OCR Software fur Schweizer Dokumente
OCR Software, produktisiert
Zwei Durchlaufe statt einem Modellaufruf
Unsere OCR Software arbeitet im Zwei-Pass-Muster mit Mistral OCR. Der erste Durchlauf liefert den Rohtext der Seite. Der zweite Durchlauf liefert strukturierte Zonen: Tabellen, Spalten, Kopfzeilen, Schlussel-Wert-Bloecke. Ein einzelner Modellaufruf wuerde beides zu einer Annahme verschmelzen. Getrennte Durchlaufe geben dem nachgelagerten LLM-Extraktor sowohl die Worte als auch das Layout — und er entscheidet pro Feld, welcher Eingabe er vertraut.
Schweizerdeutsch und deutsche Formulare
Mehrspaltige deutsche Rechnungen, handschriftliche Schweizerdeutsch-Notizen auf Lieferantendatenblaettern und zweisprachige DE/EN-Formulare laufen durch dieselbe OCR-Schicht. Schweizerdeutsch wird auf OCR-Ebene als DE behandelt — kein separates Mundartmodell noetig. Der OCR-Schweiz-Anspruch ist kein Marketing: die Schicht ist gegen die Dokumente gehaertet, die bei Weita und Sanitas Troesch produktiv ankommen.
Scans, Fotos, gemischte PDFs
Echte Dokumente im Schweizer Back-Office sind selten saubere digitale PDFs. Fotografierte Belege, Archivscans mit Durchscheinen, Handy-Aufnahmen von Papierdokumenten, mehrseitige PDFs mit gemischten digitalen und gescannten Seiten. Die OCR-Schicht behandelt jede Eingabeform am selben Kontrakt: Rohtext plus strukturierte Zonen heraus, bereit fur den naechsten Schritt.
OCR-API fur Ihren Extraktor
Die OCR-Schicht ist nicht die Antwort, sondern der Kontrakt zum nachgelagerten Extraktor. Sie laesst sich in unseren S001.1-Klassifikations- und Extraktionsservice einklinken, in unseren S001.2-Feldextraktions-Service oder in Ihren eigenen LLM-Extraktor — der OCR-Pass liefert immer beides: Rohtext und strukturierte Zonen, damit ein Extraktor pro Feld die passende Eingabe waehlt.
Stapel und Echtzeit
Der OCR-Schritt laeuft in einer mehrstufigen Laravel-Job-Queue. Fuer naechtliche Stapellaeufe — Lieferantendatenblatt-Importe, Archiv-Ingest — skalieren Docker-Worker horizontal. Fuer Portal-Uploads, bei denen ein Nutzer wartet, laeuft derselbe Schritt synchron und liefert binnen Sekunden zurueck. Gleicher Codepfad, andere Queue-Prioritaet — keine Gabelung zwischen Stapel und Online.
Schweizer Datenresidenz auf Wunsch
Fuer datensensible Workloads laeuft die OCR-Schicht auf Schweizer Hosting oder on-prem beim Kunden. Wo Dokumenteninhalte die Schweiz oder die EU nicht verlassen duerfen, steht der Apertus-Pfad fuer den Extraktor bereit. Jeder OCR-Pass wird mit Modell-ID und Version protokolliert — die Herkunft des extrahierten Textes ist nachgelagert revisionssicher nachvollziehbar.
Unser Vorgehen
Stichprobe und Eingabe-Audit
Wir beginnen mit Ihren echten Dokumenten: gescannte Datenblaetter, fotografierte Belege, Archiv-PDFs, zweisprachige Formulare. Wir gleichen ab, was heute im Posteingang ankommt und was Ihr nachgelagertes System tatsaechlich als Eingabe braucht.
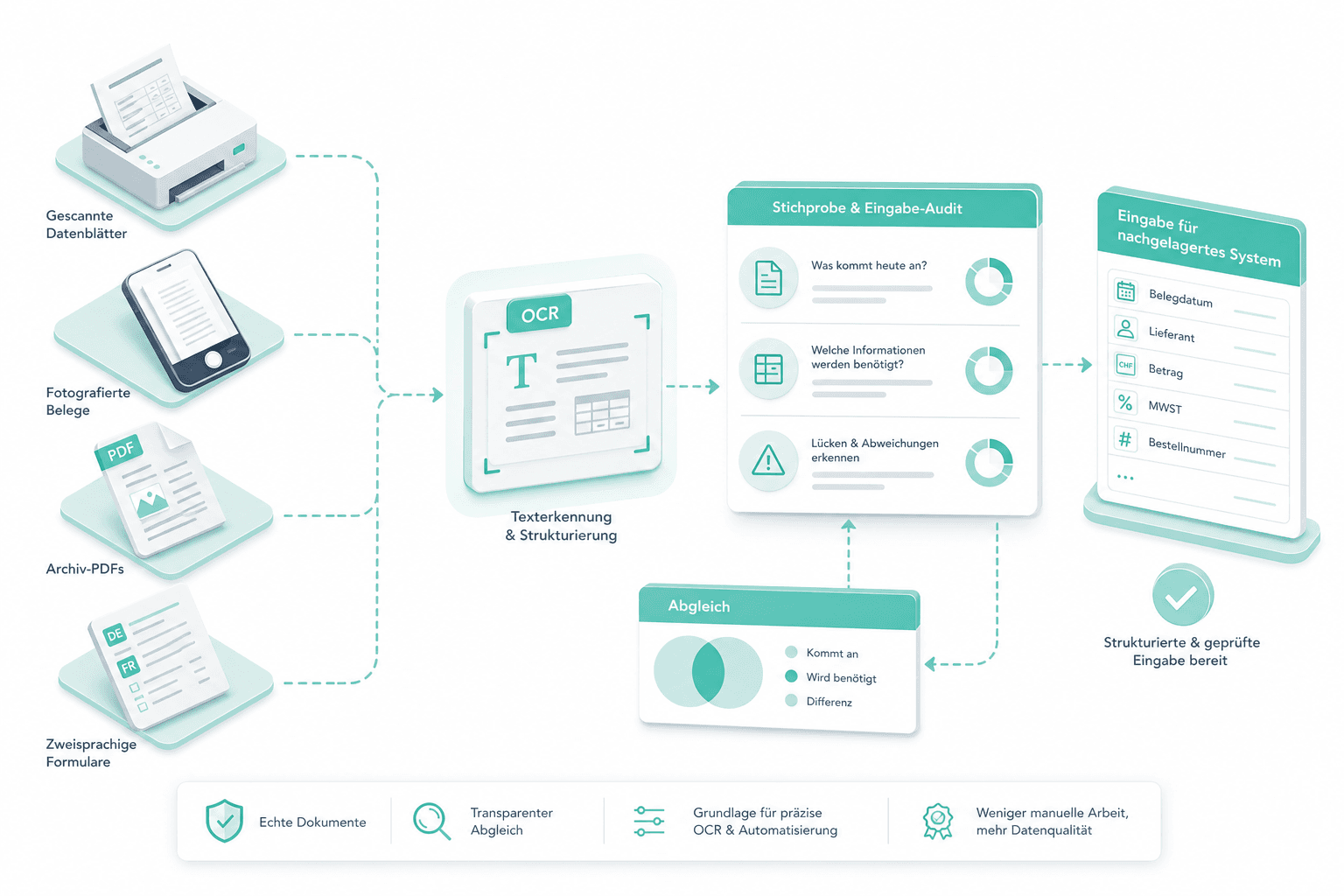
Zwei-Pass-OCR auf Ihren Daten
Wir fahren das Zwei-Pass-Muster mit Mistral OCR gegen die Stichprobe: zuerst Rohtext, dann strukturierte Zonen. Sie sehen genau, wie die Schicht mit Ihren schwierigsten Dokumenten umgeht — nicht mit einer kuratierten Demo.

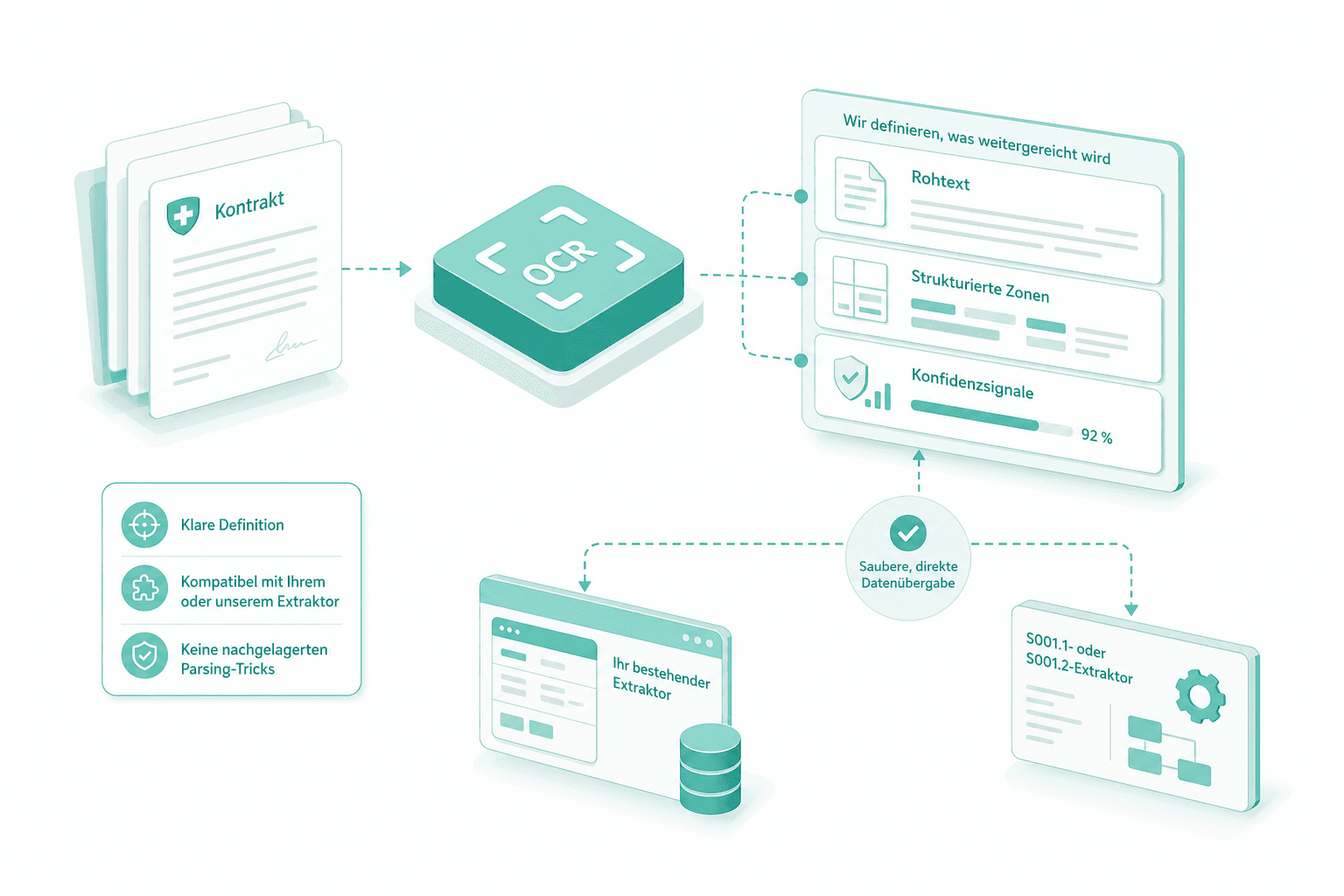
Kontrakt zum Extraktor festlegen
Wir definieren, was die OCR-Schicht weiterreicht: Rohtext, strukturierte Zonen, Konfidenzsignale. Damit Ihr bestehender Extraktor oder unser S001.1- bzw. S001.2-Extraktor die Daten ohne nachgelagerte Parsing-Tricks konsumiert.
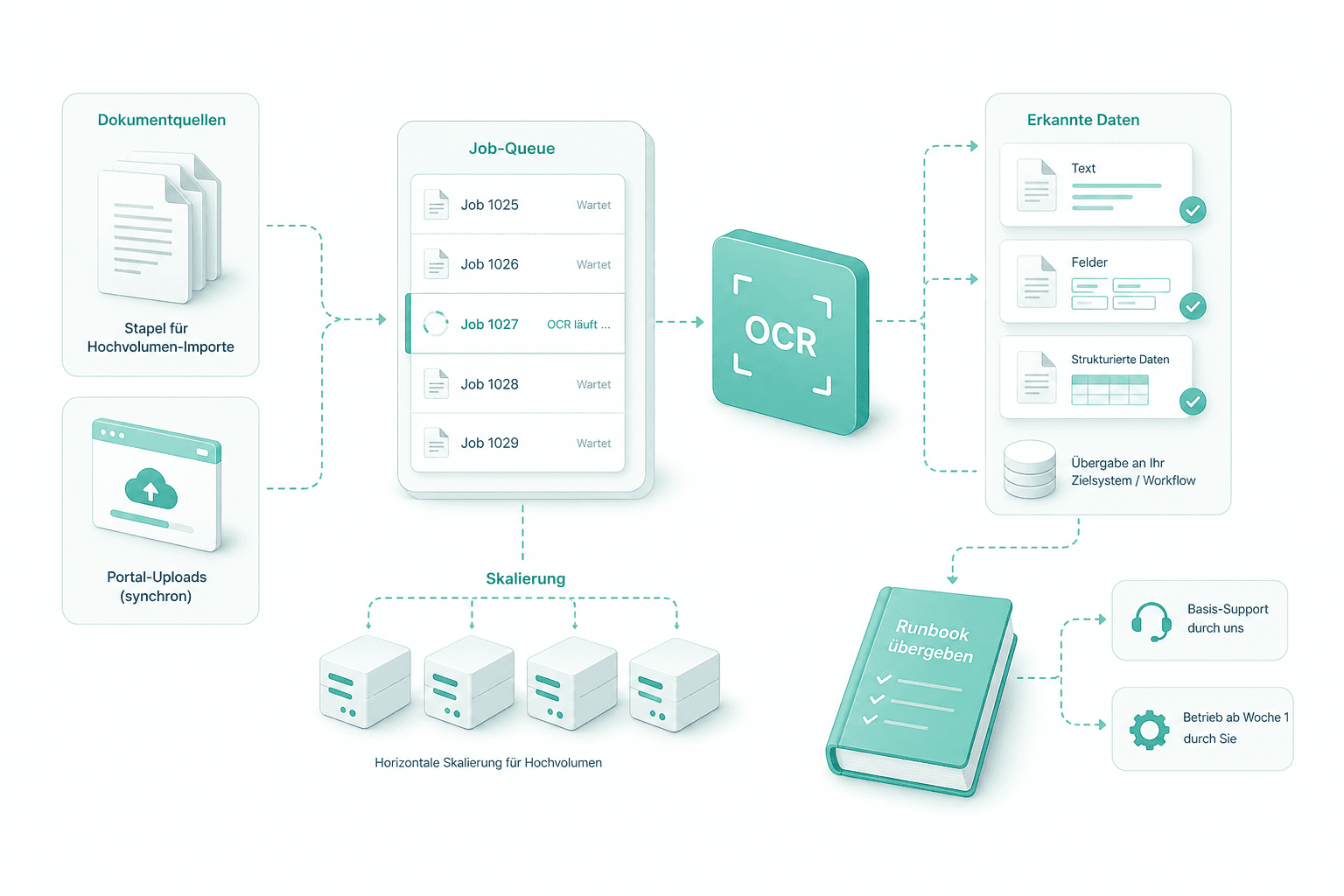
Queue, Skalierung und Uebergabe
Wir haengen den OCR-Schritt in Ihre Job-Queue ein — Stapel fuer Hochvolumen-Importe, synchron fuer Portal-Uploads — und uebergeben das Runbook. Die meisten Kunden behalten uns fuer Basis-Support; andere uebernehmen den Betrieb ab Woche eins selbst.
Wir beginnen mit Ihren echten Dokumenten: gescannte Datenblaetter, fotografierte Belege, Archiv-PDFs, zweisprachige Formulare. Wir gleichen ab, was heute im Posteingang ankommt und was Ihr nachgelagertes System tatsaechlich als Eingabe braucht.
Wir fahren das Zwei-Pass-Muster mit Mistral OCR gegen die Stichprobe: zuerst Rohtext, dann strukturierte Zonen. Sie sehen genau, wie die Schicht mit Ihren schwierigsten Dokumenten umgeht — nicht mit einer kuratierten Demo.
Wir definieren, was die OCR-Schicht weiterreicht: Rohtext, strukturierte Zonen, Konfidenzsignale. Damit Ihr bestehender Extraktor oder unser S001.1- bzw. S001.2-Extraktor die Daten ohne nachgelagerte Parsing-Tricks konsumiert.
Wir haengen den OCR-Schritt in Ihre Job-Queue ein — Stapel fuer Hochvolumen-Importe, synchron fuer Portal-Uploads — und uebergeben das Runbook. Die meisten Kunden behalten uns fuer Basis-Support; andere uebernehmen den Betrieb ab Woche eins selbst.
Ausgewählte Projekte
SWISS INSURANCE POC (NDA)
POC zur Automatisierung von Versicherungsdokumenten

Wie SAPIENTROQ einen schema-getriebenen POC zur Automatisierung von Versicherungsdokumenten fur ein Schweizer Backoffice lieferte: Mistral OCR plus OpenAI JSON-Modus, Schemata live aus Admin-Konfiguration generiert, KI-Anbieter tauschbar hinter einer Schnittstelle.
Fall ansehen
SANITAS TROESCH
PIM-Implementierung mit HITL-KI für Sanitas Troesch
Wie SAPIENTROQ eine PIM-Implementierung mit einer Multi-Agent-HITL-Pipeline lieferte, die 200k+ Lieferanten-SKUs aus PDFs, Excel und Jira in das Sanitas-Troesch-PIM mit prüffähiger Governance einspielt.
Fall ansehen

WEITA AG
Weita Lieferanten-Onboarding-Workflow: Digitalisierung im Grosshandel
Wie SAPIENTROQ fuer Weita AG einen Laravel- und Next.js-Workflow gebaut hat, der PDFs, E-Mails, Bilder und Tabellen in konforme PIM-Produkte ueberfuehrt — mit Mistral OCR, OpenAI im JSON-Modus und einer DB-gestuetzten Prompt-Registry.
Fall ansehen
Warum Zwei-Pass-OCR und kein einzelner Modellaufruf
Zwei Durchlaufe geben dem Extraktor eine Wahl
Ein einzelner OCR-Aufruf verschmilzt Worte und Layout zu einer Annahme. Wir fahren zwei Durchlaufe — zuerst Rohtext, dann strukturierte Zonen — und reichen beides an den nachgelagerten Extraktor weiter. Ist ein Feld im Rohstrom mehrdeutig, klaeren die strukturierten Zonen es; verliest sich der Layout-Pass an einer Tabelle, faengt der Rohtext den Wert auf. Die nachgelagerte LLM-Extraktion im OpenAI-JSON-Modus waehlt pro Feld die passende Eingabe, statt mit einem einzigen verrauschten Strom zu kaempfen.
OCR ist eine Schicht, kein Produkt
Cloud-OCR-Anbieter verkaufen den OCR-Aufruf als die Antwort. In Produktion ist er das nicht — er ist der Kontrakt zwischen Papier und Ihrem Extraktor. Weita, Sanitas Troesch und der Insurance-AI-POC behandeln OCR alle als gestaffelten Schritt: Mistral OCR laeuft als ein Job in einer Laravel-Queue, sein Output ist der Input fuer den naechsten Job, HITL kommt erst weiter unten ins Spiel. Wer OCR als Endprodukt verkauft, verdeckt, wo die eigentliche Genauigkeitsarbeit passiert.
Gegen echte Schweizer Dokumente gehaertet
Die OCR-Schicht ist auf die Dokumente abgestimmt, die im Schweizer Back-Office heute tatsaechlich ankommen: gescannte Lieferantendatenblaetter mit handschriftlichen Randnotizen, mehrspaltige deutsche Rechnungen, fotografierte Belege vom Handy, Archiv-PDFs mit Durchscheinen. Schweizerdeutsch wird auf OCR-Ebene als DE behandelt. Allgemeine Schweizerdeutsch-OCR-Versprechen sind Marketing — was zaehlt: die Schicht ist gegen die Dokumente von drei Schweizer Kunden produktiv getestet.
Haeufig gestellte Fragen
Schweizerdeutsch wird auf OCR-Ebene als DE behandelt. Die Schicht braucht kein separates Mundartmodell. In Produktion sind die ankommenden Dokumente meist in Standarddeutsch verfasst, mit vereinzelten Schweizerdeutsch-Anteilen — Lieferantennamen, Ortsbezeichnungen, handschriftliche Belege. Das Zwei-Pass-Muster behaelt Rohtext und strukturierte Zonen bei, sodass der nachgelagerte Extraktor Mehrdeutigkeiten ohne CH-spezifisches Modell aufloesen kann.
Nein, und wir tun nicht so. Digitale PDFs sind einfacher — der Text ist bereits codiert, der strukturierte Pass bestaetigt nur das Layout. Bei Scans, Fotos und gemischten PDFs zeigt das Zwei-Pass-Muster seinen Wert: Rohtext und strukturierte Zonen weichen oefter voneinander ab, und der nachgelagerte Extraktor entscheidet pro Feld. Eine einzelne Genauigkeitszahl veroeffentlichen wir nicht — sie waere ueber Eingabeformen hinweg nicht aussagekraeftig.
Der OCR-Pass liefert Rohtext plus strukturierte Zonen. Beides geht in den naechsten Queue-Schritt: Klassifikation, dann Feldextraktion im OpenAI-JSON-Modus. Der Kontrakt ist explizit — der Extraktor sieht Text und Zonen, entscheidet pro Feld, welche Eingabe er nutzt, und schreibt eine typisierte JSON-Nutzlast. Die OCR-Schicht trifft keine Geschaeftsentscheidungen, sie liefert die Eingaben dafuer.
Beides. Der OCR-Schritt sitzt in einer mehrstufigen Laravel-Job-Queue. Fuer naechtliche Stapellaeufe — Lieferantendatenblatt-Importe, Archiv-Ingest — skalieren Worker horizontal auf Docker. Bei Portal-Uploads, bei denen ein Nutzer wartet, laeuft derselbe Schritt mit hoeherer Prioritaet und liefert fuer typische Schweizer Dokumente binnen Sekunden zurueck. Gleicher Codepfad, andere Prioritaet.
Wir verkaufen OCR nicht pro Seite. Wir verrechnen die Leistung — Discovery, Integration, Betriebsunterstuetzung — und reichen die zugrundeliegende Mistral-OCR-Nutzung zu Selbstkosten weiter. Wer bereits einen Extraktor hat und nur die OCR-Schicht angebunden braucht, hat eine kurze Engagement. Bei vollstaendigen IDP-Rollouts faellt die OCR-Komponente unter das S001-Gesamtangebot und ist selten der groesste Posten.
Ja. Der OCR-Kontrakt — Rohtext plus strukturierte Zonen — ist stabil und anbieterneutral. Kunden, die mit unserem S001.1- oder S001.2-Extraktor starten, koennen das Extraktionsmodell hinter derselben OCR-Schicht spaeter tauschen, oder umgekehrt. Die zwei Durchlaufe sind so ausgelegt, dass sie die Wahl des nachgelagerten Modells ueberdauern.
Innerhalb der von Mistral OCR ausgewiesenen Handschriftgrenzen ja — handschriftliche Randnotizen auf Lieferantendatenblaettern, unterschriebene Lieferscheine, handschriftliche Belege. Wir stellen Handschrifterkennung nicht als Headline-Feature heraus. In Produktion gehen handschriftliche Felder fast immer in eine nachgelagerte HITL-Pruefung; der OCR-Pass liefert dem Pruefer einen sauberen Vorschlag zum Bestaetigen oder Korrigieren.
Standard-Deployment ist EU-Hosting. Fuer Workloads mit Schweizer Datenresidenz laeuft der OCR-Schritt auf Schweizer Servern oder on-prem beim Kunden. Wo kein oeffentlicher Modell-Endpunkt erreichbar sein darf, binden wir den Apertus-Pfad fuer den Extraktor an und behalten Mistral OCR auf einem Schweizer Gateway. Jeder OCR-Pass wird mit Modell-ID und Version protokolliert.
Über SAPIENTROQ![]()
Sind Sie an einer Lösung interessiert?
Wir freuen uns, Ihnen die Möglichkeiten unverbindlich aufzuzeigen.

Roland Kurmann
CEO, SAPIENTROQ