurationsoberfläche darüber, mit der Operations das Schema ohne Entwickler-Release erweitert.
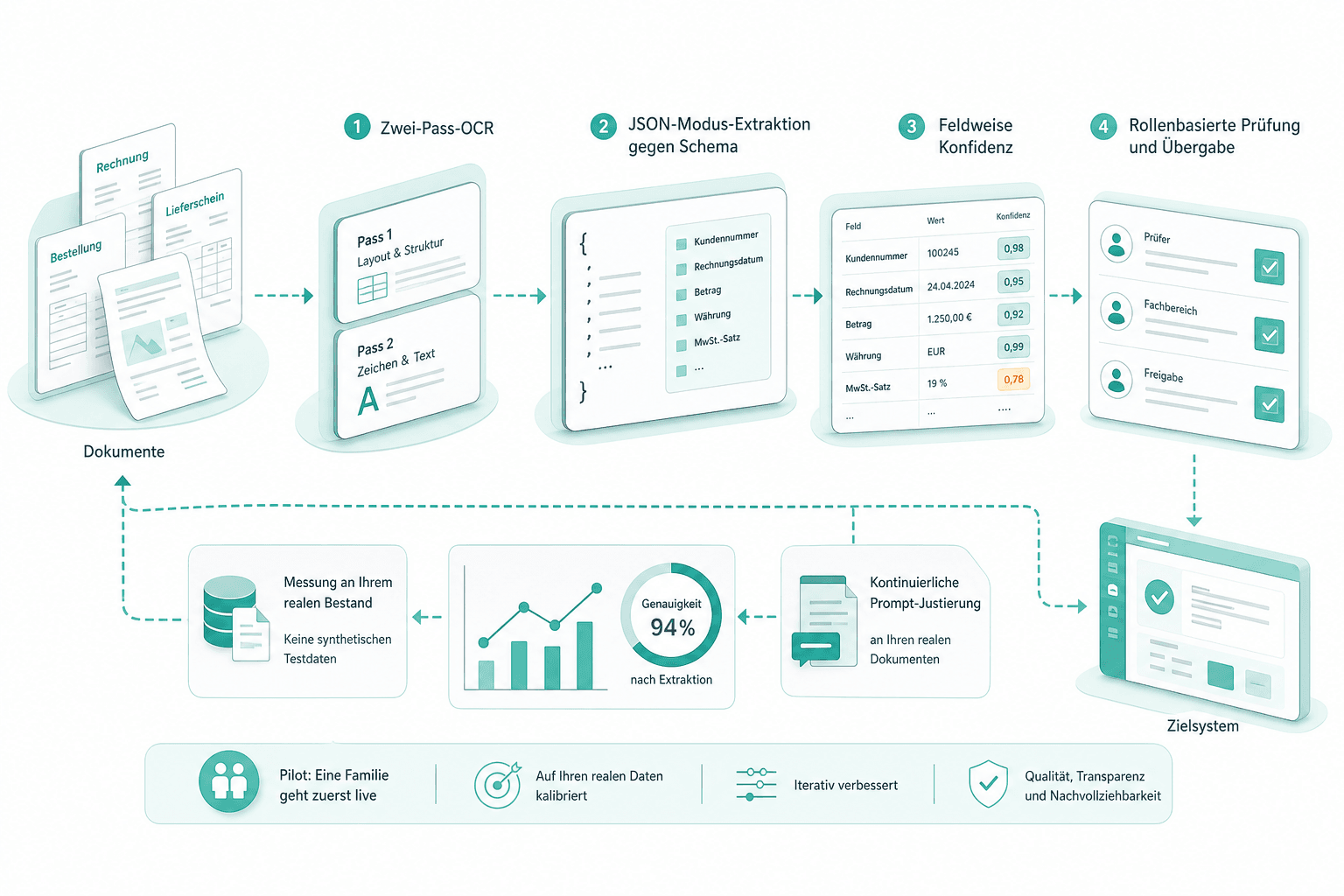
Two-Pass-OCR für schwierige Scans
Vor der Extraktion durchlaufen gescannte Seiten und Bild-PDFs Mistral OCR in zwei Durchgängen — erst Rohtext, dann ein strukturierter Durchgang, der Tabellen und Spalten erhält. Mehrspaltige Rechnungen, handgeschriebene Belege und verrauschte Faxe speisen denselben Extraktor wie digitale PDFs. Keine separate Pipeline je Format.
Konfidenz pro Feld, nicht pro Dokument
Die Konfidenz wird je Feld geführt, nicht je Dokument. Ein Lieferschein mit klarem Datum und unsicherer Endsumme schickt nur die Summe in die Prüfung — der Rest fliesst direkt ins Zielsystem. Die Prüferin korrigiert den einen Wert, das Dokument schliesst ab, und die Korrektur wird gegen die Prompt-Version protokolliert, die den ursprünglichen Vorschlag erzeugt hat.
Stufige Pipeline mit Revisionsspur
Die Extraktion läuft als stufige Laravel-Job-Queue mit expliziten Erfolgs- und Fehlerzuständen je Stufe — PrepareFile, RecognizeImages, ExtractMetadata, ExtractDetails, SaveFile, Notification. Jede Stufe protokolliert Eingabe, Prompt-Version, Modell, Ausgabe und Bearbeiter. Wiederholungsläufe nach einem Prompt-Update bleiben deterministisch gegenüber derselben Quelldatei.
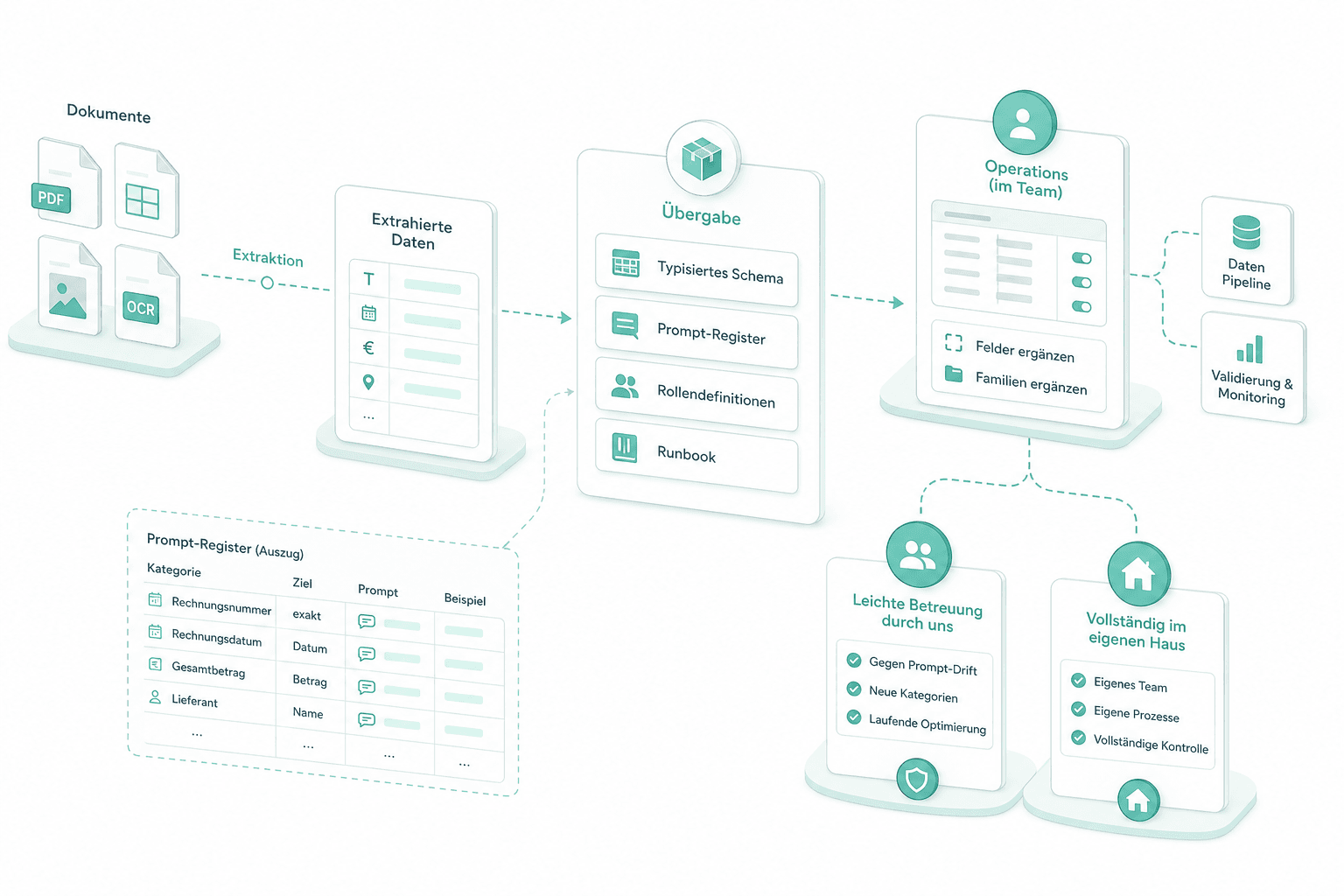
Neue Familien und Felder als Konfiguration
Eine neue Dokumentenfamilie oder ein neues Feld auf einer bestehenden ist Administrationsarbeit, keine Entwicklungsarbeit. Operations legt den Feldblock und seine Felder an, verknüpft die Familie mit einer Prüfrolle und einem Zielsystem — das nächste eingehende Dokument dieser Form läuft hindurch. Der Insurance-AI-POC liefert diese Oberfläche direkt für die Administratoren des Kunden.
Unser Vorgehen
Schema-Discovery an echten Dokumenten
Wir beginnen mit einer Stichprobe Ihrer realen Dokumente und dem Zielsystem, das die extrahierten Daten aufnimmt. Daraus entsteht das typisierte Schema: Kategorien, Feldblöcke, Felder, Pflicht- und Optionalkennzeichen, ein nachgelagerter Verantwortlicher je Block. Dieses Schema ist der Vertrag für den Rest des Projekts.
Pilot-Extraktion an einer Familie
Eine Familie geht zuerst durchgängig live: Two-Pass-OCR, JSON-Modus-Extraktion gegen das Schema, feldweise Konfidenz, rollenbasierte Prüfung und Übergabe ans Zielsystem. Wir messen die Genauigkeit an Ihrem realen Bestand, nicht an einem synthetischen Testset, und justieren Prompts an Dokumenten, die Sie heute bereits manuell bearbeiten lassen.
Feldweise HITL-Feinjustierung
Wir stimmen die Prüfoberfläche auf Ihre Rollen und Ihr Risikoprofil ab: welche Felder bei welcher Konfidenz automatisch schreiben, welche immer eine Freigabe brauchen, wohin Eskalationen gehen. Rückmeldungen der Prüfenden fliessen in das Prompt-Register zurück, sodass derselbe Fehler in der jeweils nächsten Prompt-Version seltener auftritt.

Übergabe mit Prompt-Register
Bei der Übergabe übertragen wir das typisierte Schema, das Prompt-Register, die Rollendefinitionen und das Runbook. Operations kann Felder und Familien ohne uns ergänzen; die meisten Kunden behalten uns für leichte Betreuung gegen Prompt-Drift und neue Kategorien, andere führen die Pipeline ab Monat vier vollständig im eigenen Haus.
Wir beginnen mit einer Stichprobe Ihrer realen Dokumente und dem Zielsystem, das die extrahierten Daten aufnimmt. Daraus entsteht das typisierte Schema: Kategorien, Feldblöcke, Felder, Pflicht- und Optionalkennzeichen, ein nachgelagerter Verantwortlicher je Block. Dieses Schema ist der Vertrag für den Rest des Projekts.
Eine Familie geht zuerst durchgängig live: Two-Pass-OCR, JSON-Modus-Extraktion gegen das Schema, feldweise Konfidenz, rollenbasierte Prüfung und Übergabe ans Zielsystem. Wir messen die Genauigkeit an Ihrem realen Bestand, nicht an einem synthetischen Testset, und justieren Prompts an Dokumenten, die Sie heute bereits manuell bearbeiten lassen.
Wir stimmen die Prüfoberfläche auf Ihre Rollen und Ihr Risikoprofil ab: welche Felder bei welcher Konfidenz automatisch schreiben, welche immer eine Freigabe brauchen, wohin Eskalationen gehen. Rückmeldungen der Prüfenden fliessen in das Prompt-Register zurück, sodass derselbe Fehler in der jeweils nächsten Prompt-Version seltener auftritt.
Bei der Übergabe übertragen wir das typisierte Schema, das Prompt-Register, die Rollendefinitionen und das Runbook. Operations kann Felder und Familien ohne uns ergänzen; die meisten Kunden behalten uns für leichte Betreuung gegen Prompt-Drift und neue Kategorien, andere führen die Pipeline ab Monat vier vollständig im eigenen Haus.
Ausgewählte Projekte
SWISS INSURANCE POC (NDA)
POC zur Automatisierung von Versicherungsdokumenten

Wie SAPIENTROQ einen schema-getriebenen POC zur Automatisierung von Versicherungsdokumenten fur ein Schweizer Backoffice lieferte: Mistral OCR plus OpenAI JSON-Modus, Schemata live aus Admin-Konfiguration generiert, KI-Anbieter tauschbar hinter einer Schnittstelle.
Fall ansehen
SANITAS TROESCH
PIM-Implementierung mit HITL-KI für Sanitas Troesch
Wie SAPIENTROQ eine PIM-Implementierung mit einer Multi-Agent-HITL-Pipeline lieferte, die 200k+ Lieferanten-SKUs aus PDFs, Excel und Jira in das Sanitas-Troesch-PIM mit prüffähiger Governance einspielt.
Fall ansehen
Diese Engine, keine generische Datenextraktion
Das Schema ist der Vertrag, der Prompt ist die Umsetzung
Freie Prompt-Extraktion bittet ein Modell, ein Dokument zu beschreiben, und hofft, dass die Ausgabe parsebar bleibt. Wir drehen das um: Ihr typisiertes Schema ist der Vertrag auf der Platte, der JSON-Modus bindet das Modell daran, und das Prompt-Register hält fest, wie konkret gefragt wird. Wenn die Extraktion driftet, ändern sich Prompts als Daten — nicht als Code-Release — und das Schema bleibt für die nachgelagerten Systeme stabil.
Konfidenz am Feld, nicht am Dokument
Konfidenz auf Dokumentebene erzwingt eine Alles-oder-nichts-Entscheidung in der Prüfung. Wir führen die Konfidenz pro Feld, sodass die Prüferin nur die Werte sieht, die wirklich eine menschliche Entscheidung brauchen, während der Rest des Datensatzes bereits geschrieben ist. Genau das macht Extraktion in hohem Volumen für Schweizer Back-Office-Teams tragfähig.
Revisionssicher von Anfang an
Jeder extrahierte Wert trägt seine Quellseite, die Prompt-Version, die Modellkennung und — falls ein Mensch eingegriffen hat — die prüfende Person und den vorherigen Wert. Diese Spur ist standardmässig aktiv, nicht nachträglich für ein Audit aufgesetzt. Für FINMA-, MDR- oder IVDR-relevante Abläufe ist die Provenienz jedes Feldes der Grund, warum Operations die Automatisierung mitträgt.
Häufig gestellte Fragen
OCR wandelt Pixel in Zeichen um. Klassifikation entscheidet, was das Dokument ist. Extraktion holt die konkreten typisierten Werte heraus — Rechnungsbetrag, Fälligkeitsdatum, Schadensreferenz, Lieferantennummer — und schreibt sie in das passende Feld im Zielsystem. Alle drei Schritte sitzen meist in derselben Pipeline, aber die Extraktion erzeugt die Daten, die ERP oder Falldatensystem am Ende wirklich speichern.
Freie Prompts zwingen Sie, den Fliesstext des Modells zurück in Felder zu zerlegen — und der Text ändert zwischen Läufen seine Form. Ein typisiertes Schema mit JSON-Modus bindet die Ausgabe an Ihre Felddefinitionen: Fehlende Felder bleiben null, typisierte Felder bleiben typisiert, keine erfundenen Schlüssel. Die nachgelagerte Validierung läuft gegen einen stabilen Vertrag statt gegen Regex über Fliesstext.
Jedes Feld bekommt sein eigenes Konfidenzsignal. Felder mit hoher Konfidenz schreiben automatisch ins Zielsystem. Felder mit niedriger Konfidenz erscheinen in einer rollenbasierten Prüf-Warteschlange — die Prüferin sieht den Seitenausschnitt und den Vorschlag, korrigiert bei Bedarf und gibt frei. Der Rest des Datensatzes ist bereits gespeichert, wenn sie das Feld berührt.
Ja. Kategorie, Unterkategorie, Feldblock und Feld sind vom Administrator definierte Modelle. Operations legt die neue Familie oder das neue Feld an, verknüpft es mit einer Prüfrolle und einem Zielsystem — das nächste eingehende Dokument dieser Form fliesst hindurch. Der Insurance-AI-POC liefert genau diese Administrationsoberfläche; Weita hat eine ähnliche Oberfläche für Prompt- und Kategorie-Pflege.
Digitale PDFs kommen oft mit dem Rohdurchgang aus. Gescannte Seiten, Bild-PDFs, mehrspaltige Rechnungen und handgeschriebene Belege profitieren vom strukturierten Mistral-Durchgang, der Tabellen und Spaltengrenzen erhält. Der Extraktor nutzt je Seite die sauberere der beiden Darstellungen — eine Pipeline für digitale und gescannte Eingänge, kein separater Codepfad.
Jeder extrahierte Wert trägt seine Quellseite, die Prompt-Version, die Modellkennung und — falls ein Mensch eingegriffen hat — die prüfende Person und den vorherigen Wert. Fehlerzustände sind explizit, nicht still. Für FINMA-pflichtige, MDR- oder IVDR-relevante Abläufe deployen wir auf Schweizer Hosting oder on-prem; die jeweiligen Branchenseiten beschreiben die Zertifizierungsposition im Detail.
Die Extraktion ist eine stufige Laravel-Job-Queue, deren letzte Stufe in Ihr System of Record schreibt. Der Vertrag ist das typisierte Schema — das Zielsystem erhält jedes Mal dieselbe Feldform. Bei Weita ist das Ziel ein modularer Laravel-PIM-Monolith; beim Insurance-AI-POC eine Falldatenbank; das Muster überträgt sich auf die meisten ERP- und PIM-Systeme.
Auf der Website nicht. Genauigkeit und Durchsatz hängen von der Dokumentenqualität, der Schemastrenge und der HITL-Schwelle ab, die der Kunde wählt. Wir messen beides während des Piloten an Ihrem realen Bestand und verhandeln gegen diese Zahlen. Allgemeine Genauigkeitsversprechen halten dem realen Dokumentenmix selten stand.
Über SAPIENTROQ![]()
Sind Sie an einer Lösung interessiert?
Wir freuen uns, Ihnen die Möglichkeiten unverbindlich aufzuzeigen.

Roland Kurmann
CEO, SAPIENTROQ