MDR / IVDR Dokumenten-KI
Wo die Engine Ihr regulatorisches Team unterstuetzt
Klassifikation der technischen Dokumentation
Annex-II-Dokumente kommen aus Entwicklung, Produktion, Lieferanten und Post-Market in unterschiedlichen Formaten herein. Die Engine ordnet jedes Dokument in Ihre Annex-II-Struktur und der zustaendigen Pruefrolle zu und zeigt Luecken im Binder gegen Ihr Template auf. Die Bewertung der Luecke trifft RA bzw. QA.
Post-Market Surveillance Ingestion
Reklamationen, Vigilanzmeldungen, Service-Notizen und Trenddaten fliessen ueber eine Pipeline in das PMS-Berichtstemplate. Die Engine extrahiert die typisierten Felder, die Ihr PMS-Bericht erwartet, taggt Evidenz nach Geraeteklasse und leitet alles unterhalb der Konfidenzschwelle an den Pruefer. Die narrative Interpretation bleibt beim RA-Autor.
Pflege der klinischen Bewertung
Literatur, PMCF-Daten und Equivalent-Device-Evidenz landen mit nachvollziehbarer Herkunft in der klinischen Bewertung. Die Engine taggt jede Evidenz, verknuepft sie mit dem unterstuetzten Claim und markiert Luecken. Der klinische Pruefer zeichnet jede Verknuepfung ab.
Pflege von Design History File und Technical File
DHF und TF wachsen ueber Revisionen. Die Engine indexiert sie nach Anforderung, Designausgabe, Verifikation und Validierung und haelt die Querverweise als abfragbare Karte vor. Bei Re-Ingestion einer revidierten Datei werden die abhaengigen Artefakte zur Nachpruefung markiert.
Change-Control-Spur auf Annex-II-Dateien
Wird ein revidiertes Annex-II-Dokument neu eingelesen, vergleicht die Engine es mit der Vorversion, zeigt die geaenderten Abschnitte und markiert jede verknuepfte nachgelagerte Datei zur Nachpruefung. Die Aenderungsspur wird mit Modell-ID, Prompt-Register-Version und Pruefer protokolliert — die Evidenz ist auditfest.
Automatisierte Traceability-Matrix
Anforderungen, Designausgaben, Verifikations- und Validierungsartefakte werden im Binder verknuepft. Die Engine pflegt die Traceability-Matrix ueber Revisionen hinweg; QA prueft und gibt sie an Release-Meilensteinen frei. Die Matrix wird in dem Format ausgegeben, das Ihre Benannte Stelle erwartet.
Unser Vorgehen
Inventar gemeinsam mit Ihrem RA-Lead
Ihr RA-Lead fuehrt uns durch die Binder-Struktur, die Annex-II- bzw. IVDR-Annex-II-Karte, die nachgelagerten Pruefrollen und die Zielsysteme. Wir leiten das typisierte Schema ab; Ihr Team bestaetigt, dass es genau dem Binder entspricht, den Sie im Audit vertreten.
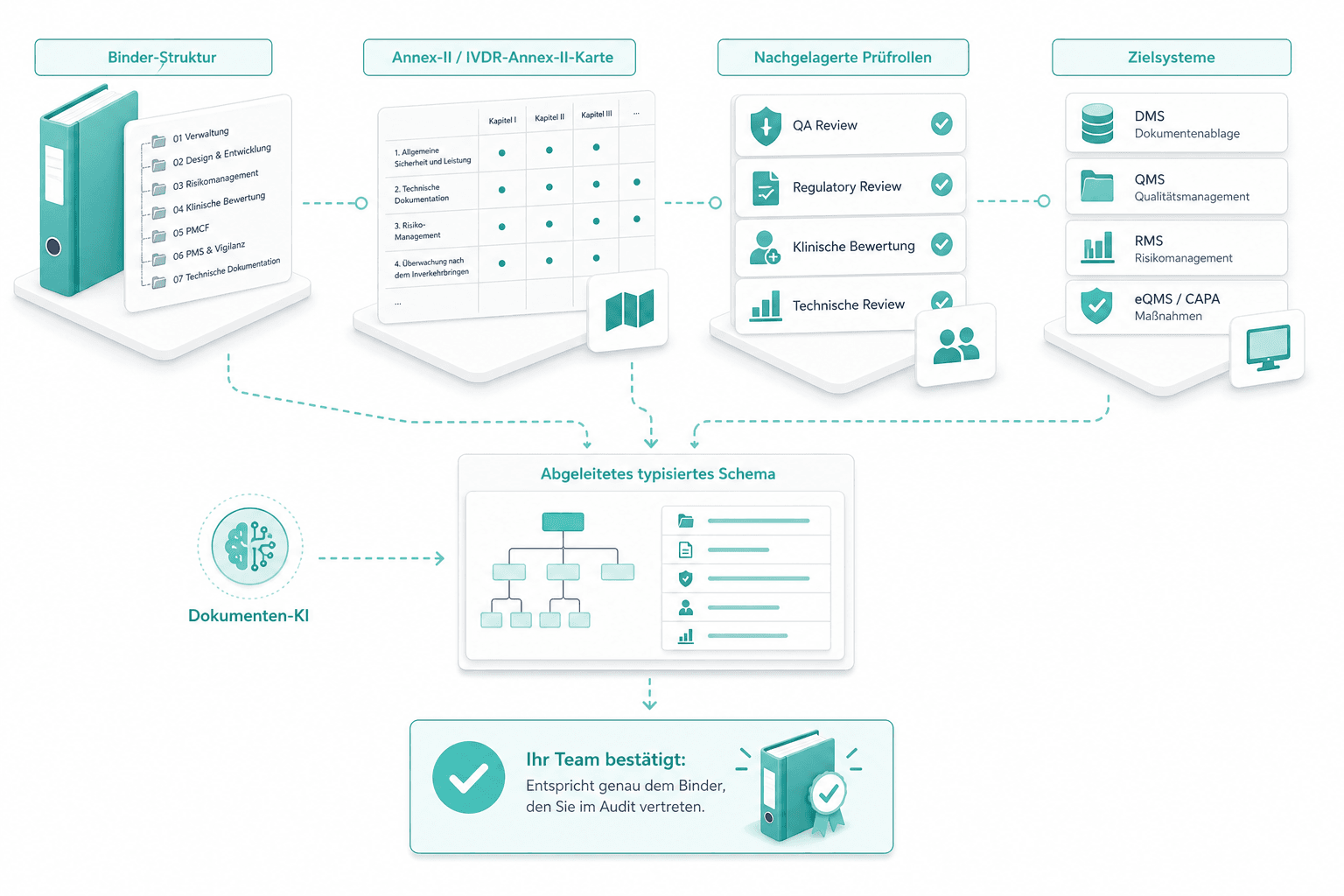
Pilot auf einer Dokumentenfamilie
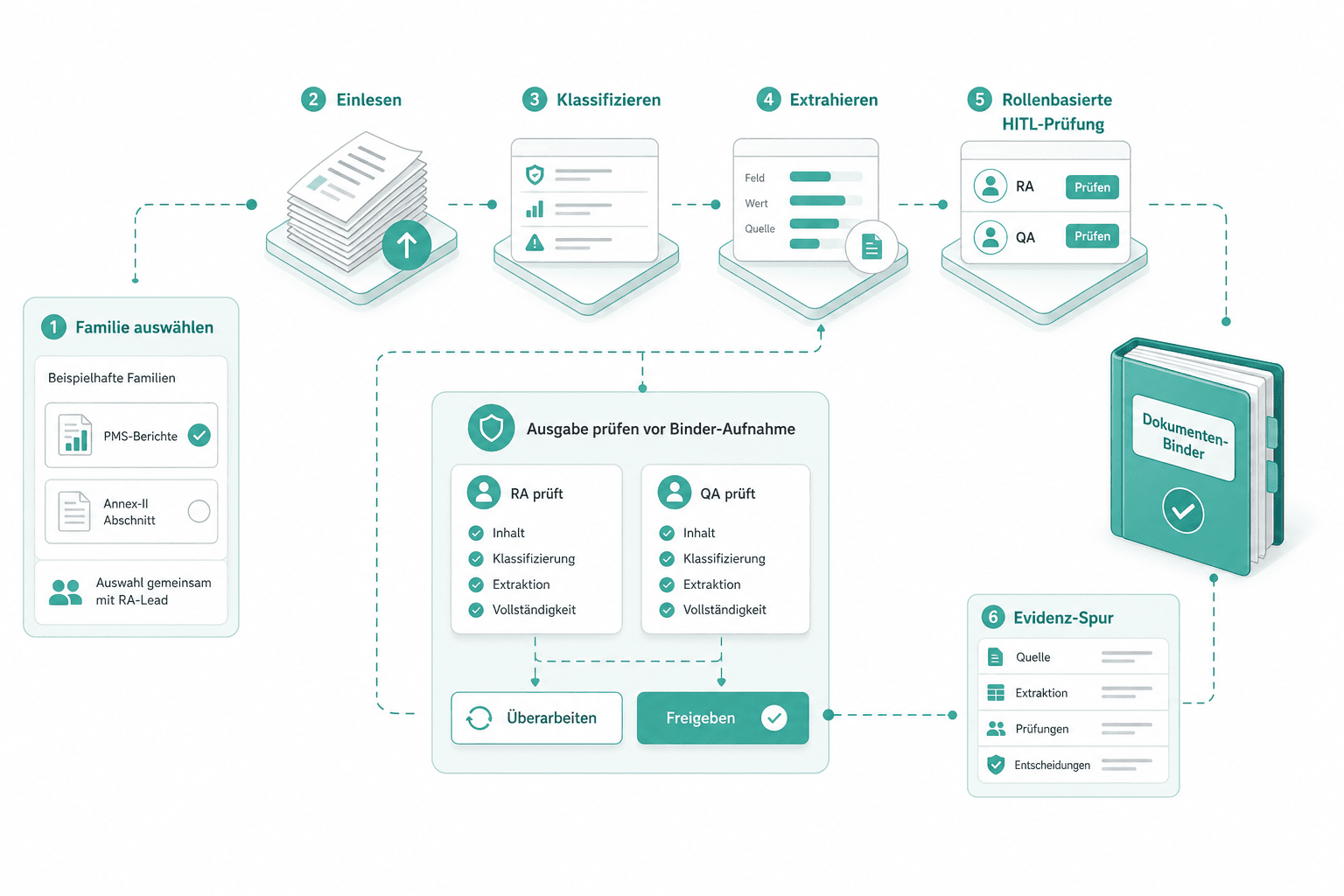
Wir waehlen mit Ihrem RA-Lead eine Familie — typischerweise PMS-Berichte oder ein Annex-II-Abschnitt. Die Engine laeuft durchgaengig auf echten Dokumenten: Einlesen, Klassifizieren, Extrahieren, rollenbasierte HITL-Pruefung, Evidenz-Spur. RA und QA pruefen jede Ausgabe vor Aufnahme in den Binder.
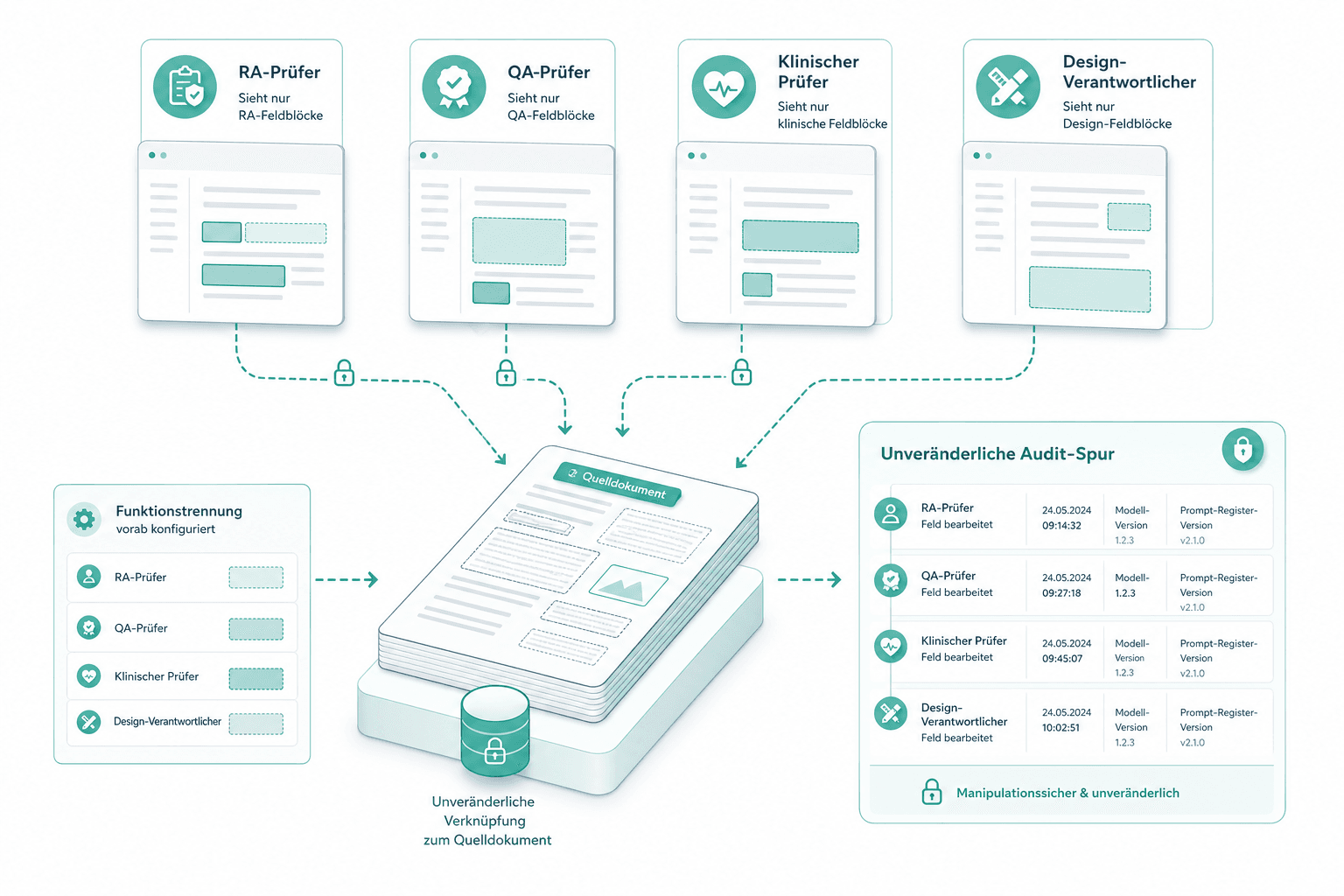
Rollenbasiertes HITL mit Audit-Spur
RA-Pruefer, QA-Pruefer, klinischer Pruefer und Design-Verantwortlicher sehen jeweils nur die Feldbloecke ihrer Verantwortung. Jede Bearbeitung, Rolle, Zeitstempel, Modell-Version und Prompt-Register-Version wird unveraenderlich gegen das Quelldokument protokolliert. Funktionstrennung wird vorab konfiguriert.
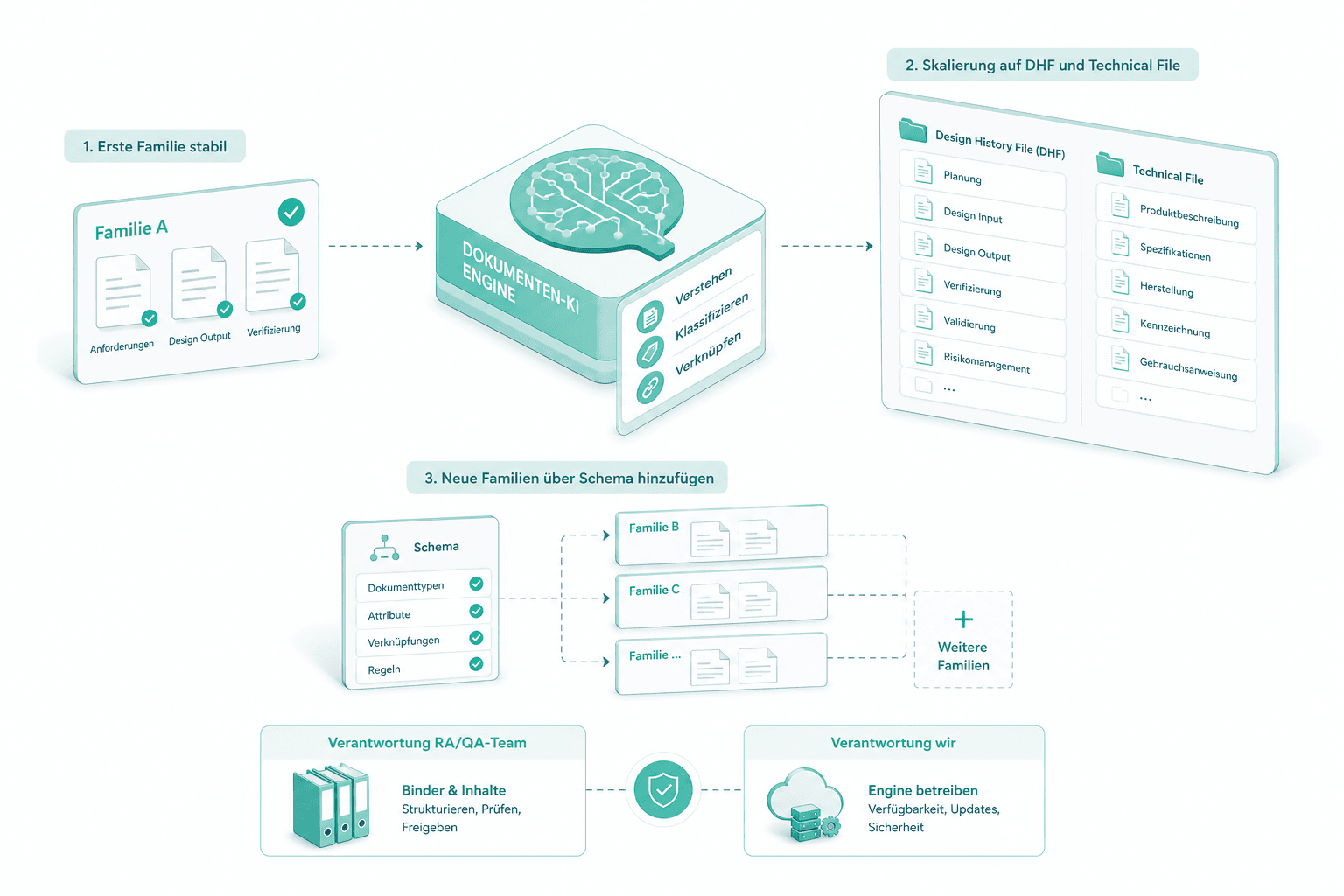
Skalierung auf DHF und Technical File
Sobald die erste Familie stabil laeuft, erweitern wir die Engine auf das gesamte Design History File und Technical File. Neue Familien kommen ueber das Schema dazu — kein neues Code-Release. Ihr RA/QA-Team verantwortet den Binder; wir betreiben die Engine.
Ihr RA-Lead fuehrt uns durch die Binder-Struktur, die Annex-II- bzw. IVDR-Annex-II-Karte, die nachgelagerten Pruefrollen und die Zielsysteme. Wir leiten das typisierte Schema ab; Ihr Team bestaetigt, dass es genau dem Binder entspricht, den Sie im Audit vertreten.
Wir waehlen mit Ihrem RA-Lead eine Familie — typischerweise PMS-Berichte oder ein Annex-II-Abschnitt. Die Engine laeuft durchgaengig auf echten Dokumenten: Einlesen, Klassifizieren, Extrahieren, rollenbasierte HITL-Pruefung, Evidenz-Spur. RA und QA pruefen jede Ausgabe vor Aufnahme in den Binder.
RA-Pruefer, QA-Pruefer, klinischer Pruefer und Design-Verantwortlicher sehen jeweils nur die Feldbloecke ihrer Verantwortung. Jede Bearbeitung, Rolle, Zeitstempel, Modell-Version und Prompt-Register-Version wird unveraenderlich gegen das Quelldokument protokolliert. Funktionstrennung wird vorab konfiguriert.
Sobald die erste Familie stabil laeuft, erweitern wir die Engine auf das gesamte Design History File und Technical File. Neue Familien kommen ueber das Schema dazu — kein neues Code-Release. Ihr RA/QA-Team verantwortet den Binder; wir betreiben die Engine.
Ausgewählte Projekte
SWISS INSURANCE POC (NDA)
POC zur Automatisierung von Versicherungsdokumenten

Wie SAPIENTROQ einen schema-getriebenen POC zur Automatisierung von Versicherungsdokumenten fur ein Schweizer Backoffice lieferte: Mistral OCR plus OpenAI JSON-Modus, Schemata live aus Admin-Konfiguration generiert, KI-Anbieter tauschbar hinter einer Schnittstelle.
Fall ansehen
Warum eine revisionssichere Engine hier zaehlt
Jede Entscheidung mit Modell- und Prompt-Version protokolliert
Wenn die Benannte Stelle oder das interne Audit fragt, warum ein Dokument so klassifiziert wurde, antwortet die Engine mit der Modell-ID, der zum Zeitpunkt aktiven Prompt-Register-Version, dem Pruefer und dem Zeitstempel. Die Evidenz wird nicht nachtraeglich rekonstruiert, sondern zum Entscheidungszeitpunkt erfasst und gegen das Quelldokument persistiert.
Reproduzierbare Inferenz zum Audit-Zeitpunkt
Jede Klassifikation oder Extraktion friert das Modell und den Prompt-Register-Eintrag ein, gegen den sie lief. Monate spaeter laesst sich dasselbe Dokument gegen denselben Snapshot erneut verarbeiten und liefert dieselbe Ausgabe. Reproduzierbarkeit ist Teil der Evidenz, kein separates Feature.
Rollenbasiertes HITL mit Funktionstrennung
RA, QA, Klinik und Design sehen jeweils nur die Feldbloecke ihrer Verantwortung. Der Pruefer, der ein Feld bearbeitet, ist nicht der Pruefer, der es freigibt. Funktionstrennung wird gegen das Rollenmodell konfiguriert, nicht nachtraeglich aufgepfropft.
Datenresidenz in CH oder EU, souveraener LLM-Pfad verfuegbar
Die Engine laeuft auf AWS Zuerich, in EU-Regionen oder in Ihrer eigenen Infrastruktur. Wo Inhalte kein oeffentliches Modell erreichen duerfen, fuehrt der Apertus-Pfad dieselbe Pipeline gegen ein in der Schweiz gehostetes Modell aus. Dokumenteninhalte bleiben in der Jurisdiktion, die Ihr Binder verlangt.
Was diese Engine nicht tut
Sie macht kein Produkt MDR- oder IVDR-konform. Sie ersetzt nicht die RA-Funktion, die QA-Funktion oder den klinischen Pruefer. Sie stellt SAPIENTROQ nicht als Benannte Stelle oder regulatorische Beratung dar. Sie unterstuetzt das Team, das diese Entscheidungen verantwortet.
Haeufig gestellte Fragen
Nein. Die regulatorische Konformitaet nach MDR (EU 2017/745) und IVDR (EU 2017/746) verantworten Ihr RA- und QA-Team, Ihre Benannte Stelle und Ihre Konformitaetsbewertung. Die Engine unterstuetzt Ihr Team bei Erstellung und Pflege der Dokumentation, die diese Entscheidungen stuetzt. Die regulatorische Beurteilung verbleibt bei den qualifizierten Personen.
Standardmaessig laeuft die Engine auf EU-Infrastruktur. Fuer CH-residente Binder deployen wir auf AWS Zuerich, on-prem beim Kunden oder in einer Schweizer Private Cloud. Wenn Inhalte kein oeffentliches Modell erreichen duerfen, fuehrt der Apertus-Pfad die Pipeline gegen ein in der Schweiz gehostetes Modell aus. Datenresidenz ist Teil der Deployment-Vorlage.
Jede Klassifikation oder Extraktion wird mit der Modell-ID, der zum Zeitpunkt aktiven Prompt-Register-Version, der Pruefer-Rolle, dem Benutzer und dem Zeitstempel protokolliert. Das Protokoll ist unveraenderlich und gegen das Quelldokument gebunden. Im Audit ist die Spur pro Dokument, pro Feld und pro Revision abfragbar — ohne nachtraegliche Rekonstruktion.
Wird ein revidiertes Annex-II-Dokument neu eingelesen, vergleicht die Engine es mit der Vorversion, zeigt die geaenderten Abschnitte und markiert jede verknuepfte nachgelagerte Datei zur Nachpruefung. Die Pruef-Warteschlange leitet die betroffenen Eintraege an die richtige Rolle. Aenderung und Nachpruefung gehen in die Evidenz-Spur ein.
Die Engine schreibt ueber API oder Document Repository in Ihr QMS hinein, nicht an dessen Stelle. Kategorien, Dokumenttypen und Feldbloecke werden im Discovery auf das QMS-Schema gemappt. Das QMS bleibt das System of Record; die Engine erstellt und pflegt die Dokumentation, die dort landet.
Der Extractor-Vertrag ist provider-tauschbar. Modell und Prompt-Register sind als Daten versioniert, nicht hart codiert. Prompt-Register, Kategorie- und Feldblock-Konfiguration, Rollendefinitionen und Betriebs-Runbook werden uebergeben. Die Pipeline laeuft auch ohne uns.
Kundendokumente fliessen nicht in geteilte Modelle. Wo ein gehostetes Modell genutzt wird, laeuft das Deployment ueber den No-Training-Endpunkt des Anbieters. Wo ein souveraener LLM erforderlich ist, laeuft Apertus auf Schweizer Infrastruktur unter Vertrag des Kunden. Der Datenpfad ist je Deployment dokumentiert.
Nein. SAPIENTROQ baut und betreibt die Dokumenten-KI-Engine. Wir interpretieren MDR oder IVDR nicht fuer Sie, wir vertreten Sie nicht gegenueber einer Benannten Stelle und wir zertifizieren Ihr Produkt nicht. Wo eine regulatorische Beratung noetig ist, arbeiten wir neben der von Ihnen gewaehlten Beratung.
Über SAPIENTROQ![]()
Sind Sie an einer Lösung interessiert?
Wir freuen uns, Ihnen die Möglichkeiten unverbindlich aufzuzeigen.

Roland Kurmann
CEO, SAPIENTROQ