Apertus Schweizer LLM — Implementierung und Integration
LoRA, QLoRA und Voll-Fine-tunes von Apertus auf Schweizer Banking-, Versicherungs-, Treuhand- und Gesundheitsterminologie. Wir entwerfen das Evaluations-Set zuerst und liefern die Gewichte ins eigene Schweizer Cluster.
Ein souveräner Apertus-Dokumenten-Copilot für Schweizer Unternehmen: Chat mit Richtlinien, Verträgen und internem Wissen über eine Next.js-Anwendung, die jede Antwort zum Quellabsatz belegt und vollständig in der Schweiz bleibt.
Bringen Sie Ihre OpenAI- oder Anthropic-Integration auf Apertus, das Schweizer Open-Weights-LLM, ohne Qualitätsverlust. Audit, Evaluations-Neuaufbau, Prompt-Umschrift, Benchmark und stufenweiser Wechsel — Schweizer Team.
Eine bezahlte 2-4-wöchige Apertus-Evaluierung und POC, die das Schweizer Open-Source-Modell an Ihrer realen Arbeitslast gegen Ihr heutiges Modell vergleicht und mit einer klaren Go/No-Go-Empfehlung als Zahl endet.
Betreiben Sie Apertus, das Schweizer Open-Source-LLM, im eigenen Rechenzentrum oder in einer souveränen Swiss-Cloud. Wir dimensionieren GPUs zum Prompt-Mix, installieren vLLM oder TGI und bleiben bis zum Produktiv-Peak im Einsatz.
Produktive Retrieval-Augmented-Generation gegen Ihren SharePoint-, Confluence-, Fileshare- oder DMS-Bestand, mit Apertus als Generator. PostgreSQL mit pgvector, nutzerspezifischer Filter und frischer Index.
Apertus läuft in der Schweiz auf Exoscale, Infomaniak oder AWS Zürich, mit schriftlichem Datenresidenz-Vertrag, der Disks, Backups und Personen benennt. Gebaut für FINMA-, Kantons- und Gesundheitskunden ohne eigenes Rechenzentrum.
Unsere Apertus-Tracks
Sieben benannte Tracks auf einer souveränen LLM-Praxis — wählen Sie den Apertus-Workload, den Sie heute haben, statt einer generischen Modell-Evaluations-Folie. Einstieg über <a href="/de/services/ai-consulting">AI-Beratung</a>.
Apertus On-Prem-Implementierung
Apertus 8B oder 70B auf Kunden-GPUs — H100, A100 oder L40S — mit vLLM oder TGI. Souverän per Default, keine US-Lieferanten-Verarbeitung.
Apertus Fine-Tuning
Fachgebiets-Fine-tuning von Apertus auf Ihrem Schweizer Korpus — Banking, Versicherung, Treuhand, Gesundheit oder technische Dokumentation. Typisierte Evaluation, Audit-Trail.
Apertus RAG-Integration
Retrieval-Augmented Generation mit Apertus auf PostgreSQL plus pgvector. Quellenzitate, Chunk-Audit, rollenbasiertes Retrieval, kein Dokument-Leak über Tenants.
Dokumenten-Q&A-Copilot
Apertus-Q&A-Copilot über Verträge, Richtlinien, regulatorische Akten oder Lieferanten-Datenblätter. Antworten mit Quellen aus Ihrem Korpus und HITL-Fallback.
Migration von OpenAI oder Anthropic
Bestehenden GPT- oder Claude-Workload auf Apertus umziehen, ohne die Anwendung neu zu bauen. Prompt-Audit, Regression-Harness, Fallback-Gates, Parallelbetrieb vor Cutover.
Evaluation und bezahlter POC
Zwei- bis vierwöchiger bezahlter Apertus-POC gegen Ihr echtes Task-Set. Typisierte Evaluation, Seite-an-Seite mit dem aktuellen Modell, Go-/No-Go-Gate vor jedem Bau.
Schweizer Datenresidenz-Hosting
Apertus auf Exoscale, Infomaniak, AWS Zürich oder voll On-Prem — gewählt nach Datenklasse, FINMA- oder Kantonsregime und Throughput-Ziel.
Wie wir ein Apertus-Engagement liefern
Vom souveränen LLM-Vorhaben bis zur laufenden Apertus-Implementierung in fünf Schritten. Die Position, die wir im Scope halten: Swiss buyers don't reject OpenAI for taste. They reject it because the regulator, the cantonal data officer or the board's IT subcommittee will not sign off on supplier-side US processing. Apertus is the first open model good enough that rejecting OpenAI doesn't cost you the workload.
Ausgewählte Apertus-Engagements
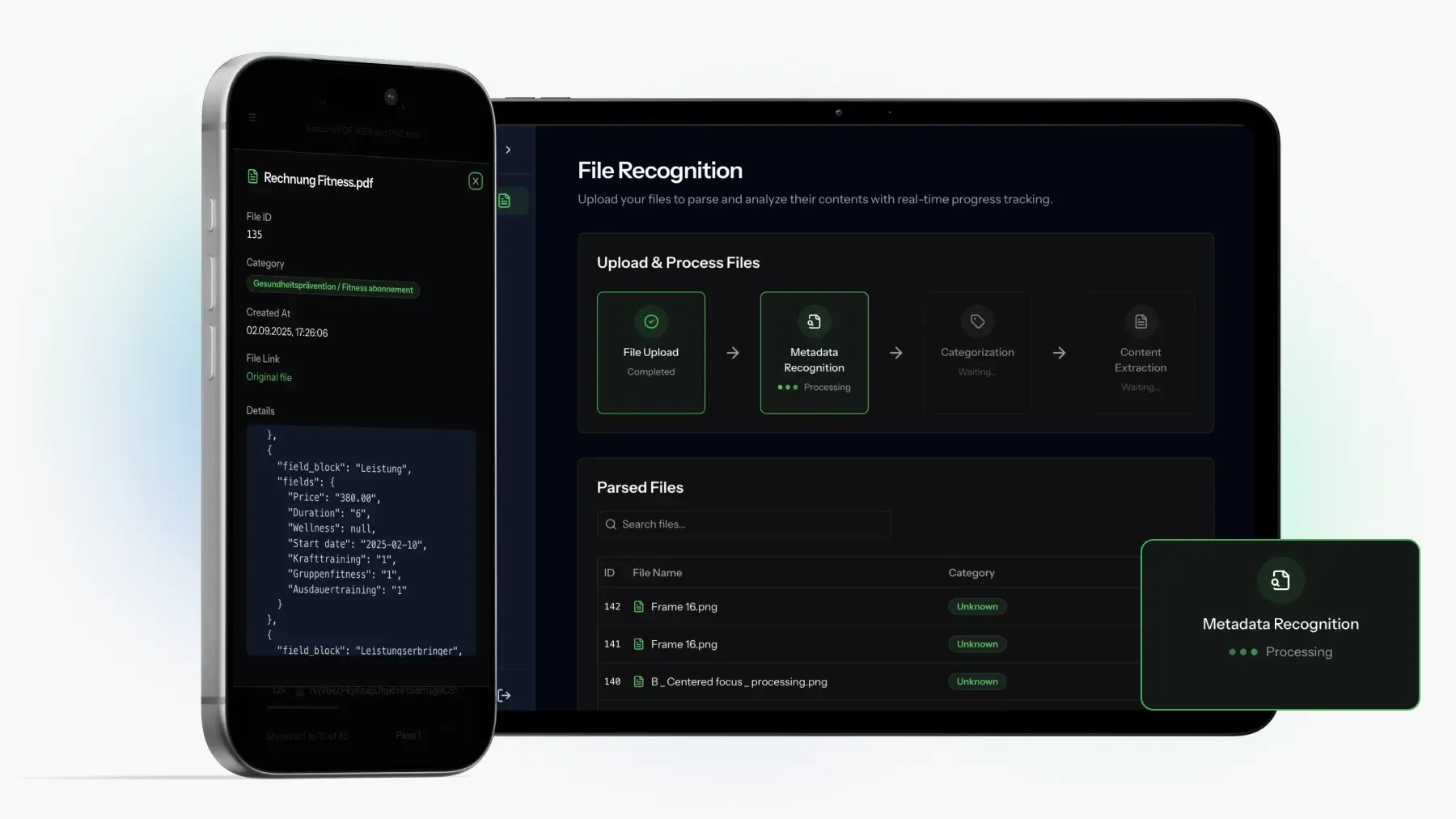
SWISS INSURANCE POC (NDA)
POC zur Automatisierung von VersicherungsdokumentenWie SAPIENTROQ einen schema-getriebenen POC zur Automatisierung von Versicherungsdokumenten fur ein Schweizer Backoffice lieferte: Mistral OCR plus OpenAI JSON-Modus, Schemata live aus Admin-Konfiguration generiert, KI-Anbieter tauschbar hinter einer Schnittstelle.
Technologie-Stack
Apertus 8B oder 70B auf vLLM oder TGI als Serving-Layer, Hugging Face Transformers für Tooling, llama.cpp für Edge-Fälle. Anwendungs-Rückgrat auf Laravel und Next.js, PostgreSQL mit pgvector für RAG, Redis und BullMQ für Queueing, Mastra bei Multi-Agenten-Orchestrierung. Schweizer Hosting auf Exoscale, Infomaniak, AWS Zürich oder On-Prem.
Was Kunden sagen
Häufig gestellte Fragen
Apertus ist die offene LLM-Familie der Swiss AI Initiative (EPFL, ETH Zürich, CSCS Lugano), Ende 2025 unter Apache 2.0 veröffentlicht. Verfügbar in 8B- und 70B-Varianten mit Abdeckung von Schweizerdeutsch, Französisch, Italienisch und Rumantsch in frontier-Qualität.
Wir deployen Apertus auf Standard-GPU — H100, A100 oder L40S — mit vLLM oder TGI als Serving-Layer. Hosting läuft auf Exoscale, Infomaniak, AWS Zürich oder voll On-Prem im Kundenestate. Hybride Modelle sind üblich: RAG in CH-Cloud, Inferenz auf eigenen GPUs.
Apertus gewinnt, wenn US-Lieferanten-Verarbeitung vom Regulator, kantonalen Datenbeauftragten oder Board blockiert ist. Es gewinnt auch bei Schweizerdeutsch. GPT-4o und Claude führen weiter bei englischem Reasoning. Unser bezahlter POC misst die Lücke vorher.
Die Form ist Discovery, POC, Produktion. Ein zwei- bis vierwöchiges Discovery scopt Workload, Datenresidenz und Integrationsfläche. Ein bezahlter zwei- bis vierwöchiger POC läuft gegen Ihr echtes Task-Set mit Go-/No-Go-Gate. Produktion folgt nur bei bestandenen Benchmarks.
Schweizer Hosting in unserer Praxis: Exoscale (CH), Infomaniak (CH) und AWS Zürich für regionale Cloud, plus On-Prem im Kundenestate für FINMA-, kantonale oder Gesundheits-Workloads. Die Wahl hängt von Datenklasse, Regulatorregime und Throughput-Ziel ab.
Wir hosten Apertus im selben Stack wie unsere Doc-AI- und PIM-Tracks: Laravel und Next.js als Anwendungs-Rückgrat, PostgreSQL mit pgvector für RAG-Retrieval, Redis und BullMQ für Queueing, Mastra-Orchestrierung bei Multi-Agenten-Flows. Anbindung über typisierte APIs.
Über SAPIENTROQ![]()
Sind Sie an einer Lösung interessiert?
Wir freuen uns, Ihnen die Möglichkeiten unverbindlich aufzuzeigen.

Roland Kurmann
CEO, SAPIENTROQ