Apertus Fine-tuning Schweiz
Was ein Apertus-Fine-tune liefert
LoRA-Adapter für die 8B-Klasse
LoRA passt zur 8B-Variante von Apertus, wenn schnelle Iteration und kleine Adapterdateien gefragt sind — kein voller Gewichtssatz. Adapter werden je Anwendungsfall versioniert — einer für den Back-Office-Berater, einer für die Vertragsprüfung — und beim Serving auf derselben Basis getauscht. So bleibt die Kostenkurve flach.
QLoRA für die 70B-Variante
QLoRA quantisiert das Basismodell im Speicher, sodass ein 70B-Apertus-Fine-tune mit weniger GPU-Footprint auskommt als ein Voll-Präzisionslauf. Für Schweizer Häuser, die ihr erstes H100- oder A100-Cluster dimensionieren, ist QLoRA die Voreinstellung — die 70B-Klasse wird im bestehenden Budget trainierbar.
Voll-Fine-tunes der 70B-Klasse
Wenn LoRA nicht ausreicht — die Fachsprache weicht stark von der Basis ab oder Sie wollen ein dauerhaft eigenes Modell — fahren wir ein Voll-Fine-tune der 70B-Klasse. Die Gewichte werden Kunden-Asset, gehostet auf demselben On-Prem-Stack wie das Basismodell, mit längerer Trainingszeit gegen ein dauerhaft eigenes Modell.
Schweizer Sprachterminologie
Apertus deckt Schweizerdeutsch, Französisch, Italienisch und Romanisch im Basistraining ab. Das Fine-tuning erweitert das um Ihren Hausstil: Banking-Sprache, Versicherungswortlaut, Treuhand-Terminologie, kantonale Verwaltungssprache. Paare werden pro Locale kuratiert; Schweizerdeutsch bleibt vom Hochdeutschen klar getrennt.
Evaluations-Set und Regression
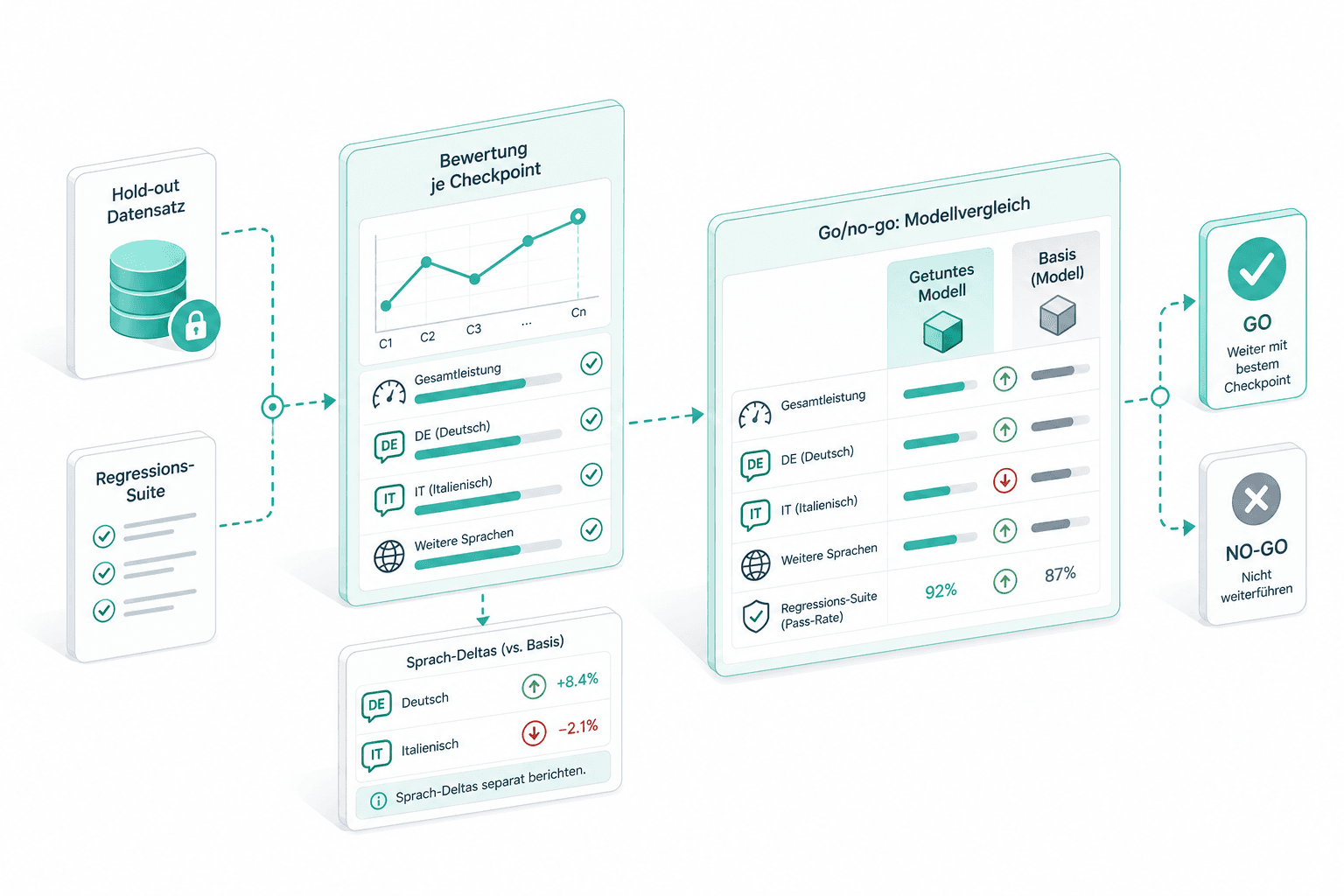
Das Evaluations-Set entsteht vor dem Training, nicht danach. Fachverantwortliche stimmen das Hold-out aus echten Aufgaben ab, eine Regressions-Suite läuft bei jedem Checkpoint mit, und Qualität wird über den Lauf verfolgt — nicht von der Verlustkurve abgelesen. Go/no-go: getuntes Modell gegen Basis auf demselben Hold-out.
Hosting-Übergabe an On-Prem
Getunte Gewichte landen auf demselben Schweiz-residenten oder On-Prem-Cluster, das bereits für den Apertus-Rollout gewählt wurde. Das Fine-tune erbt den vorhandenen Serving-Stack — vLLM oder TGI, Hugging Face Transformers — und die Audit-Spur, die Sie akzeptieren. Kein zweiter Mandant, keine neue Beschaffung.
Unser Fine-tune-Weg
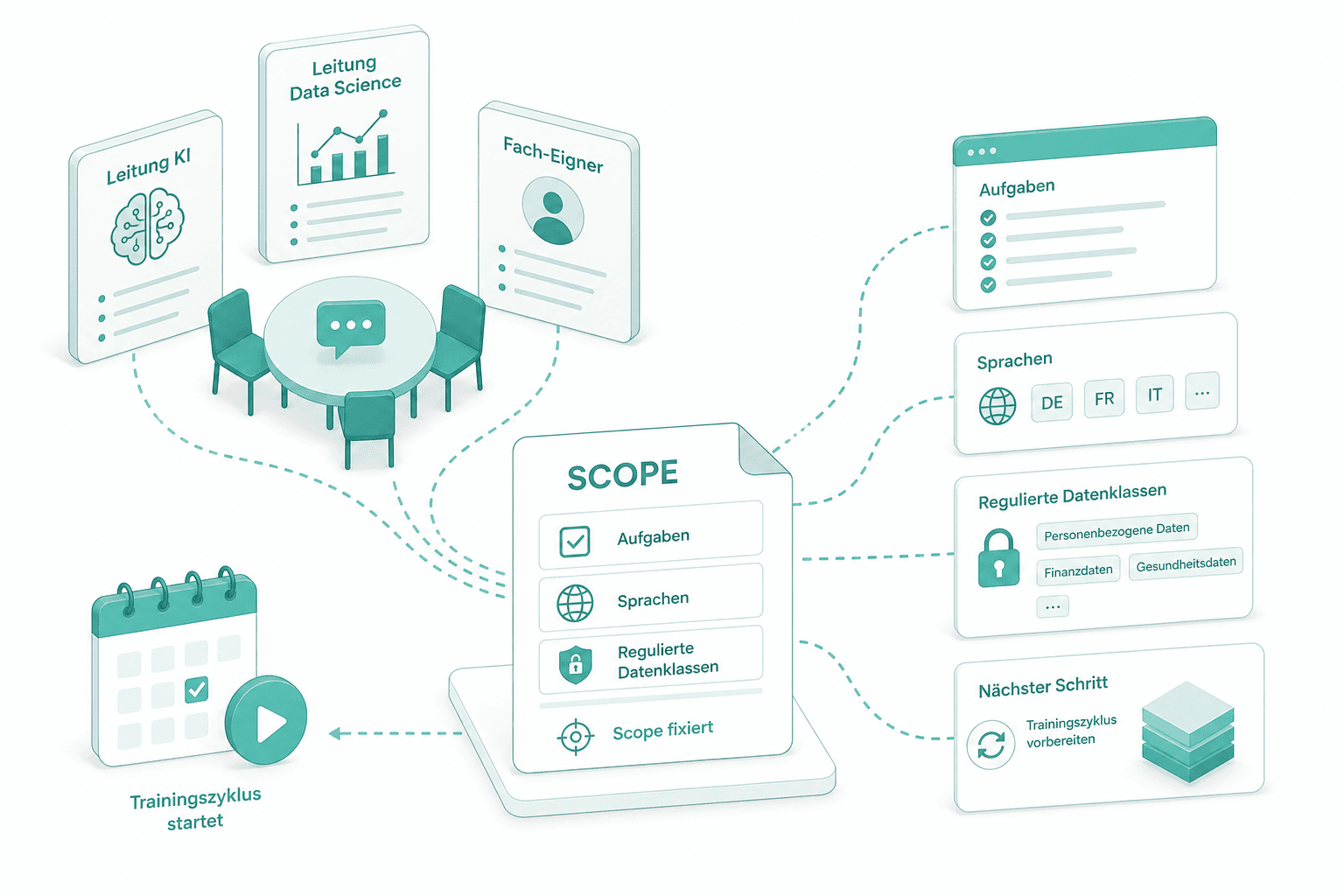
Scoping mit Eignern
Wir setzen uns mit den Leitenden KI, Data Science und den Fach-Eignern zusammen, die das Modell nutzen. Das Scope fixiert Aufgaben, Sprachen und regulierte Datenklassen, bevor ein Trainingszyklus startet.
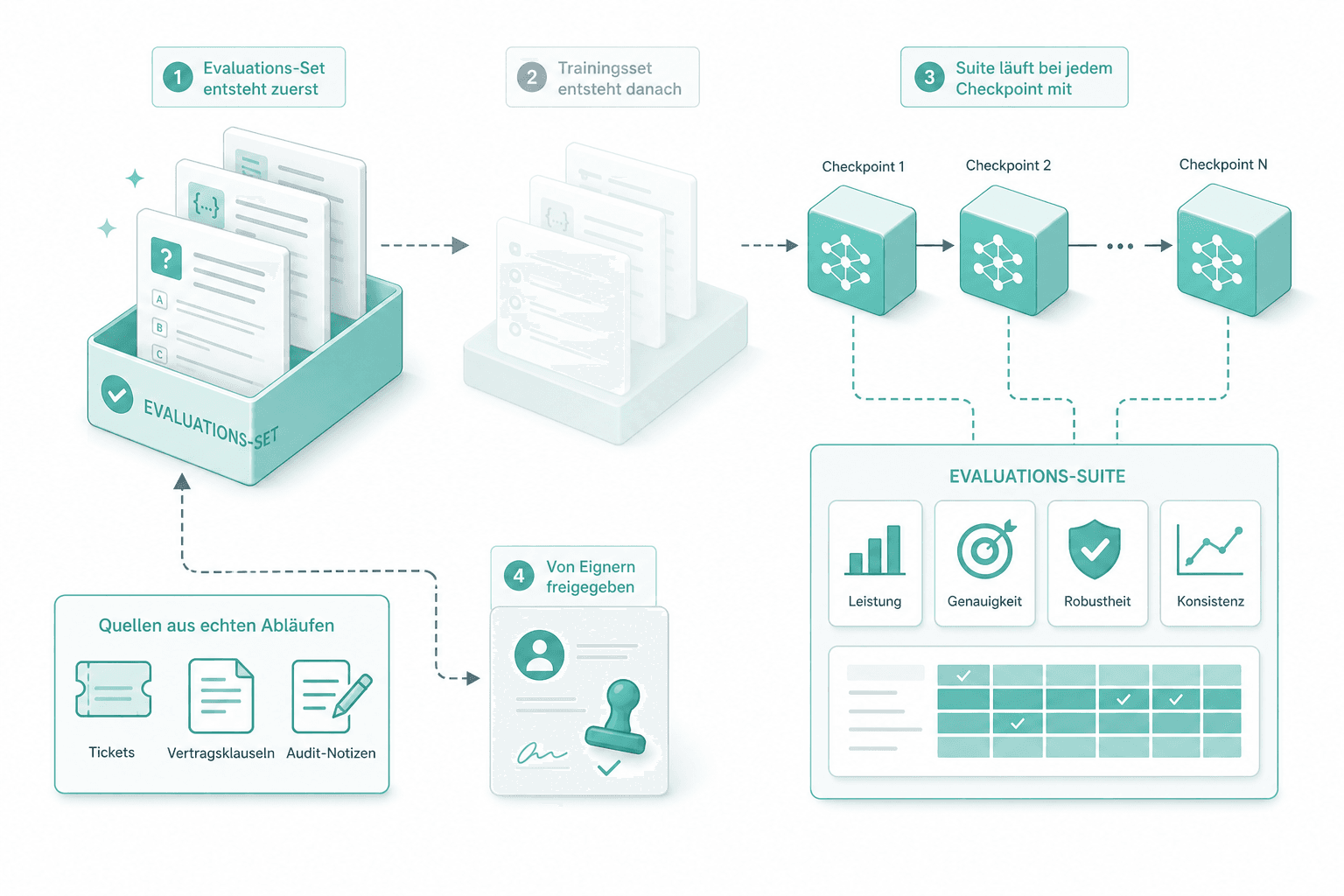
Evaluations-Set-Design
Das Evaluations-Set entsteht vor dem Trainingsset. Hold-out-Aufgaben kommen aus echten Abläufen — Tickets, Vertragsklauseln, Audit-Notizen — und werden von Eignern freigegeben. Die Suite läuft bei jedem Checkpoint mit.
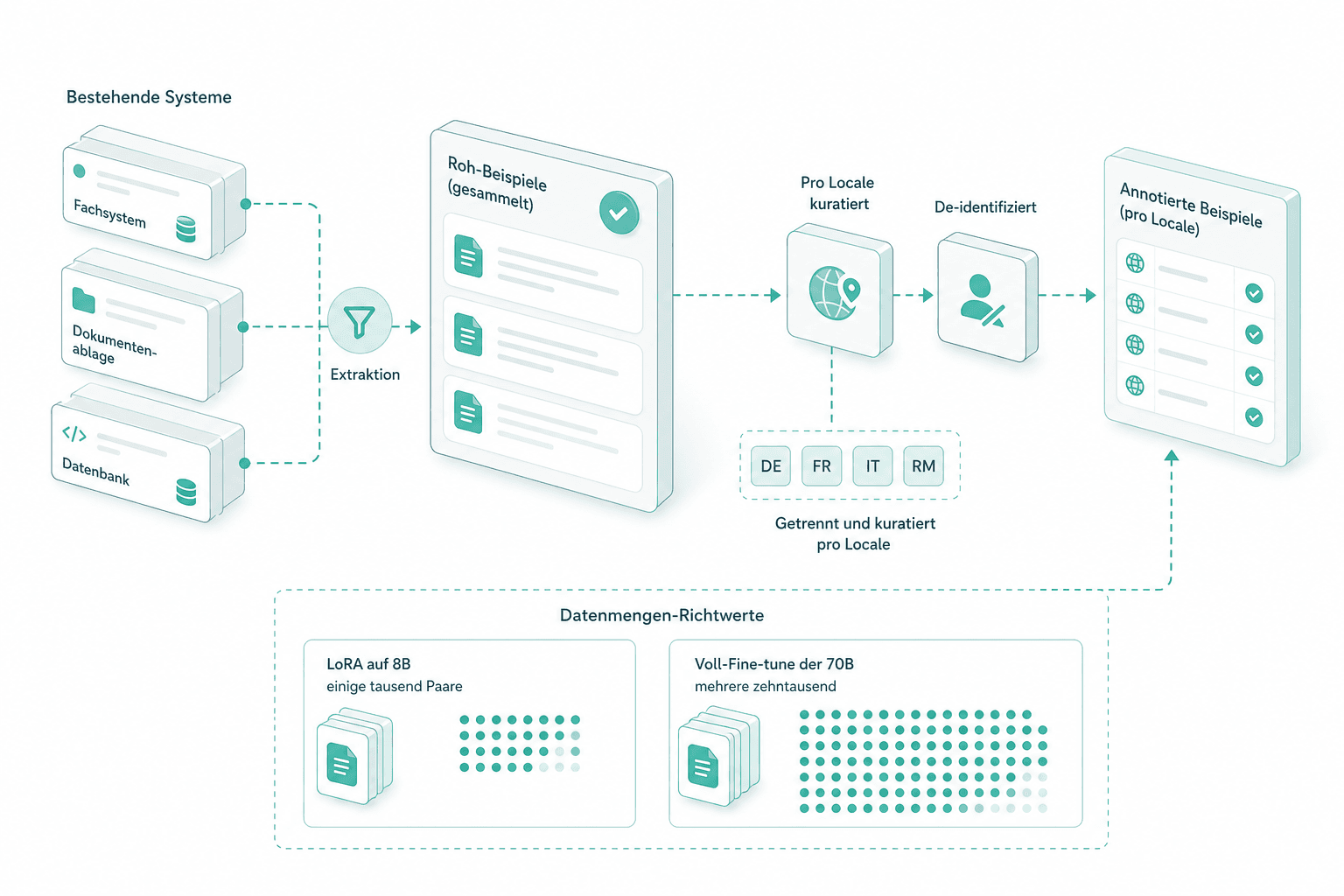
Datensammlung
Annotierte Beispiele werden aus bestehenden Systemen gezogen, pro Locale kuratiert und de-identifiziert. Faustregel: LoRA auf 8B will einige tausend Paare; ein Voll-Fine-tune der 70B mehrere zehntausend.
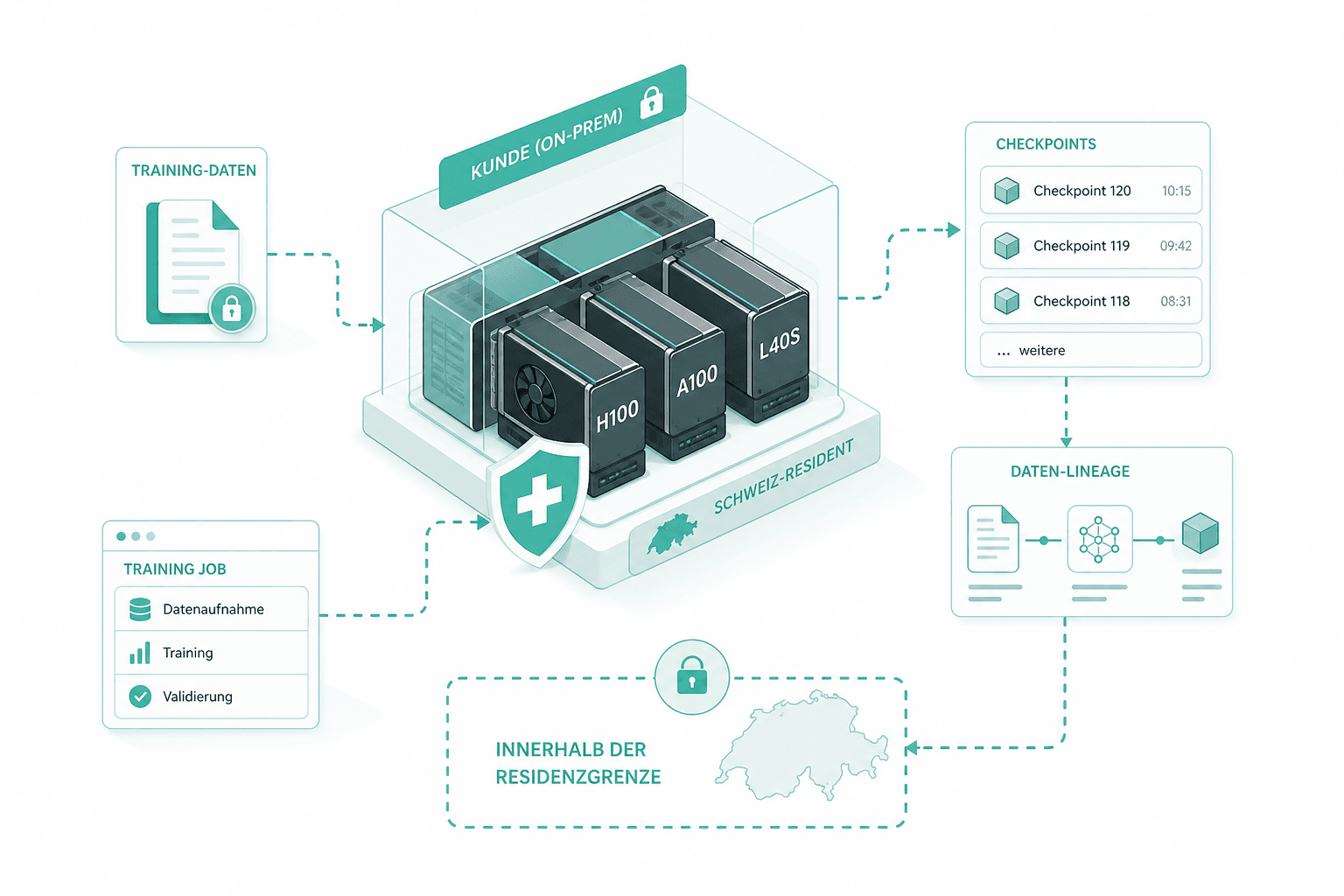
Training auf CH-GPUs
Das Training läuft auf dem GPU-Footprint, den der Kunde bereits beschafft hat — H100, A100 oder L40S, On-Prem oder Schweiz-resident. Wir loggen jeden Checkpoint, halten Daten-Lineage fest und bleiben innerhalb der Residenzgrenze.
Auswertung und Go/no-go
Jeder Checkpoint wird gegen das Hold-out und die Regressions-Suite bewertet. Sprach-Deltas werden separat berichtet, damit eine DE-Verbesserung keinen IT-Rückschritt verbirgt. Go/no-go vergleicht getuntes Modell und Basis.
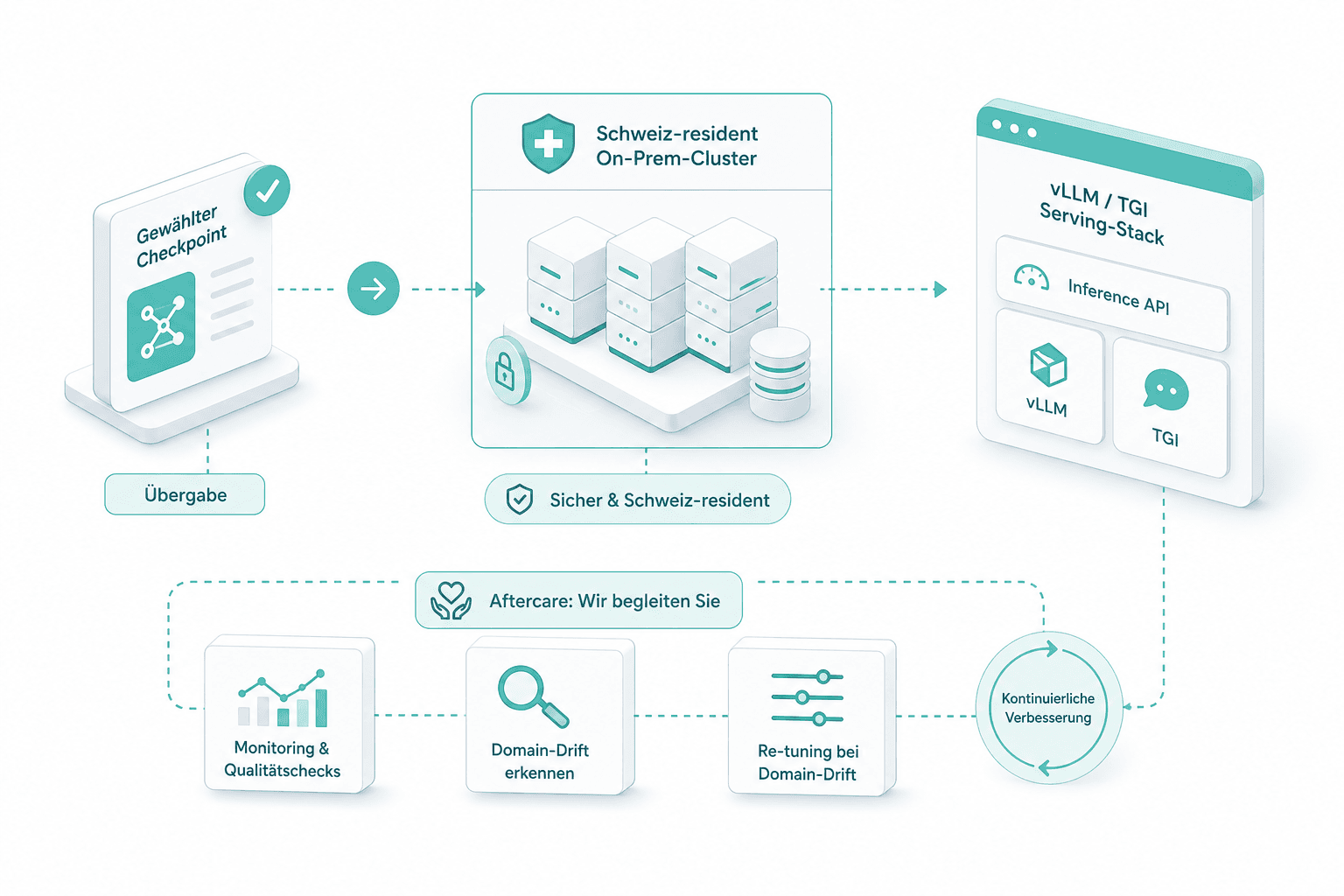
Übergabe und Aftercare
Der gewählte Checkpoint wird auf das bestehende On-Prem- oder Schweiz-residente Apertus-Cluster ausgespielt, hinter demselben vLLM- oder TGI-Serving-Stack. Wir begleiten die ersten Wochen und re-tunen bei Domain-Drift.
Wir setzen uns mit den Leitenden KI, Data Science und den Fach-Eignern zusammen, die das Modell nutzen. Das Scope fixiert Aufgaben, Sprachen und regulierte Datenklassen, bevor ein Trainingszyklus startet.
Das Evaluations-Set entsteht vor dem Trainingsset. Hold-out-Aufgaben kommen aus echten Abläufen — Tickets, Vertragsklauseln, Audit-Notizen — und werden von Eignern freigegeben. Die Suite läuft bei jedem Checkpoint mit.
Annotierte Beispiele werden aus bestehenden Systemen gezogen, pro Locale kuratiert und de-identifiziert. Faustregel: LoRA auf 8B will einige tausend Paare; ein Voll-Fine-tune der 70B mehrere zehntausend.
Das Training läuft auf dem GPU-Footprint, den der Kunde bereits beschafft hat — H100, A100 oder L40S, On-Prem oder Schweiz-resident. Wir loggen jeden Checkpoint, halten Daten-Lineage fest und bleiben innerhalb der Residenzgrenze.
Jeder Checkpoint wird gegen das Hold-out und die Regressions-Suite bewertet. Sprach-Deltas werden separat berichtet, damit eine DE-Verbesserung keinen IT-Rückschritt verbirgt. Go/no-go vergleicht getuntes Modell und Basis.
Der gewählte Checkpoint wird auf das bestehende On-Prem- oder Schweiz-residente Apertus-Cluster ausgespielt, hinter demselben vLLM- oder TGI-Serving-Stack. Wir begleiten die ersten Wochen und re-tunen bei Domain-Drift.
Ausgewählte Projekte
BICOSY / BICO.CH
KI-Einkaufsassistent fuer bico.ch auf WooCommerce

Wie SAPIENTROQ BICOSY entwickelte: ein KI-Einkaufsassistent fuer den Schweizer Matratzenhaendler bico.ch — NestJS-Backend mit pgvector-RAG, deklarierte typisierte Tools und ein WordPress-Plugin, das WooCommerce-Events live in die Konversation streamt.
Fall ansehen
Warum mit uns fine-tunen
Fine-tune vs. reines RAG
RAG passt, wenn sich das Wissen wöchentlich ändert und das Modell es nur lesen muss. Fine-tuning passt, wenn Terminologie, Ton und Urteilsmuster Teil der Antwort sind — Schweizer Banking-Sprache, Versicherungsformulierungen, Treuhand-Wortlaut. Meist kombinieren wir beides, mit Retrieval auf einem getunten Basismodell. Den Trade-off besprechen wir auf der Eltern-Seite Apertus Swiss LLM; für trainings-freie Setups führen wir Kunden zu Apertus RAG-Integration.
Schweizer Sprachterminologie im Training
Apertus ist das einzige Frontier-Open-Modell, das mit voller Schweizer Sprachabdeckung trainiert wurde — DE, FR, IT und Romanisch, mit Schweizerdeutsch klar vom Hochdeutschen abgegrenzt. Das Fine-tuning erweitert diese Abdeckung um Ihren Hausstil: kantonale Verwaltungssprache, Versicherungsformulierungen, Audit-Wortlaut. Trainingspaare werden pro Locale kuratiert, und das Evaluations-Set prüft jede Sprache separat.
Audit-Spur und Regressions-Suite
Fine-tuning auf die richtige Art ist eine stille Investition: ein Hold-out-Evaluations-Set, eine Regressions-Suite, die bei jedem Checkpoint neu läuft, und ein Modell, das tatsächlich die Sprache Ihres Back-Office spricht — nicht die eines öffentlichen Benchmarks. Die Audit-Spur deckt Daten-Lineage, Prompt-Versionen und Sprach-Deltas ab — genau das, was ein FINMA-, MDR- oder kantonal gebundener Eigner gegenüber Aufsicht braucht.
Vom POC zur Produktion auf einem Stack
Die meisten Fine-tunes starten nach dem bezahlten Apertus-Evaluations-POC, der zeigt, dass das Basismodell nah genug ist, um Training zu rechtfertigen. Die getunten Gewichte landen dann auf dem bestehenden On-Prem-Apertus-Deployment und erben den Serving-Stack. Wer noch im Scoping ist, kommt über KI-Beratung zu uns.
Häufig gestellte Fragen
RAG passt, wenn sich das Wissen wöchentlich ändert und das Modell es nur lesen muss. Ein Fine-tuning passt, wenn Terminologie, Ton oder Urteilsmuster Teil der Antwort sind — Schweizer Banking-Sprache, Versicherungsformulierungen, Treuhand-Wortlaut. Meist kombinieren wir beides.
LoRA eignet sich für die 8B-Klasse, wenn schnelle Iteration und kleine Adapterdateien gefragt sind. QLoRA reduziert den GPU-Speicherbedarf weiter und ist die Voreinstellung für die 70B-Variante auf einem Knoten. Voll-Fine-tunes wählen wir bei dauerhaft eigenen Gewichten.
Als Faustregel bewegt ein LoRA-Adapter auf der 8B-Klasse mit einigen tausend hochwertigen Beispielen den Hebel; ein Voll-Fine-tune der 70B-Klasse will typischerweise mehrere zehntausend. Die genaue Zahl hängt von der Aufgabenvielfalt ab und wird im Discovery festgelegt.
Apertus deckt die vier Landessprachen bereits ab; das Fine-tuning erweitert die Abdeckung. Trainingspaare werden pro Locale kuratiert, Schweizerdeutsch bleibt vom Hochdeutschen getrennt, und das Evaluations-Set prüft jede Sprache separat, damit Regressionen sichtbar bleiben.
Vor dem Training stimmen wir das Evaluations-Set mit den Fachverantwortlichen ab — ein Hold-out aus echten Aufgaben, kein öffentlicher Benchmark. Eine Regressionssuite läuft bei jedem Checkpoint mit; Go/no-go ist das getunte Modell gegen dasselbe Hold-out auf der Basis.
Auf demselben Cluster wie das Basismodell. In den meisten Engagements werden die Gewichte auf den On-Prem- oder Schweiz-residenten Knoten ausgespielt, der im Apertus-Rollout bereits gewählt wurde — Serving via vLLM oder TGI, dieselbe Audit-Spur.
Über SAPIENTROQ![]()
Sind Sie an einer Lösung interessiert?
Wir freuen uns, Ihnen die Möglichkeiten unverbindlich aufzuzeigen.

Roland Kurmann
CEO, SAPIENTROQ