AI Document Automation for Swiss Enterprises

Intelligent document processing for Swiss back office, productized. We sort your PDFs, scans and emails into your taxonomy and push extracted data into your ERP, PIM or case management. Same IDP Switzerland engine running at Weita and Sanitas.
Productized OCR software for Swiss back office. Two-pass Mistral OCR turns scans, photos and mixed-quality PDFs into clean text and structured zones — ready to feed your downstream extraction and ERP/PIM systems.
AI document automation for Swiss HR and payroll back-office. Payslips, contracts, work certificates, sick notes, AHV/IV statements and expense receipts classified and extracted into your HRIS — with role-scoped HITL for HR and payroll.
A custom digital personnel file for Swiss employers. One structured file per employee, role-scoped access for HR, supervisors and external Treuhand, full audit trail and OR-compliant retention — replacing paper cabinets, scattered network drives and HRIS document tabs that nobody trusts.
Audit-grade document AI for Swiss MedTech manufacturers. Supports your RA and QA team in preparing and maintaining MDR and IVDR technical files, PMS reports and clinical evaluation binders. Your team owns the regulatory call.
Document AI for Swiss insurers and banks operating under FINMA supervision. Claims documents, KYC/AML packets, policy schedules and intermediary contracts processed with role-scoped HITL, an immutable audit trail and Swiss data residency.
A document AI layer for Swiss Treuhand firms. Client receipts, invoices, bank statements and payroll attachments arrive via WeTransfer, e-mail or shared drive — we classify, extract and prepare them for Bexio, Abacus or Sage.
Document data extraction for Swiss back office, productized. PDFs, forms and scans become typed JSON against the schema your ERP, PIM or case-management already expects — with field-level confidence and role-gated HITL on the fields that need it.
Our document automation capabilities
One engine, four production capabilities — intelligent document automation as configurable layers, not as separate products, plugged into your existing systems.
Classification & field extraction
Sort incoming documents into your taxonomy and extract typed fields against a schema, not free-form text.
Structured data extraction
OpenAI JSON-mode extraction against a typed schema, with field-level confidence and HITL fall-through.
Two-pass OCR for difficult scans
Mistral OCR with a raw + structured pass — handles handwriting, low-quality scans, and mixed-language documents.
Workflow & ERP integration
Document workflow automation as a typed state machine, role-scoped editing, and direct write-out to ERP, PIM or case-management.
Industries we serve
We deliver where Swiss enterprises have real document pain — not generic enterprise slideware. The engine runs in production on a 200,000+ SKU catalogue with document workflow automation at the core.
HR & payroll documents
Personnel files, contracts, payroll attachments — classified, extracted, and routed into your HRIS.
Healthcare (MDR/IVDR)
Regulatory document handling for medtech and life-science teams under MDR and IVDR obligations.
Finance (FINMA-supervised)
Document workflows for FINMA-supervised institutions with full audit trail and role-scoped review.
Treuhand & accounting
Receipts, invoices, and accounting documents extracted into Bexio, Abacus, or your custom ledger.
How a rollout actually runs
From discovery call to a first production deployment in six steps. Three are paid discovery; three are build, integration and hardening against your real documents — not a sandbox demo.
Cases running on this engine
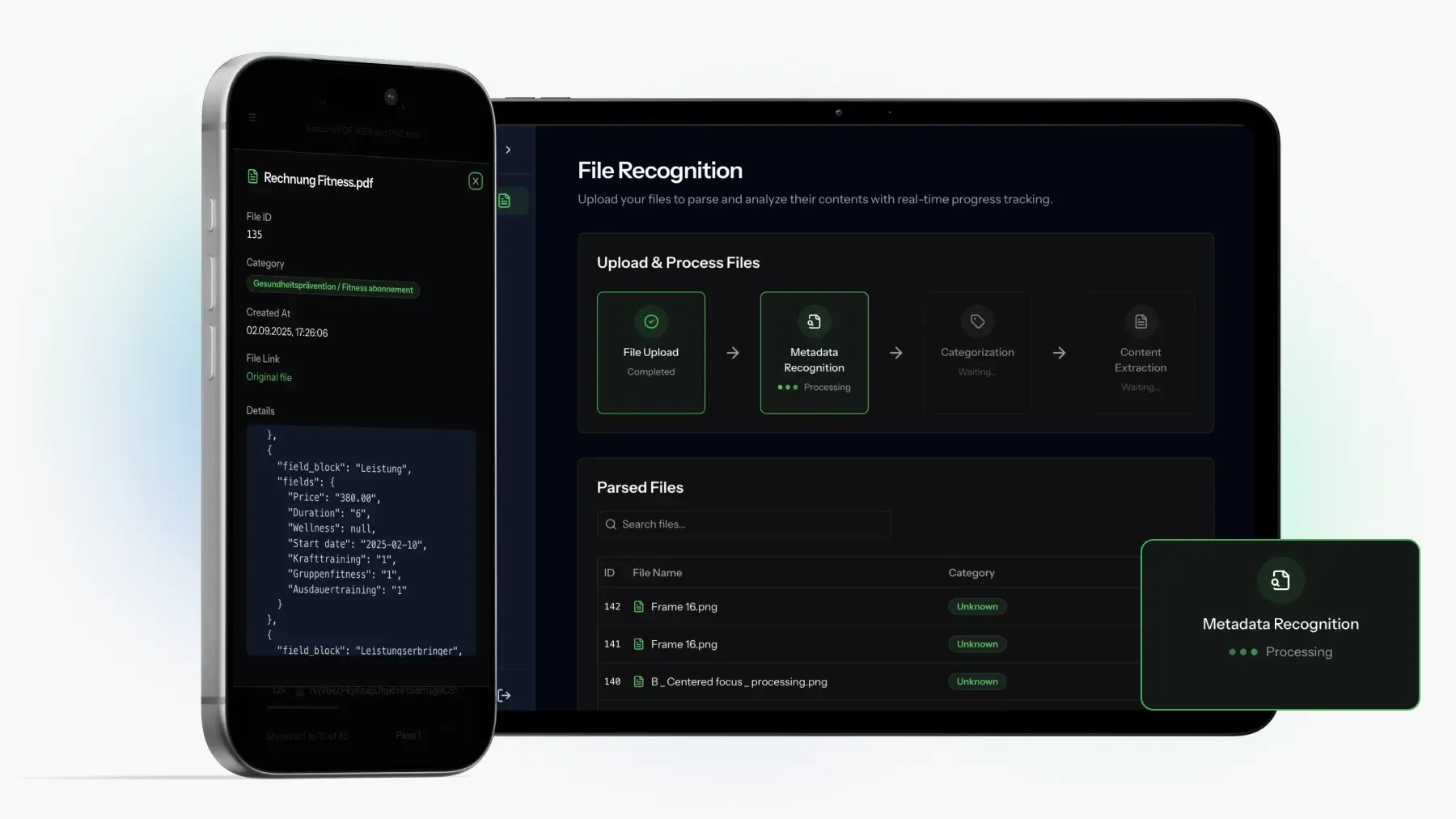
SWISS INSURANCE POC
Insurance Document Automation POC for a Swiss Back OfficeHow SAPIENTROQ built a schema-driven insurance document automation POC for a Swiss back office: Mistral OCR plus OpenAI JSON-mode extraction, schemas generated live from admin-defined categories, with provider-swappable AI behind a single interface.
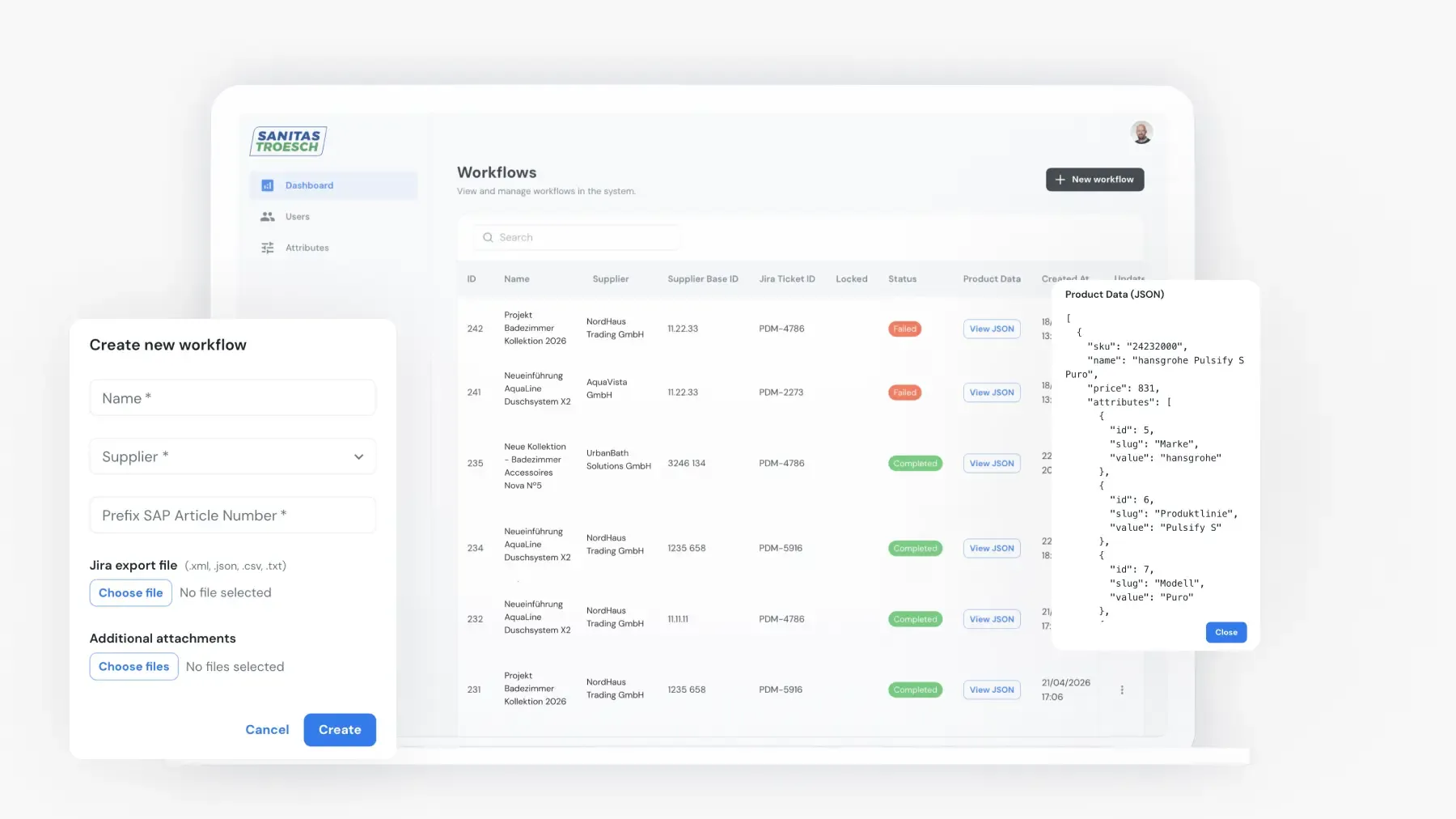
SANITAS TROESCH
PIM Implementation with HITL AI for Sanitas TroeschHow SAPIENTROQ delivered a PIM implementation with a multi-agent HITL pipeline that ingests 200k+ supplier SKUs from PDFs, Excel and Jira into the Sanitas Troesch PIM with audit-grade governance.
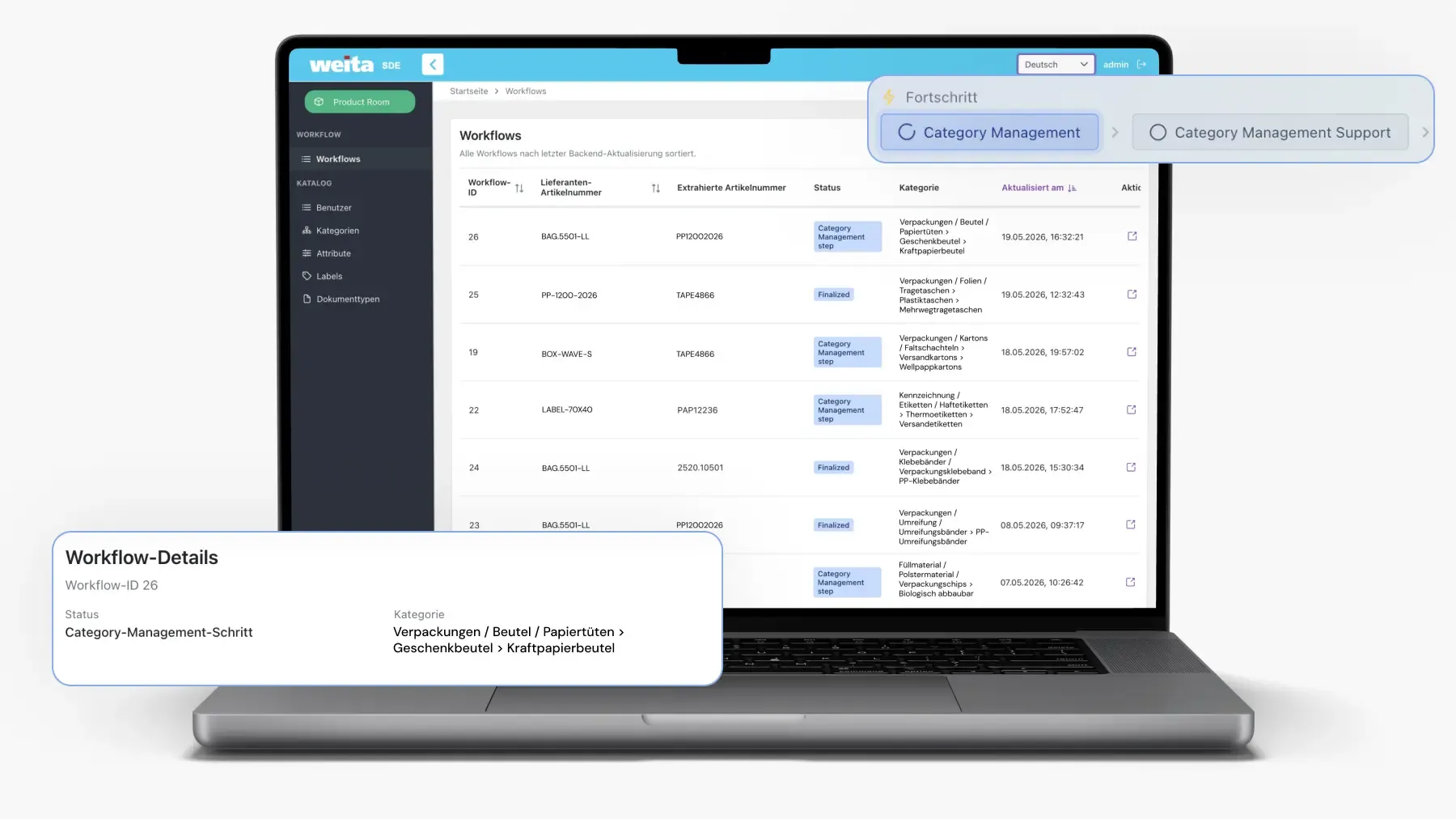
WEITA AG
Weita Supplier Onboarding Workflow: Wholesale Digital TransformationHow SAPIENTROQ built a Laravel and Next.js workflow that turns PDFs, emails, images and spreadsheets into compliant PIM products for Weita AG, with Mistral OCR, OpenAI JSON-mode extraction and a database-backed prompt registry.
Tech stack
We use “boring” boring application technology (Laravel and Next.js) for the application parts and the most modern LLM technology where applicable. We host your data in CH.
What clients say
Frequently Asked Questions
Several approaches exist. OCR turns images of text into text. Rule-based capture matches hand-built templates. Intelligent Document Processing (IDP) — what we build — adds taxonomy classification and typed-schema extraction on top, end-to-end.
One pipeline handles PDFs, scanned paper, image attachments, emails with PDF/Word/Excel/image enclosures, Jira tickets and spreadsheets. It classifies each document, extracts typed values, and writes to your ERP, PIM or case-management system.
The engine writes directly into your system of record. We model the end-to-end workflow as a typed state machine, hook into your API, and ship to a Laravel modular monolith, a separate admin panel, or a staged-queue pipeline — three live deployments today.
Each production deployment ships with a Human-in-the-Loop (HITL) editing surface. Suppliers see their own records, pipeline admins see the full set, others see a role-scoped subset. Every field-level edit is audited and tied to the source record and user.
Highest ROI: insurance back-office, treuhand and accounting, healthcare back-office, HR personnel files, supplier onboarding for distributors, and PIM. High document volume, stable taxonomies, and a downstream system already in place to receive the extracted data.
Swiss data residency runs on AWS Zurich or your own infrastructure. Rule of thumb: 8–14 weeks to a first production milestone — 2–3 weeks paid discovery, 6–8 weeks build, ~4 weeks hardening on real traffic. Final quote comes out of discovery.
The architecture is model-pluggable: hosted OpenAI, local Mistral, or Apertus on Swiss-hosted servers for hard data-sovereignty requirements. See the Apertus Swiss LLM hub for the full on-premise path.
About SAPIENTROQ![]()
Interested in a solution?
We are glad to show you various options without any obligation.

Roland Kurmann
CEO, SAPIENTROQ