Apertus Swiss LLM Deployment and Integration Partner

LoRA, QLoRA and full fine-tunes of Apertus on Swiss banking, insurance, treuhand and healthcare vocabulary. We design the evaluation set first and ship weights to your own Swiss cluster.
A sovereign Apertus document copilot for Swiss enterprises: chat with policies, contracts and internal knowledge through a Next.js application that cites every answer back to the source paragraph and stays fully inside Switzerland.
Move a production OpenAI or Anthropic integration onto Apertus, the Swiss open-weights LLM, without losing quality. Integration audit, eval-set rebuild, prompt rewrite, benchmark and staged cutover — by a Swiss team.
A paid 2-4 week Apertus evaluation POC that benchmarks the Swiss open-weights model on your real task set, side-by-side with the model you run today, and ends with a numbered go/no-go before any production commitment.
Run Apertus, the Swiss open-weights LLM, inside your own datacenter or a sovereign Swiss cloud. We size GPUs to your real prompt mix, install vLLM or TGI, wire monitoring into your stack, and stay on call through go-live.
Production retrieval-augmented generation against your SharePoint, Confluence, fileshare or DMS estate, with Apertus as generator. PostgreSQL with pgvector, per-user permission filter and a fresh-index pipeline.
Run Apertus inside Switzerland on Exoscale, Infomaniak or AWS Zurich, with a written data-residency contract that names the disks, the backups and the operators. Built for FINMA, cantonal and healthcare-bound clients.
Our Apertus tracks
Seven named tracks on one sovereign-LLM practice — pick the Apertus workload you have today, not a generic model evaluation deck. Hub starts at <a href="/services/ai-consulting">AI consulting</a> for discovery.
Apertus On-Prem Deployment
Apertus 8B or 70B served on customer GPUs — H100, A100 or L40S — with vLLM or TGI. Sovereign by default, no supplier-side US processing.
Apertus Fine-Tuning
Domain fine-tuning of Apertus on your Swiss-language corpus — banking, insurance, treuhand, healthcare or technical documentation. Typed evaluation harness, audit trail.
Apertus RAG Integration
Retrieval-augmented generation with Apertus on PostgreSQL plus pgvector. Source citations, chunk-level audit, role-scoped retrieval, no document leakage across tenants.
Document Q&A Copilot
Apertus-powered Q&A copilot over contracts, policies, regulatory filings or supplier datasheets. Answers grounded in your corpus with citations and a HITL fallback queue.
Migration from OpenAI or Anthropic
Move an existing GPT or Claude workload to Apertus without rebuilding the application. Prompt audit, regression harness, fallback gates and parallel-run period before cutover.
Evaluation and Paid POC
Two-to-four week paid Apertus POC against your real task set. Typed evaluation, side-by-side with the incumbent model, go or no-go gate before any production build.
Swiss Data-Sovereignty Hosting
Apertus hosted on Exoscale, Infomaniak, AWS Zurich or fully on-prem — chosen against your data class, FINMA or cantonal regime, and throughput target.
How we deliver an Apertus engagement
From a sovereign-LLM intent to a running Apertus deployment in five steps. The position we hold during scope: Swiss buyers don't reject OpenAI for taste. They reject it because the regulator, the cantonal data officer or the board's IT subcommittee will not sign off on supplier-side US processing. Apertus is the first open model good enough that rejecting OpenAI doesn't cost you the workload.
Selected Apertus engagements
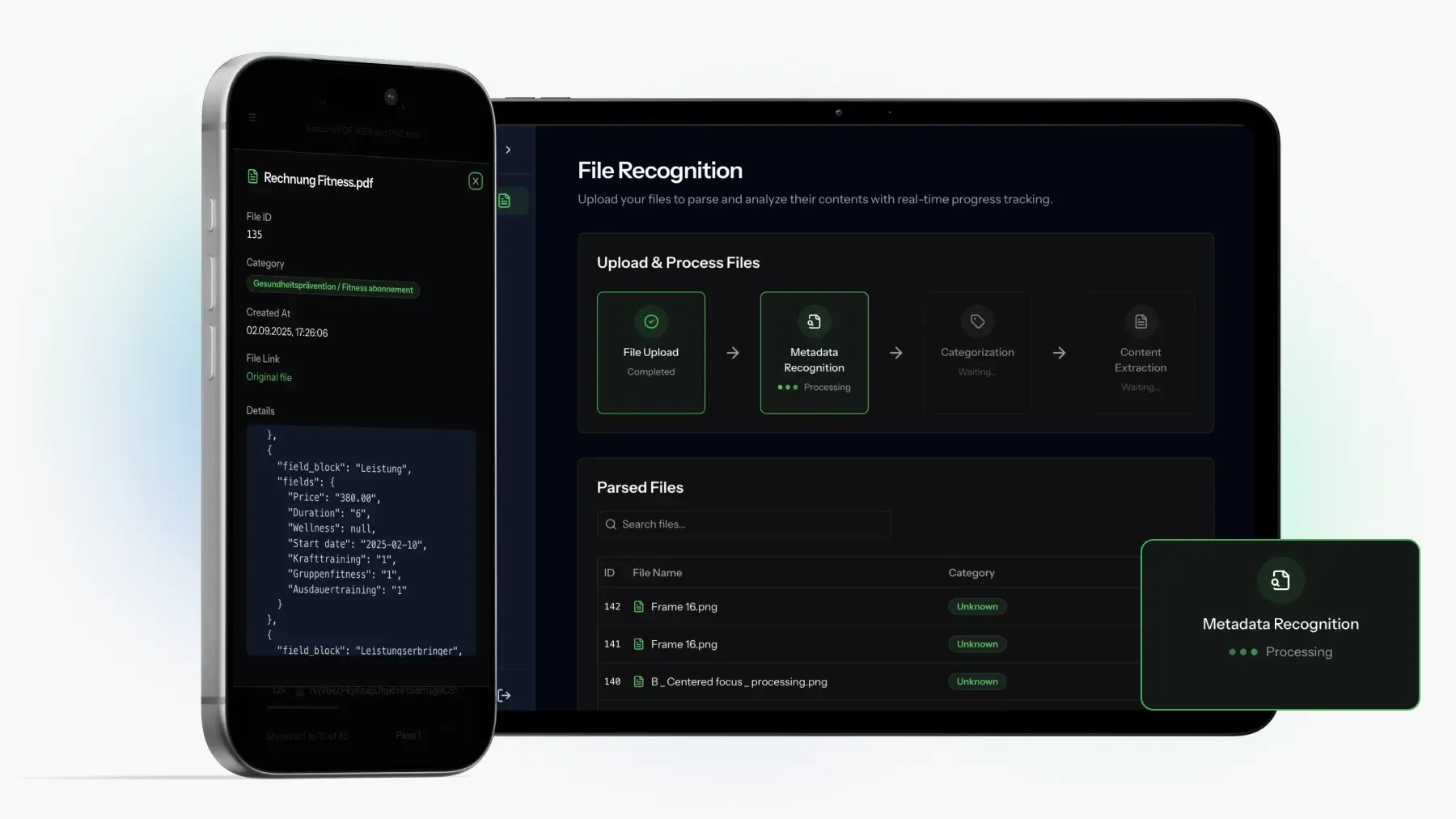
SWISS INSURANCE POC
Insurance Document Automation POC for a Swiss Back OfficeHow SAPIENTROQ built a schema-driven insurance document automation POC for a Swiss back office: Mistral OCR plus OpenAI JSON-mode extraction, schemas generated live from admin-defined categories, with provider-swappable AI behind a single interface.
Technology stack
Apertus 8B or 70B on vLLM or TGI as the serving layer, Hugging Face transformers for tooling, llama.cpp for the edge cases. Application spine on Laravel and Next.js, PostgreSQL with pgvector for RAG, Redis and BullMQ for queueing, Mastra when multi-agent orchestration applies. Swiss hosting on Exoscale, Infomaniak, AWS Zurich or on-prem.
What clients say
Frequently Asked Questions
Apertus is the open-weights LLM family released in late 2025 by the Swiss AI Initiative — EPFL, ETH Zurich and CSCS Lugano — under Apache 2.0. It ships in 8B and 70B sizes with explicit Swiss German, French, Italian and Romansh coverage and frontier-class quality.
We deploy Apertus on standard GPU infrastructure — H100, A100 or L40S — using vLLM or TGI for serving. Hosting sits on Exoscale, Infomaniak, AWS Zurich or fully on-prem inside the client estate. Hybrid splits are common: RAG in CH cloud, inference on customer GPUs.
Apertus wins when supplier-side US processing is blocked by the regulator, the cantonal data officer or the board. It also wins on Swiss German handling. GPT-4o or Claude still lead on broad English reasoning. Our paid POC measures the gap on your real tasks first.
The shape is Discovery, POC, Production. A two-to-four week discovery scopes workload, data residency and integration surface. A paid two-to-four week POC runs Apertus against your real task set with a go or no-go gate. Production follows only if the POC benchmarks pass.
Hosting in practice covers Exoscale (CH), Infomaniak (CH) and AWS Zurich for regional cloud, plus on-prem inside the client estate for FINMA, cantonal or healthcare-bound workloads. The choice depends on data class, regulator regime and throughput — scoped during discovery.
We host Apertus in the same stack we use for doc-AI and PIM tracks: Laravel and Next.js as application spine, PostgreSQL with pgvector for RAG retrieval, Redis and BullMQ for queueing, Mastra orchestration when multi-agent flows apply. Existing apps integrate via typed APIs.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ